Recurrent Neural Networks
Series temporelles et language
Plan
- Pourquoi les RNN ?
- RNN : principe et fonctionnement interne
- Séries temporelles
- LSTM et GRU : comprendre les portes pas à pas
- Ateliers pratiques
Ce qui nous mènera ensuite aux transformers.
Des CNN aux RNN — le problème
Les CNN sont très efficaces pour les données spatiales (images). Mais ils ont une limite fondamentale :
ils n'ont pas de mémoire.
Un CNN traite chaque entrée de manière indépendante. Il ne sait pas ce qui s'est passé avant.
Or beaucoup de données du monde réel sont séquentielles, l'ordre compte :
- une phrase ("le chat mange la souris" ≠ "la souris mange le chat")
- un cours de bourse (la valeur d'aujourd'hui dépend d'hier)
- un signal audio (les sons s'enchaînent dans le temps)
Le problème : comment donner de la mémoire à un réseau de neurones ?
La solution : les Recurrent Neural Networks (RNN)
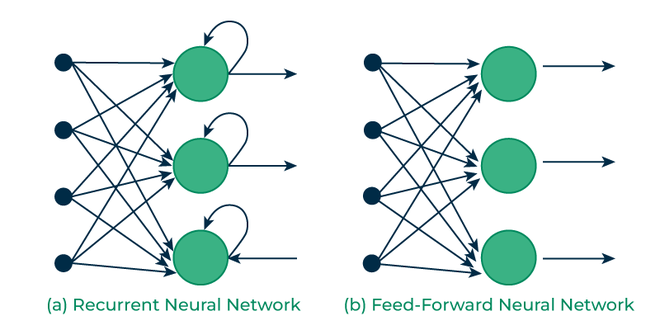
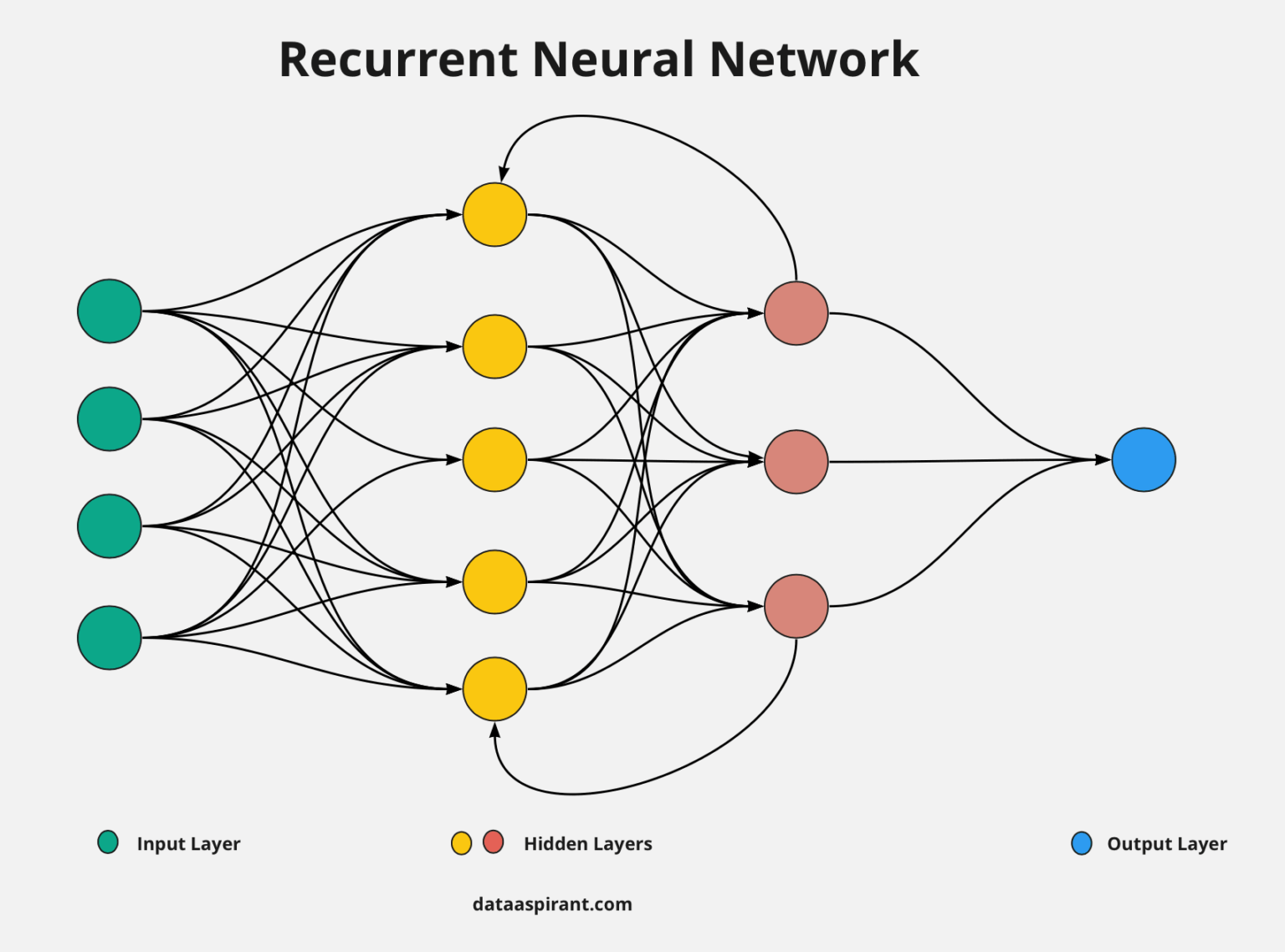
RNN — Définition
sequences de réseaux feed forward ou la sortie d'un FF est réinjectée dans le réseaux suivant
Recurrent Neural Networks : enchaîner les couches pour utiliser la sortie de la couche N-1 comme entrée de la couche N avec en plus un nouvel échantillon.
