L'Intelligence Artificielle ?
Promesses
Beaucoup de promesses d'efficacité de gain de temps.
En réalité, on obtient un mélange de savonette et de fadeur et avec aussi des expériences bluffantes.
Notion de jagged frontier : frontière irrégulière.
- l'IA trébuche sur certaines taches évidentes pour un humain
- mais dépasse les humains dans des domaines d'excellence
Par exemple ce matin, je demande a Mistral de compter le nombre de r dans le mot strawberry :

En insistant on finit par voir la bonne réponse

Evolution de l'IA
Ethan Mollick prof à Wharton
utilise le même prompt depuis 2021:
Une loutre dans un avion qui utilise le wifi
Historique de l'IA Générative
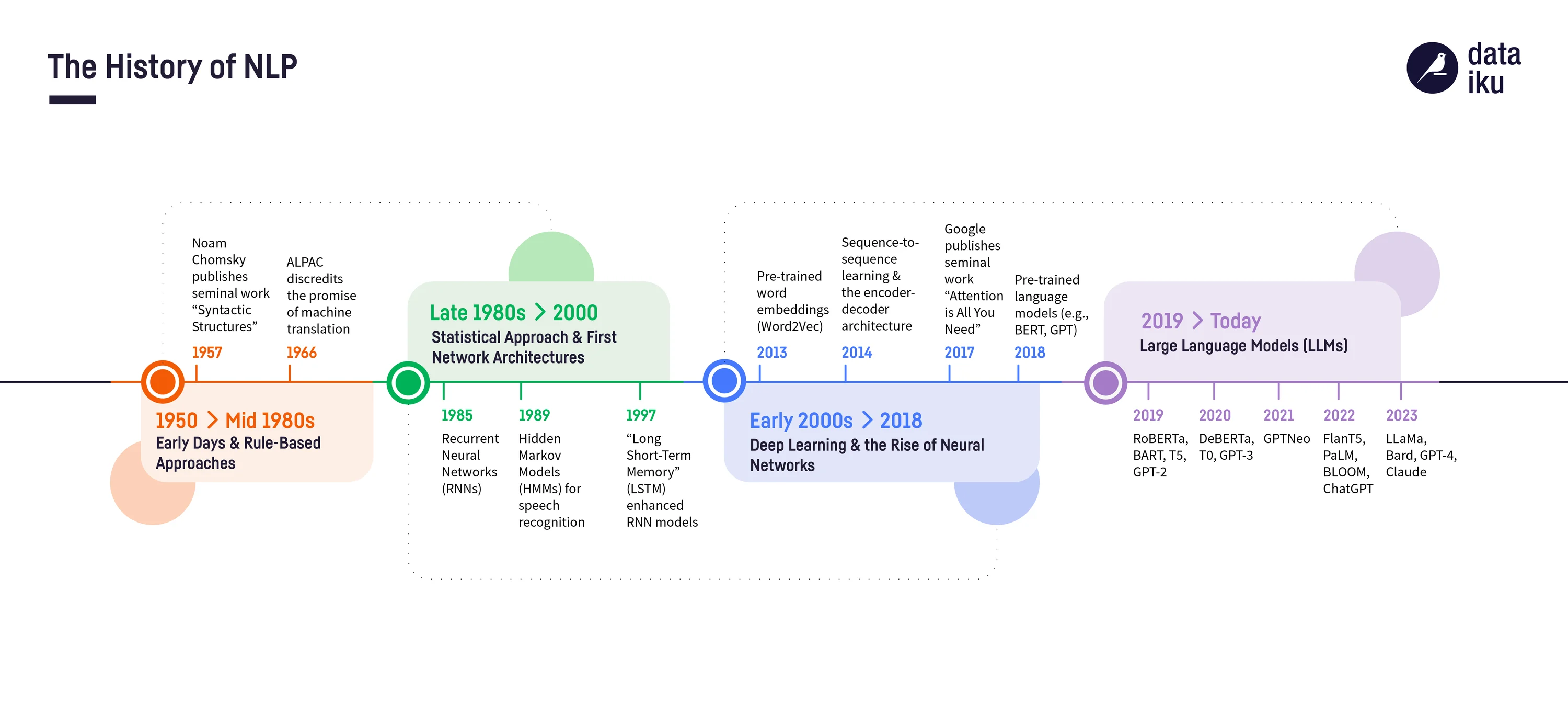
Les ancètres
Nuit des temps
- Ferdinand de Saussure : Cours de linguistique générale, publié en 1916
- Noam Chomsky : Syntactic Structures (1957)
- Emile Benveniste : Problèmes de linguistique générale (recueil, 1966)
Google translate
- Google Translate a été lancé le 28 avril 2006.