 >
>
- Conçu pour traiter des données séquentielles
- Le RNN a une mémoire et peut modéliser des dépendances temporelles
- On utilise les mêmes poids pour toutes les cellules (weight sharing)
- À chaque cellule on ajoute l'échantillon suivant dans la séquence de données
RNN — Ce qui se passe dans une cellule
À chaque pas de temps t, la cellule RNN fait un calcul simple :
h(t) = tanh( W · h(t-1) + U · x(t) + b )
Où :
- x(t) : l'entrée au temps t (ex : le mot courant, la valeur du jour)
- h(t-1) : l'état caché précédent (la "mémoire" du réseau)
- W : poids appliqués à la mémoire (les mêmes à chaque pas de temps)
- U : poids appliqués à l'entrée
- b : biais
- tanh : fonction d'activation qui compresse la sortie entre -1 et +1
Exemple concret : imaginons un RNN qui lit une phrase mot par mot.
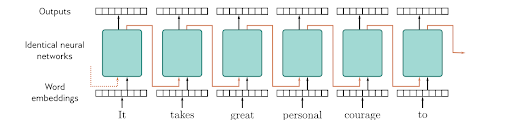
| Temps | Entrée x(t) | Le réseau combine... | État caché h(t) |
|---|---|---|---|
| t=1 | "le" | "le" + état initial (zéros) | mémoire de "le" |
| t=2 | "chat" | "chat" + mémoire de "le" | mémoire de "le chat" |
| t=3 | "mange" | "mange" + mémoire de "le chat" | mémoire de "le chat mange" |
À chaque étape, le réseau accumule du contexte. C'est sa mémoire.
Representation dépliée vs en un bloc
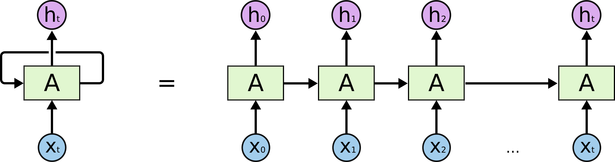
En fait on a un seul réseau récurrent avec des poids partagés à chaque pas de temps.
RNN — Applications
- Language Modelling and Generating Text
- Speech Recognition
- Machine Translation
- Time series Forecasting
CNN + RNN — Applications combinées
Les CNN extraient des features spatiales, les RNN modélisent la séquence temporelle.
note: le RNN a été entraîné sur des correspondances (image, description) (ex: dataset COCO avec 300k+ images annotées)
- Image Captioning — CNN encode l'image → RNN génère une description mot par mot
- Visual Question Answering — CNN analyse l'image, RNN traite la question et produit la réponse
- Video Classification — CNN extrait les features de chaque frame → RNN capture la dynamique temporelle
- Action Recognition — CNN détecte les poses/objets → RNN reconnaît l'enchaînement des mouvements
- OCR sur documents — CNN détecte les caractères → RNN reconstruit les mots en séquence
CNN + RNN — Étendre le champ de vision
Un filtre CNN ne voit qu'une petite zone de l'image (3x3, 5x5...). Même en empilant des couches, le champ réceptif reste limité.