Avant 2013 : NLP classique (Natural Language Processing)
- Approches symboliques et statistiques
- N-grams, TF-IDF
- Modèles de langage probabilistes
La renaissance
2013 - Word2Vec (Google)
- Embeddings vectoriels pour les mots
- Capture des relations sémantiques
2014 - Seq2Seq et Attention
- Sequence-to-Sequence models pour la traduction
- Premiers mécanismes d'attention
2017 - Transformers ("Attention Is All You Need")
- Architecture de deep learning / reseaux de neurones
2018 - BERT (Google) - 1er LLM
- Bidirectional Encoder Representations
- Compréhension du contexte bidirectionnel
Les précurseurs
2018 - GPT-1 (OpenAI)
- 117M paramètres
- Démonstration du transfer learning
2019 - GPT-2 (OpenAI)
- 1.5B paramètres
- "Too dangerous to release" (initialement)
- Génération de texte cohérente
2020 - GPT-3 (OpenAI)
- 175B paramètres
- Few-shot learning
- Capacités émergentes
L'ère des grands modèles
2021 - DALL-E (OpenAI)
- Text-to-image generation
- 12B paramètres
2022 - ChatGPT (OpenAI)
- Lancement public (novembre)
- RLHF (Reinforcement Learning from Human Feedback)
- Adoption massive grand public
2022 - Stable Diffusion
- Open source text-to-image
- Diffusion models démocratisés
2023 - GPT-4 (OpenAI)
- Multimodal (texte + images)
- Capacités de raisonnement améliorées
2023 - LLaMA (Meta)
- Open source LLM
- Différentes tailles (7B à 65B)
- un modele open source parmi tant d'autres
2023 - Claude (Anthropic)
- Focus sur la sécurité et l'alignement
2024-25
- Modèles multimodaux avancés
- agents
- ingenierie
2026 - ...
- autres types de modèles IA (Yan Lecunn)
NLP classique
Le langage est... compliqué
Homonymie
- Je vais acheter un livre.
- Il pèse dix livres.
- Il livre des colis toute la journée.
- Mangeons , grand-père.
- Mangeons grand-père.
- Poser un lapin
- Je ne sais pas si je ne viendrai pas
- I'm bad (Michael Jackson)
- Septante, acronymes, ...
Le langage est... compliqué
- Longueur variable
- Grande variété de complexité selon les langues
- Allemand :
Donaudampfschiffahrtsgesellschaftskapitän(5 "mots") - Chinois : 50 000 caractères différents (2-3k pour lire un journal)
- Langues slaves : Formes de mots différentes selon le genre, le cas, le temps
- Allemand :
- Encodage : unicode vs Ascii
- Données non structurées
- code switching
- idiomes, argot générationnel, slang
NLP classique
- Text mining
- NER : Named Entity Recognition : LOC, PER,
- POS : Part of Speech Tagging : noms, adjectifs, verbes, ...
- Classification : analyse de sentiment, spam, hate speech, ...
- Identification de topic, topic modeling
- WSD : word sense disambiguation : bank, fly
- STT : speech to text, text to speech
et des tâches plus difficiles telles que
- Traduction automatique, résumé, question answering
NLP classique
- déterministe (non probabiliste - LLMs)
- basé sur la décomposition du texte en éléments identifiables : mots, rôles grammaticaux, entités, etc.
- appliqué aux phrases, syntagmes nominaux, mots
- inclut des méthodes de pré-traitement du texte brut pour faciliter le traitement
- stop words : et, le, de, etc.
- stemming : universités, universel, univers -> univer (le sens est souvent perdu)
- lemmatization : cours, courir, couru -> courir (plus efficace que le stemming)
- subword tokenization : "malheureux" → ["mal", "heur", "eux"]
Nécessite des modèles, des règles qui sont spécifiques à chaque langue. Le russe ou le français ont besoin de lemmatizers différents de l'anglais.
Tokenization
Quelle est l'unité du texte ?
On pourrait travailler avec
- des mots, syllabes, tokens, lettres et ponctuation
- des Bigrams, n-grams : New York, cul-de-sac, pain au chocolat
- des syntagmes nominaux : groupe de mots qui fonctionne comme un nom : le gros chien brun avec des taches
- des phrases, paragraphes, tweets, articles, livres, commentaires
- un Corpus : un ensemble complet de textes
Il faut gérer
- Le vocabulaire est large / infini et change rapidement
- Les fautes de frappe, orthographes multiples
- les formes de mots : pluriel, déclinaison (maison, foyer), conjugaison, etc.
Démo NLP classique : NER et POS
https://cloud.google.com/natural-language
Entrez du texte :
"Like everyone, we have definitely felt the impact of AI Overviews. There is only one direction of travel; not only are AIs getting better, but they're getting better in an exponential fashion," said Sean Cornwell, chief executive of Immediate Media, which owns the Radio Times and Good Food brands in the UK.