En ajoutant un RNN après les couches convolutives, on balaye les feature maps (ligne par ligne, colonne par colonne) et chaque position accumule du contexte sur ce qui précède → un pixel peut "savoir" ce qui se passe à l'autre bout de l'image.
Exemple : en segmentation sémantique, pour savoir si un pixel est du "ciel" ou un "mur bleu", il faut du contexte global (y a-t-il un sol en bas ? des arbres ?). Le CNN seul voit trop local, le RNN propage ce contexte spatial.
Cette approche a été largement remplacée par les mécanismes d'attention (transformers de vision), qui capturent le contexte global sans balayage séquentiel.
RNN — Avantages et inconvénients
Avantages :
- Un RNN se souvient de chaque information au fil du temps. Il est utile pour la prédiction de séries temporelles grâce à sa capacité à se souvenir des entrées précédentes.
- Les réseaux de neurones récurrents peuvent être utilisés avec des couches convolutives pour étendre le voisinage effectif des pixels.
Inconvénients :
- Problèmes de vanishing gradient et exploding gradient (plus la séquence est longue, plus le gradient se dégrade).
- L'entraînement d'un RNN est une tâche difficile.
- Pas efficace pour de très longues séquences.
RNN — En résumé
Les RNN sont puissants pour capturer des relations séquentielles complexes dans les données, mais ils peuvent être difficiles à entraîner et souffrent de problèmes comme l'explosion ou la disparition du gradient.
Les variantes comme les LSTM et les GRU ont été développées pour atténuer ces problèmes et améliorer les performances sur des tâches séquentielles complexes.
Depuis 2024, pour tout ce qui est audio et NLP, les RNNs ont été remplacés par les Transformers.
waaaay back in 2015!
Un article très populaire à l'époque sur l'efficacité des RNNs :
The Unreasonable Effectiveness of Recurrent Neural Networks https://karpathy.github.io/2015/05/21/rnn-effectiveness/
"The concept of attention is the most interesting recent architectural innovation in neural networks."
Séries temporelles
Qu'est-ce qu'une série temporelle ?
Une ou plusieurs variables évoluant dans le temps : prix, quotation, température, humidité.
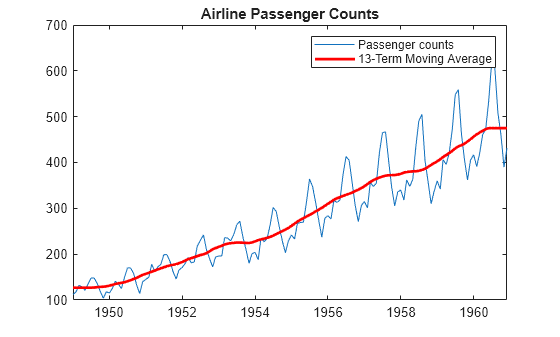
Exemple : Air Passengers (1949-1960)
Ce dataset classique montre le nombre mensuel de passagers aériens internationaux. On y observe clairement :
- une tendance : le trafic augmente au fil des années
- une saisonnalité : pic chaque été, creux chaque hiver
- un résidu : les variations non expliquées par la tendance et la saisonnalité
C'est exactement le type de données que les RNN savent modéliser : une structure temporelle avec des patterns qui se répètent et évoluent.
Dataset : https://www.kaggle.com/datasets/rakannimer/air-passengers
Datasets de séries temporelles
- Air Passenger Dataset : https://www.kaggle.com/datasets/rakannimer/air-passengers
- Sunspots Dataset : https://www.kaggle.com/datasets/robervalt/sunspots
- Electricity Consumption Dataset : https://www.kaggle.com/datasets/robikscube/hourly-energy-consumption
- Stock Market Dataset : https://www.kaggle.com/datasets/ehallmar/daily-historical-stock-prices-1970-2018
- Weather Data : https://www.kaggle.com/datasets/noaa/gsod
- Sales Data : https://www.kaggle.com/datasets/csafrit2/grocery-sales-data
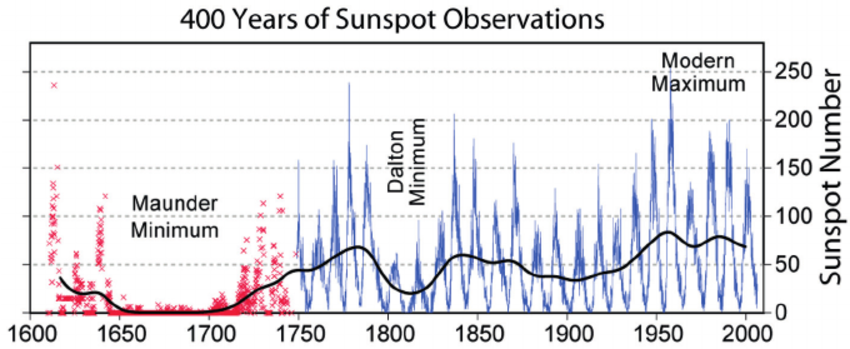
Spécificités de la prédiction des séries temporelles
- Train/test split : la séparation des sets de train et test doit respecter la temporalité des données. Pas de shuffling aléatoire.