POS : part of speech et dependency tagging
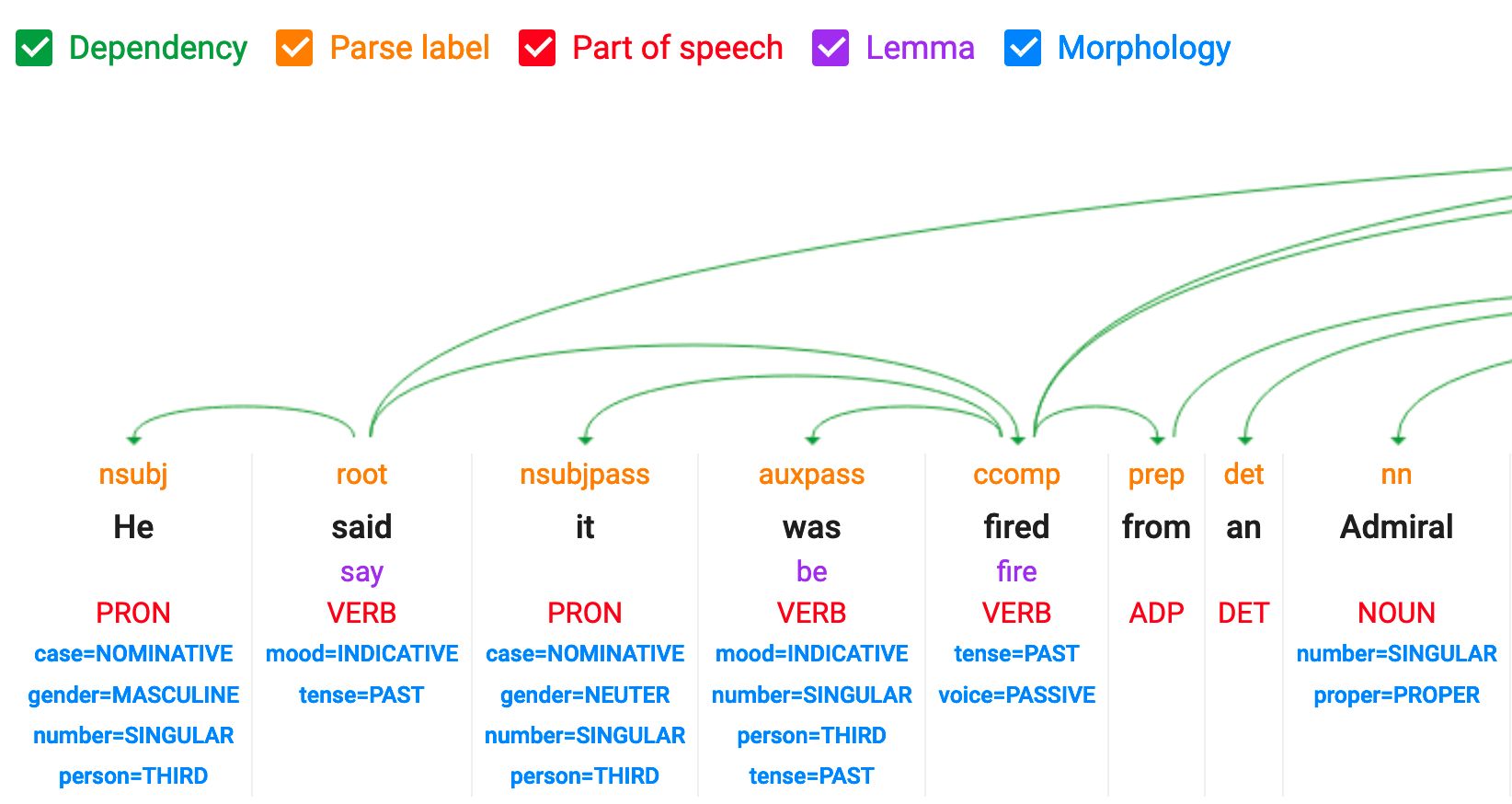
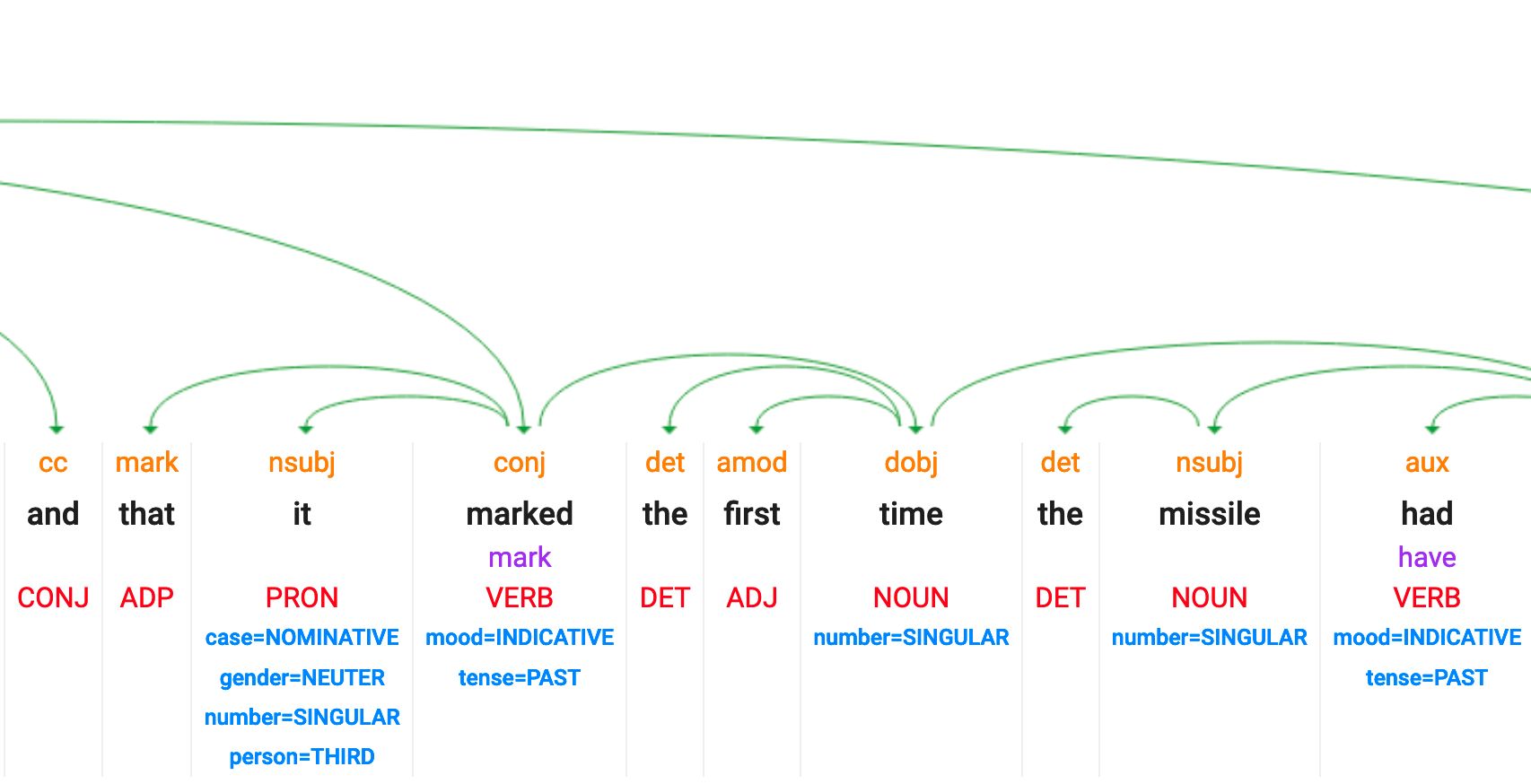
Malheureusement, cette fonctionnalité n'est plus disponible dans la démo NLP de Google.
Tokens et LLMs
- Context Window = mesuré en tokens, pas en mots : fenêtre de 1M tokens, fenêtre de 200k tokens, ...
- Pricing Model = coût par token (entrée + sortie)
- Texte non-anglais = plus de tokens nécessaires
- Token Limits = pourquoi les réponses sont coupées
- Tâches au niveau des caractères = difficiles (les LLMs voient des tokens, pas des lettres)
- L'efficacité varie = selon la langue, le domaine, la complexité
Tarification basée sur les tokens