- Évaluation de la performance : on utilise RMSE ou MAE, soit des métriques de régression.
- Rendre la série plus stationnaire en considérant son auto-différence d'écart 1 ou 2.
Approches standard de prédiction
- Tests statistiques de stationnarité
- Modélisation ARIMA, AR, MA, ARMA, …
- Exponential Smoothing Models — Holt Winters
- Décomposition : tendance, saisonnalité et résidu
- Machine learning classique : XGBoost, …
- Facebook Prophet
- Deep learning : RNN
Décomposition : tendance, saisonnalité et résidu
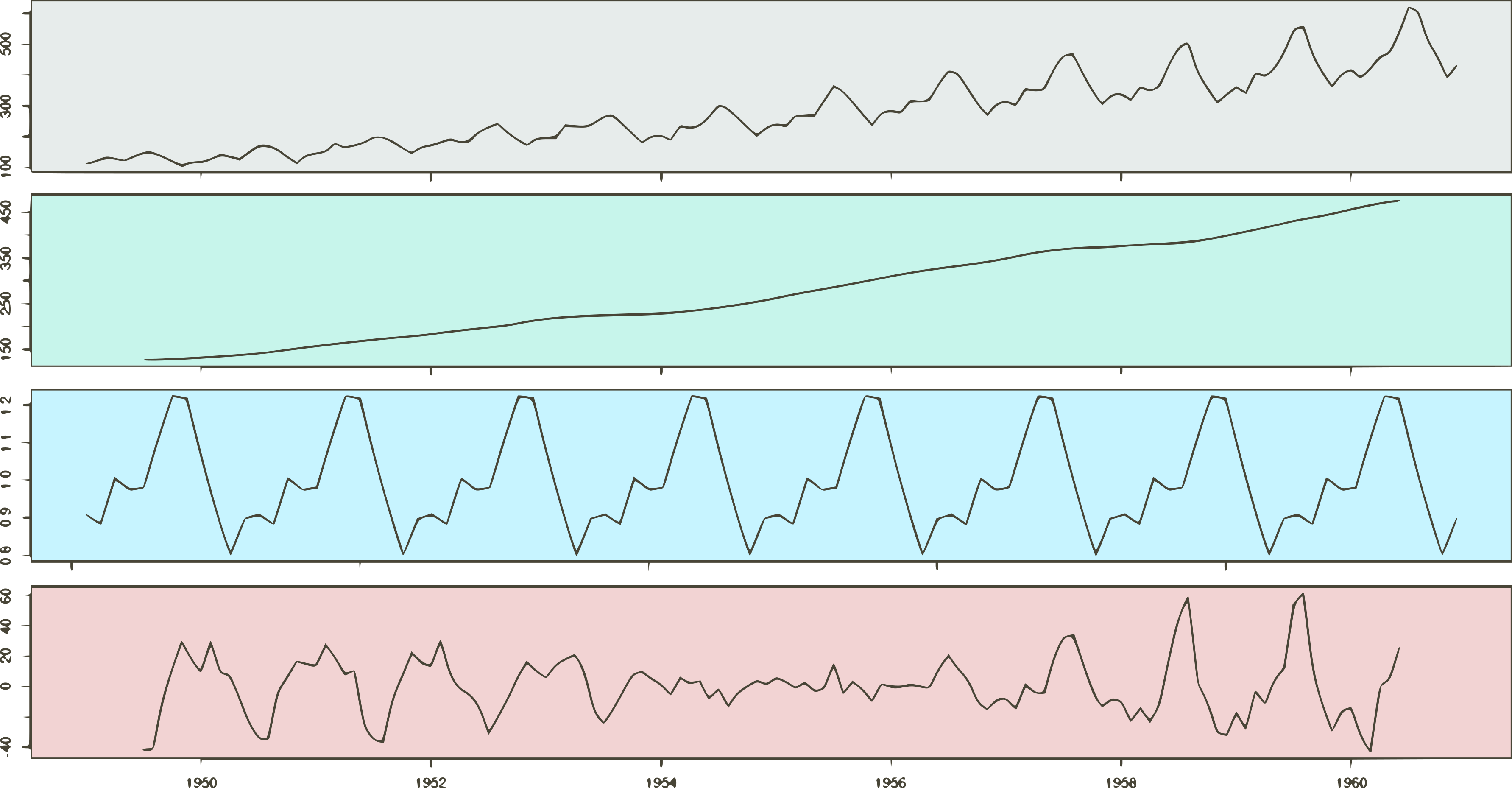
Réf : https://sthalles.github.io/a-visual-guide-to-time-series-decomposition/
RNN avec TensorFlow — Keras
Réf : https://keras.io/api/layers/recurrent_layers/
Les couches RNN de Keras se regroupent en 3 catégories :
- Couches de base — SimpleRNN
- Couches avancées — LSTM, GRU
- Wrappers — Bidirectional, TimeDistributed, ConvLSTM — des couches qui enveloppent une couche RNN pour modifier son comportement (direction, application temporelle, ou ajout de convolution)
Couche de base : SimpleRNN
La brique fondamentale. Un seul état caché h(t), pas de mécanisme de mémoire long terme.
model.add(keras.layers.SimpleRNN(units=64, activation='tanh'))
- units : nombre de neurones (dimension de l'état caché)
- return_sequences=True : renvoie la sortie à chaque pas de temps (utile pour empiler des couches RNN)
- return_sequences=False (défaut) : renvoie uniquement la sortie du dernier pas de temps
Limité par le vanishing gradient → ne fonctionne pas bien sur les longues séquences.
Couches avancées : LSTM
Long Short-Term Memory — résout le vanishing gradient grâce à un cell state et 3 portes (forget, input, output).
model.add(keras.layers.LSTM(units=128, return_sequences=True, dropout=0.2))
- Mêmes paramètres que SimpleRNN + contrôle du dropout récurrent (
recurrent_dropout) - Mémorise des dépendances sur des centaines de pas de temps
- Plus lent à entraîner que SimpleRNN (4x plus de paramètres)
Couches avancées : GRU
Gated Recurrent Unit — version simplifiée du LSTM. 2 portes au lieu de 3, pas de cell state séparé.
model.add(keras.layers.GRU(units=128, return_sequences=True))
- Plus rapide que LSTM (3x paramètres au lieu de 4x vs SimpleRNN)
- Performances souvent comparables au LSTM sur des séquences moyennes
- À privilégier quand on veut un bon compromis vitesse/performance
Wrappers : Bidirectional
Traite la séquence dans les deux sens (passé → futur et futur → passé), puis concatène les sorties.
model.add(keras.layers.Bidirectional(keras.layers.LSTM(64)))
Utile quand le contexte futur compte (NLP, speech). Inutile pour la prédiction de séries temporelles (on ne connaît pas le futur).
Wrappers : TimeDistributed
Applique une même couche (ex: Dense) indépendamment à chaque pas de temps.
model.add(keras.layers.TimeDistributed(keras.layers.Dense(10)))
Utile quand on veut une sortie à chaque pas de temps (sequence-to-sequence) : traduction, tagging, segmentation temporelle.
Couches spécialisées : ConvLSTM
Combine convolution + LSTM dans une seule couche. L'entrée est une séquence de grilles spatiales (vidéo, météo, etc.).
model.add(keras.layers.ConvLSTM2D(filters=32, kernel_size=(3, 3)))
- ConvLSTM1D : séquences 1D spatiales (séries temporelles multi-capteurs)
- ConvLSTM2D : séquences d'images (prédiction vidéo, radar météo)
- ConvLSTM3D : séquences de volumes 3D (imagerie médicale temporelle)
LSTM et GRU
Le problème du RNN simple
On l'a vu : le RNN simple souffre du vanishing gradient sur les longues séquences.
Concrètement, dans la phrase :
"J'ai grandi en France, j'ai voyagé dans de nombreux pays, j'ai appris plusieurs langues et je parle couramment le ..."
Le RNN doit se souvenir de "France" (très loin en arrière) pour prédire "français". Mais les gradients se dégradent à chaque pas de temps et l'information de "France" a disparu quand on arrive à la fin.
La solution : il faut un mécanisme qui permette à l'information de circuler sur de longues distances sans se dégrader.
C'est exactement ce que font les LSTM.
LSTM — L'intuition
Long Short-Term Memory : le nom semble contradictoire, mais il résume bien l'idée :
- Long Term : capacité à mémoriser des informations sur de longues séquences
- Short Term : capacité à apprendre et oublier des informations à court terme selon les besoins
L'idée clé :
- ajouter un chemin direct (le cell state) par lequel l'information peut circuler à travers toute la séquence, - protégée par des portes (gates) qui contrôlent ce qui entre, ce qui sort, et ce qu'on oublie.