https://openai.com/api/pricing/

NLP moderne (post 2013)
voir ces slides
LLMs
Large Language Models
Grands modèles de langage
Tokens, temperature
génération de texte :
- prediction du prochain token suivant une distribution de probabilité
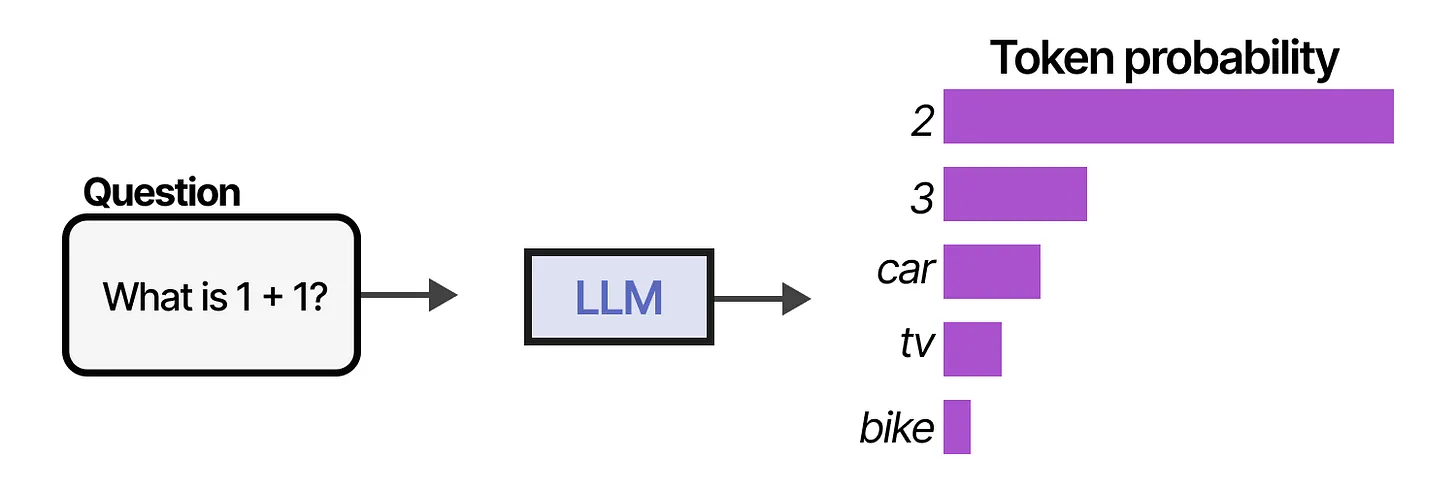
Autre exemple
Hier soir j'ai mangé:
- de la pizza
- des broccoli
- des huitres
- un camion
fenêtre de contexte et tokens:
- 1 token ≈ 0.75 mot, 1 page ~200 à 300 mots,
- 1M tokens = 1.3 Guerre et Paix
mais si le contenu est trop grand, le LLM aura tendance
- à oublier les instructions importantes
- à se concentrer sur les derniers tokens
Donc garder le contexte petit est important.