LSTM — Le cell state : l'autoroute de l'information
Le cell state (Ct) est le cœur de l'architecture LSTM. C'est ce qui différencie fondamentalement un LSTM d'un RNN simple.
On peut le voir comme une autoroute qui traverse toute la séquence. L'information circule dessus de manière linéaire (additions et multiplications), sans passer par des fonctions d'activation qui écraseraient le gradient.
Pourquoi ça résout le vanishing gradient :
- Dans un RNN simple, l'information passe à travers des tanh à chaque pas de temps → le gradient se multiplie par des valeurs < 1 → il disparaît.
- Dans un LSTM, le cell state permet au gradient de circuler directement sans dégradation → l'information peut survivre sur des centaines de pas de temps.
Les portes (gates) sont les bretelles d'accès à cette autoroute. Elles décident quelle information monte sur l'autoroute, laquelle en sort, et laquelle est évacuée.
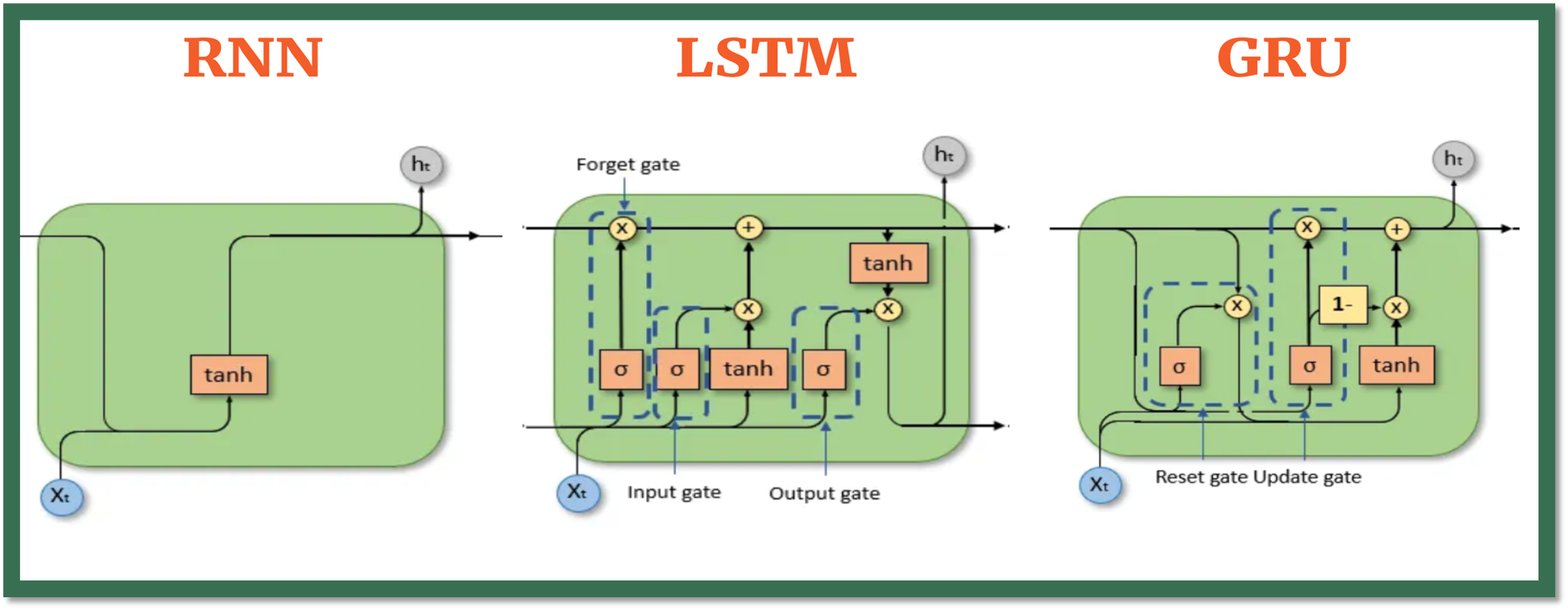
LSTM : Cell state + Gates
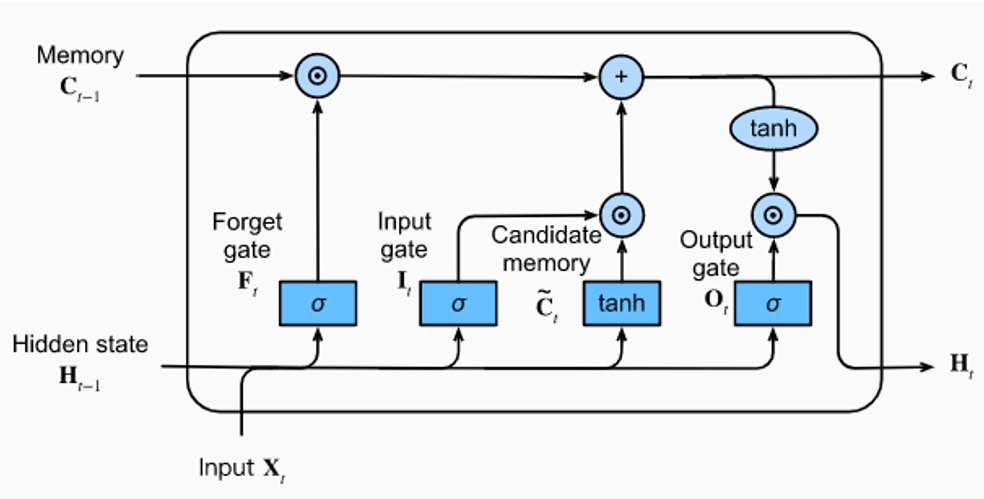
Le Cell State
- Le cell state est la ligne horizontale du haut, de C(t-1) à C(t).
- L'information circule de manière quasi-linéaire : seulement une multiplication (⊙) et une addition (+) sur ce chemin.
- Aucune fonction d'activation (sigmoid, tanh) ne compresse le signal sur cette ligne — c'est pour cela que le gradient ne disparaît pas sur les longues séquences.
La Forget Gate (F_t) — "que doit-on oublier ?"
- La forget gate prend en entrée X_t (l'entrée courante) et H(t-1) (le hidden state précédent).
- Elle applique une fonction sigmoid qui produit des valeurs entre 0 et 1 pour chaque élément du cell state.
- Une valeur proche de 0 signifie "oublie cette information", une valeur proche de 1 signifie "conserve-la".
- Le résultat est multiplié (⊙) avec le cell state C(t-1) : c'est le nettoyage de la mémoire avant d'y écrire de nouvelles choses.
L'Input Gate (I_t) — "que doit-on mémoriser ?"
- L'input gate contrôle ce qui entre dans le cell state.
- Un sigmoid (σ) filtre quelles informations sont suffisamment importantes pour être mémorisées.
- En parallèle, la Candidate Memory (C̃_t) propose de nouvelles valeurs candidates via une fonction tanh (valeurs entre -1 et +1).
- Le produit des deux (⊙) donne les nouvelles informations effectivement ajoutées (+) au cell state.
La Candidate Memory (C̃_t) — "quelles sont les nouvelles informations disponibles ?"
- La candidate memory est le contenu brut proposé pour mise à jour du cell state.
- Elle est calculée par une fonction tanh appliquée à X_t et H(t-1).
- Elle ne décide pas si l'information est mémorisée — c'est l'input gate qui fait ce tri.
- On peut la voir comme un brouillon que l'input gate valide ou rejette.
L'Output Gate (O_t) — "que doit-on communiquer ?"
- L'output gate contrôle ce qui sort de la cellule pour être transmis à la cellule suivante.
- Un sigmoid (σ) filtre quelles parties du cell state sont pertinentes pour la sortie.
- Ce filtre est multiplié (⊙) par tanh(C_t) — le cell state compressé entre -1 et +1.
- Le résultat est H_t, le hidden state : c'est à la fois la sortie de la cellule et l'entrée de la cellule suivante.
- L'output gate ne révèle pas tout ce que la cellule sait, seulement ce qui est pertinent à cet instant.
Où est le réseau de neurones dans ce diagramme ?
- Les 4 blocs bleus (σ, σ, tanh, σ) sont chacun un petit réseau de neurones à part entière.
- Chacun prend les mêmes entrées (X_t et H(t-1)), mais possède ses propres poids entraînables.
- Ce sont des couches Dense classiques suivies d'une fonction d'activation (sigmoid ou tanh).
- Une cellule LSTM contient donc 4 réseaux de neurones qui travaillent en parallèle — c'est pour cela qu'elle a environ 4 fois plus de paramètres qu'une cellule RNN simple.
LSTM — Les 3 portes, pas à pas
Prenons une analogie : le LSTM est un étudiant qui prend des notes pendant un cours.
1. Forget Gate (Porte d'oubli) — "Qu'est-ce que je raye de mes notes ?"
Entrée : x(t) et h(t-1) → fonction sigmoid → valeurs entre 0 et 1
- Proche de 0 → on oublie cette information
- Proche de 1 → on la conserve
Exemple : le sujet du cours change → on "oublie" les informations du chapitre précédent qui ne sont plus pertinentes.