C'est une bonne stratégie pour être efficace.
Température :
Le paramètre qui permet de changer la distribution de probabilité des tokens
Les mots moins fréquents ont une probabilité plus grande de être générés quand la température est élevée.
Quand on augmente la temperature :
- plus ou moins de créativité
- plus ou moins d'hallucinations
temperature = 0ne veut pas dire déterminisme
Donc
-
un LLM a une mémoire limité
-
un LLM fait des réponses aléatoires
Pourquoi les tokens
- décomposition à peu près syllabique
- meilleure façon de compléter / prédire la suite d'un texte;
- pas de mots inconnus (OOV)
- vocabulaire de volume fini et de taille limitée,
- robuste vis à vis des erreurs de frappes, des formes des mots : conjugaisons, déclinaisons, accords etc
- le nombre de token dicte les coûts des requêtes vers les API.
- variation de prix par langue : Français plus cher que Anglais (x1.2)
token based pricing
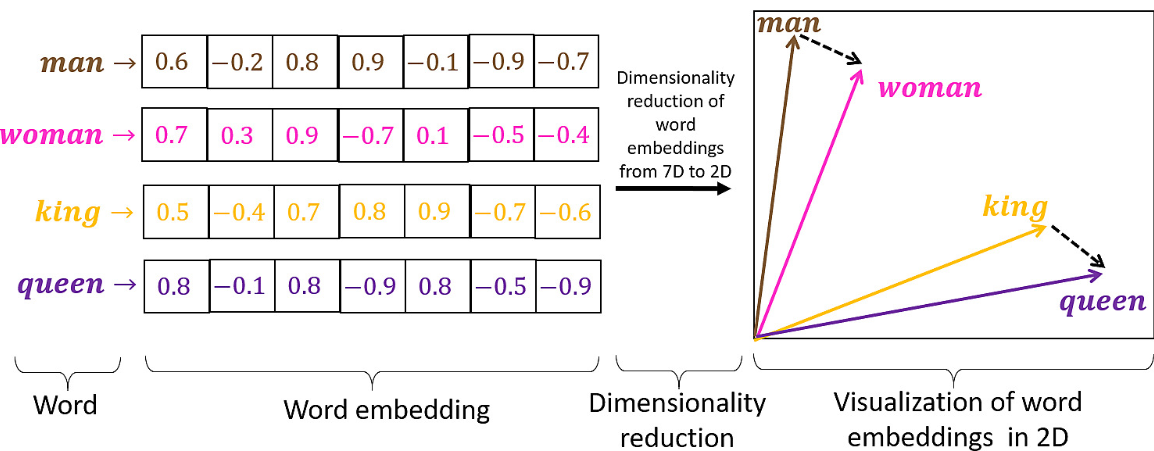
embeddings - vectorisation du texte
- texte -> vecteur
- cela donne une distance entre les textes qui respecte le sens des mots
- similarité sémantique :
d(chat, chien) < d(chat, banane) - il y a des modèles exclusivement dédiés à la création d'embeddings
Le plateformes de type chatbot
- plateforme : chatgpt.com, claude.ai, Mistral Le chat
- mais aussi : deepseek, qwen, gemini, ...
- API: le code envoie une requête (prompt + modèle) vers une url (endpoint), et le serveur retourne le contenu demandé. vrai pour tout le web et pour les LLMs.
- le coût peut être important
- pléthore de modèles
Pour les acteurs de type OpenAI, Claude, etc : abonnement et API sont facturés distinctement
Les plateformes specialisées
Voici une liste élargie de plateformes et services d’IA spécialisés
IA tout-en-un / plateformes multiplateformes
- ChatGPT (OpenAI) – assistant IA généraliste multitudes de tâches.
- Gemini / Claude / Grok – autres assistants IA puissants.
- Lumio AI – interface multi-modèles (ChatGPT, Claude, Gemini…) pour tester différents LLM dans un seul endroit.
Génération d’images / visuels
- Midjourney – création d’images à partir de textes ultra esthétique.
- DALL-E – générateur d’images (OpenAI).
- Stable Diffusion – open-source pour créations et modifications d’images.
- Bing Image Creator – IA image par Microsoft.
- Runway AI – outils créatifs incluant génération et édition d’images/vidéos.
Création vidéo / audio
- Synthesia – génération vidéo IA avec avatars.
- Google VEO – outil de création vidéo.
- HeyGen – plateforme vidéo IA.
- ElevenLabs – synthèse vocale réaliste.
Mais aussi
Assistant de recherche / gestion des connaissances
- NotebookLM – IA pour travailler, annoter et exploiter tes propres documents.
- Perplexity AI – moteur de recherche IA avec réponses sourcées.