2. Input Gate (Porte d'entrée) — "Qu'est-ce que je note ?"
Deux opérations en parallèle :
- sigmoid : décide quelles informations mettre à jour (filtre)
- tanh : crée un vecteur de nouvelles valeurs candidates
Le produit des deux donne ce qui sera effectivement ajouté au cell state.
Exemple : le prof dit quelque chose d'important → on décide de le noter.
3. Output Gate (Porte de sortie) — "Qu'est-ce que je dis si on me pose une question ?"
Entrée : x(t) et h(t-1) → sigmoid → multipliée par tanh(cell state)
On ne révèle pas tout ce qu'on sait, seulement ce qui est pertinent pour la question posée.
Exemple : on nous demande la date d'un événement → on extrait cette info de nos notes sans tout réciter.
LSTM — Mise à jour du cell state
Le cell state est mis à jour en deux temps :
Étape 1 — Oublier : on multiplie l'ancien cell state par la sortie de la Forget Gate.
C(t) = f(t) × C(t-1)
Ce qui doit être oublié est mis à zéro.
Étape 2 — Ajouter : on ajoute les nouvelles informations filtrées par l'Input Gate.
C(t) = f(t) × C(t-1) + i(t) × C̃(t)
Où C̃(t) est la mémoire candidate (sortie du tanh).
Le hidden state (sortie de la cellule) est ensuite calculé :
h(t) = o(t) × tanh(C(t))
C'est ce hidden state qui est transmis à la cellule suivante et utilisé pour la prédiction.
LSTM — Récapitulatif des composants
| Composant | Rôle | Fonction d'activation |
|---|---|---|
| Forget Gate (f) | Décide quoi oublier du cell state | sigmoid (0 à 1) |
| Input Gate (i) | Décide quoi ajouter au cell state | sigmoid (filtre) + tanh (candidates) |
| Output Gate (o) | Décide quoi exposer en sortie | sigmoid |
| Cell state (C) | Mémoire à long terme (l'autoroute) | mis à jour linéairement |
| Hidden state (h) | Sortie de la cellule / mémoire court terme | tanh |
Variantes : GRU
Gated Recurrent Units (GRU) : une version simplifiée du LSTM. L'idée est la même (des portes pour contrôler le flux d'information), mais avec une architecture plus légère.
Simplification principale : la GRU fusionne le cell state et le hidden state en un seul vecteur, et combine les portes Forget et Input en une seule Update Gate.
Deux portes seulement :
- Update Gate (z) : détermine quelle part de l'état caché précédent conserver vs remplacer. C'est l'équivalent combiné des Forget et Input Gates du LSTM.
- Reset Gate (r) : contrôle quelle part de l'état caché précédent prendre en compte pour calculer le nouvel état candidat.
LSTM ou GRU — Comment choisir ?
| Critère | LSTM | GRU |
|---|---|---|
| Complexité du problème | Meilleur pour les séquences longues et les dépendances à long terme | Plus efficace pour les problèmes plus simples et les dépendances plus courtes |
| Ressources informatiques | Nécessite plus de ressources et de mémoire | Moins de paramètres, plus efficace computationnellement |
| Quantité de données | Performant avec de grandes quantités de données | Bon résultat avec des ensembles de données plus petits |
| Vitesse d'entraînement | Entraînement plus long | Plus rapide à entraîner |
En pratique : commencer par GRU (plus rapide à itérer), puis passer à LSTM si les performances ne sont pas suffisantes.
Ateliers
Atelier 1 — RNN simple : prédiction de série temporelle
Construction de RNNs de prédiction de séries temporelles sur le dataset SunSpot
https://github.com/SkatAI/deeplearning/blob/master/notebooks/RNN_hands_on_claude_sunspots.ipynb
Atelier 2 — Autres datasets et expérimentations
Appliquer les modèles RNN/LSTM/GRU sur d'autres datasets :
- Sunspots : https://www.christianhaller.me/blog/projectblog/2020-07-30-Sunspot-Activity-Time-Series/
- Weather data (beaucoup de manipulation des data) : https://colab.research.google.com/drive/1hkVoGLVuN0yC6hT6SI6mhk6miCIt7yIK#scrollTo=RBgR95ufJs35
- https://machinelearningmastery.com/time-series-prediction-lstm-recurrent-neural-networks-python-keras/
- https://machinelearningmastery.com/time-series-forecasting-long-short-term-memory-network-python/