- Deep Research / Elicit – recherche avancée IA de contenus académiques ou techniques.
Création d’applications / développement
- Lovable – IA pour générer des applications web complètes sans coder.
Marketing & contenus social
- Predis.ai – génération de contenus pour pubs et réseaux sociaux.
- AdCreative / Albert.ai / SE Ranking – IA marketing & SEO.
- Brevo IA – automatisation marketing complet.
Automatisation & productivité
- n8n – automatisation de tâches via IA et workflows.
- Manus – automatisation IA pour processus métier.
- Notion Q&A / Guru – gestion et extraction de connaissance IA dans les bases.
Support client & prospection
- Zendesk IA – support client automatisé.
- Clay – prospection IA avec enrichissement de leads.
- Crisp IA – support client RGPD friendly.
Éducation & contenus pédagogiques
- Mexty.ai – IA pour création de contenus éducatifs interactifs.
- plateforme fédératrice de modèles via API
- huggingface : tous les modèles, LLMs et autres. Le repository mondial.
- groq (pas grok) ,
- open routeur (modèles open source + rapidité)
- Ollama : modèles open source locaux
En local. Ollama. on download le LLM et on le fait tourner en local. donc petit LLM, ok pour des tâches très spécifiques. gratuit. mais nécessite machine puissante.
Pléthore de modèles
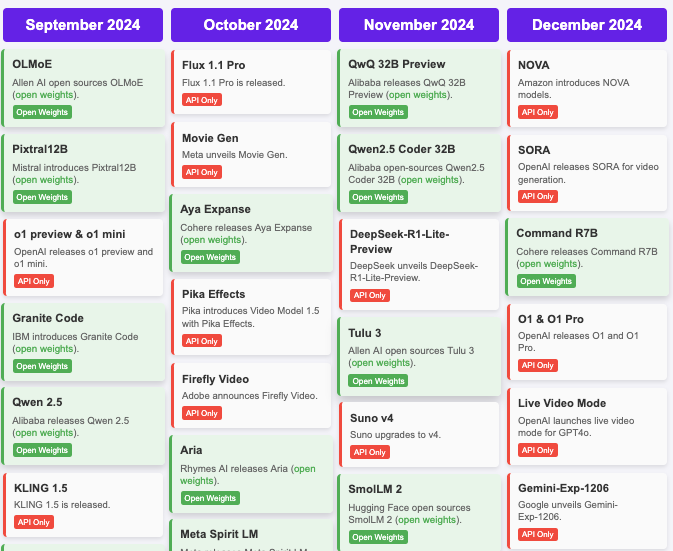
2024 AI Timeline - Hugginface release dashboards
Distinction majeure entre les modèles open source et closed source
Opensource vs Proprietaire: software
Open source:
- Le code est public : Linux
- Linux, OpenOffice, Firefox, Chromium, Python, grandes bases de données,
- Peut être copié et modifié par n'importe qui
Closed source:
- Le code n'est pas accessible.
- Windows, Word, Chrome, Edge, Oracle
- nécessite une licence pour utiliser, boîte noire

Open source LLMs
Différents niveaux d'ouverture :
- modèle : vous pouvez télécharger le modèle et l'utiliser tel quel => open weights
- code : le code pour créer le modèle
- données d'entraînement : les données utilisées pour entraîner le modèle
Certains modèles sont entièrement ouverts (DeepSeek), partiellement ouverts (Llama, Mistral 7B), ou fermés (OpenAI o1, Claude Sonnet, Gemini)
Si vous avez les poids d'un modèle vous pouvez le fine-tuner sur vos propres données. Version allégée de l'entraînement d'un modèle complet
Evaluation des LLMs, les benchmarks
Performances comparées: LLM Benchmarks
Comment évaluer et comparer les LLMs ?
Les benchmarks LLM sont des suites de tests qui mesurent la performance des grands modèles de langage sur différentes tâches, comme répondre à des questions, résoudre des problèmes, ou écrire du texte. Ils permettent de comparer les modèles côte à côte.
Défis : Les benchmarks ne reflètent pas toujours l'usage du monde réel, peuvent devenir obsolètes rapidement, et les modèles s'entraînent souvent sur les tests, ce qui signifie que des scores élevés ne garantissent pas toujours une meilleure utilité.
Benchmarks traditionnels :
- MMLU Massive Multitask Language Understanding : 16 000 questions à choix multiples
- HellaSwag : Une machine peut-elle vraiment finir votre phrase ?
- HumanEval : Génération de code
- GSM8K Problèmes de mathématiques : 8K Q&R niveau école primaire
Problème : Les modèles saturent rapidement ces tests
La nouvelle frontière :
- GPQA Diamond : 198 QCM en biologie, chimie et physique, du niveau "licence difficile" au "niveau post-diplôme".
- LiveCodeBench : benchmark d'évaluation sans contamination des LLMs pour le code qui collecte continuellement de nouveaux problèmes
- Humanity's Last Exam : questions de près de 1 000 contributeurs experts de plus de 500 institutions dans 50 pays – composé principalement de professeurs, chercheurs et titulaires de diplômes supérieurs.
Ceux-ci représentent les limites cognitives de l'humanité
Artificial Analysis Intellligence Index
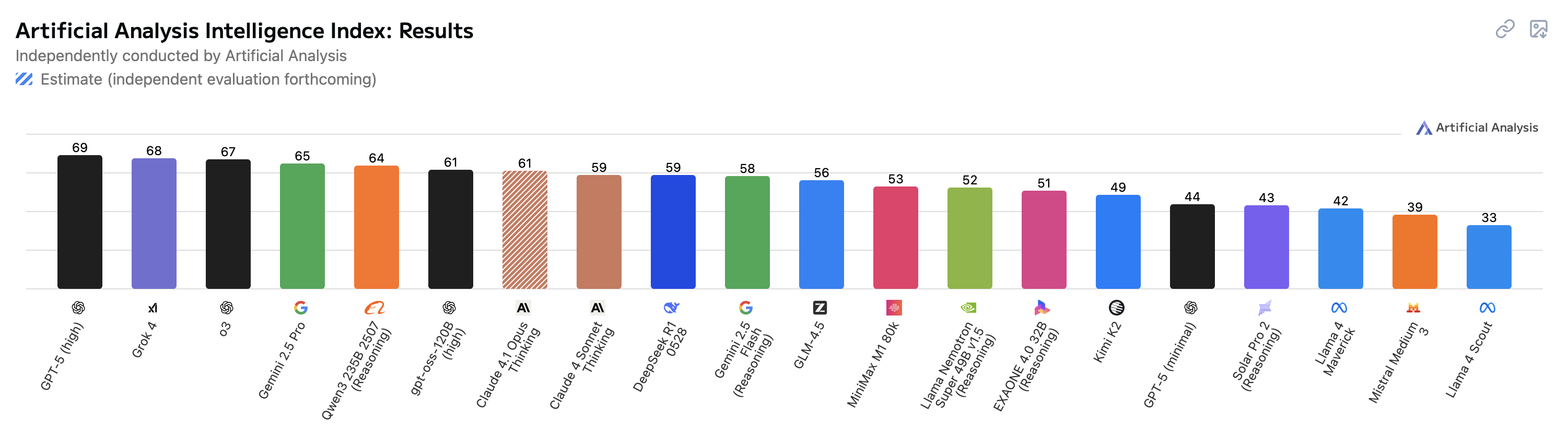
Artificial Analysis Intelligence Index combine les performances sur sept évaluations : MMLU-Pro, GPQA Diamond, Humanity's Last Exam, LiveCodeBench, SciCode, AIME 2025, et IFBench.
Score vs release date
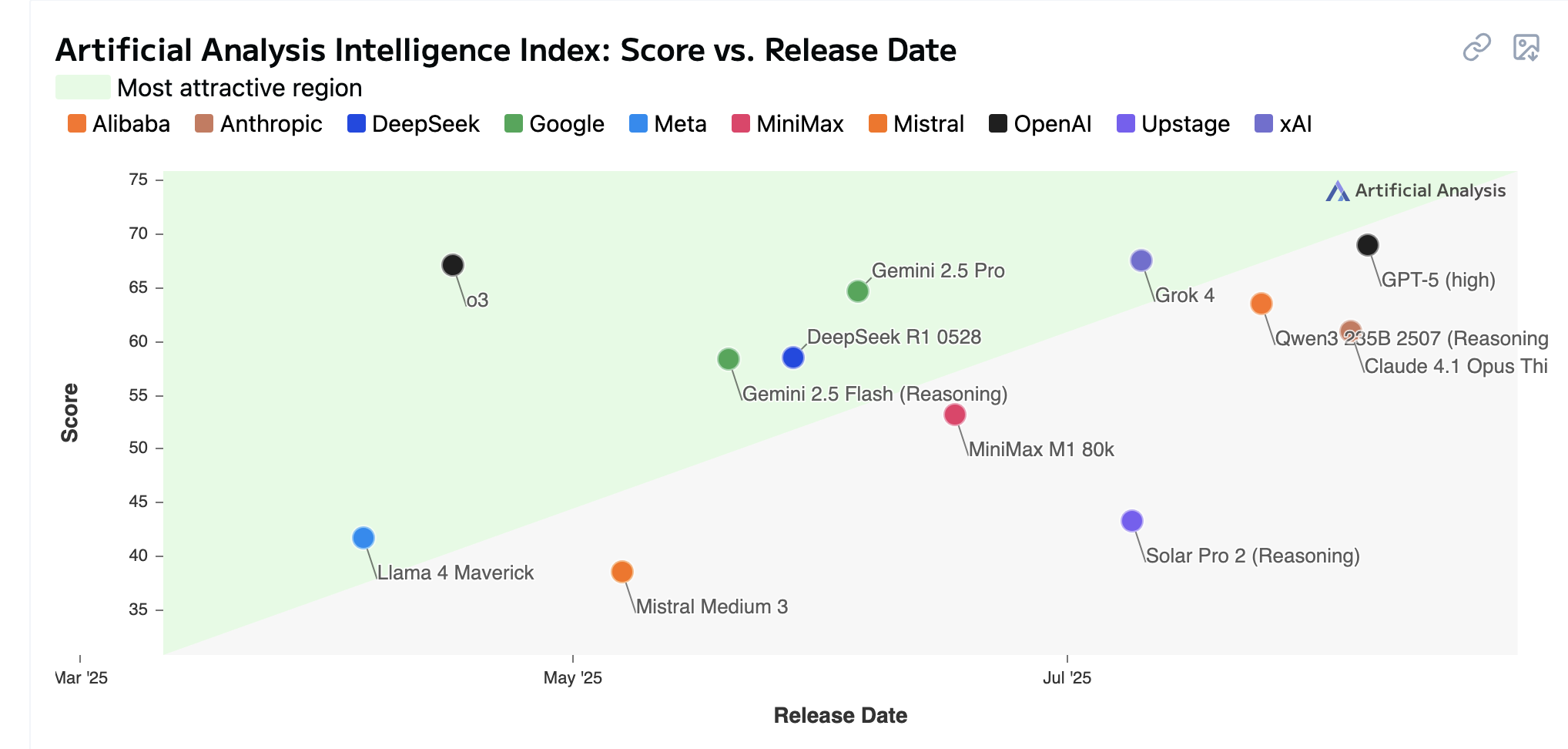
La course: open source vs propriétaires
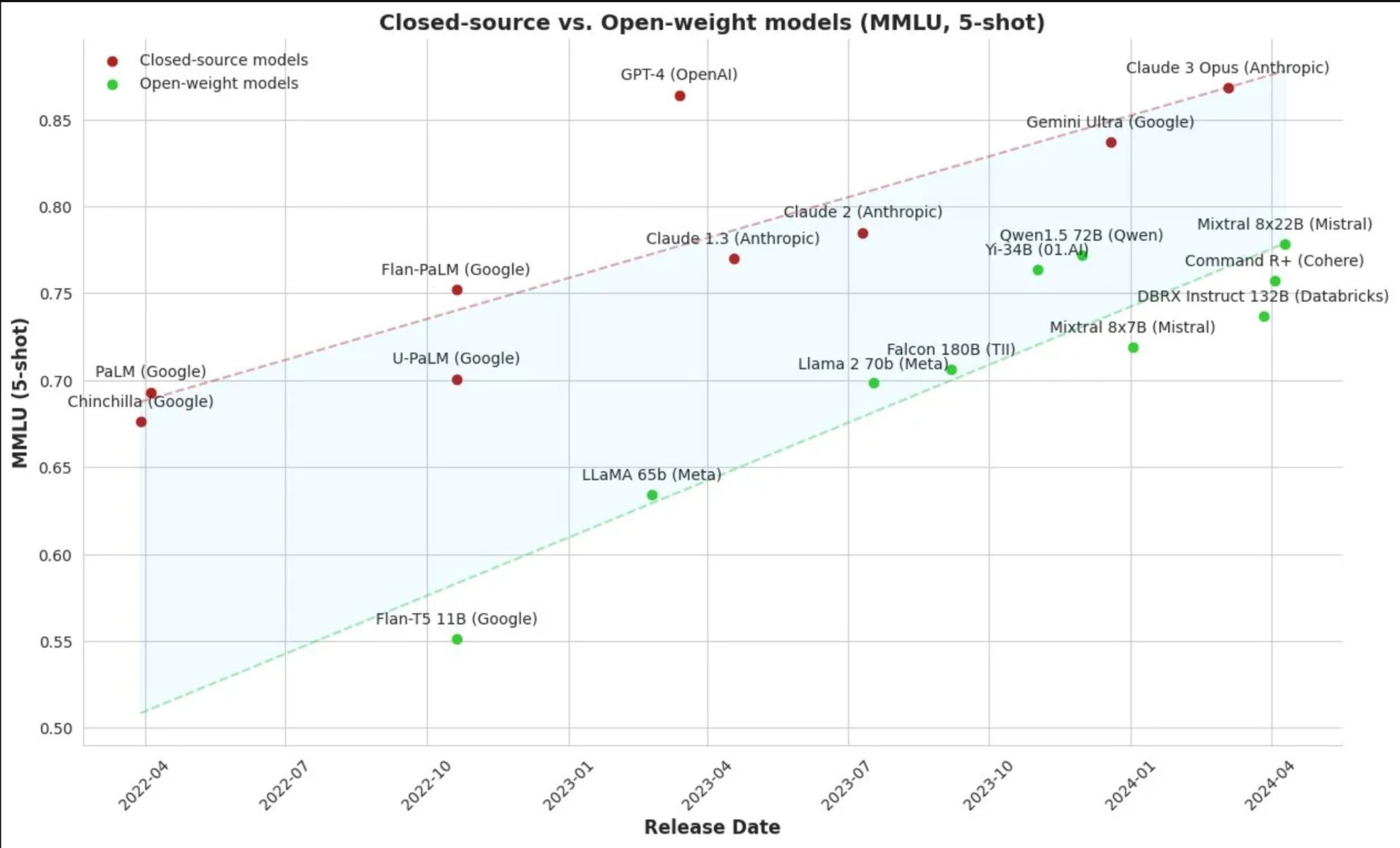
Les modèles open source rattrapent les modèles closed source
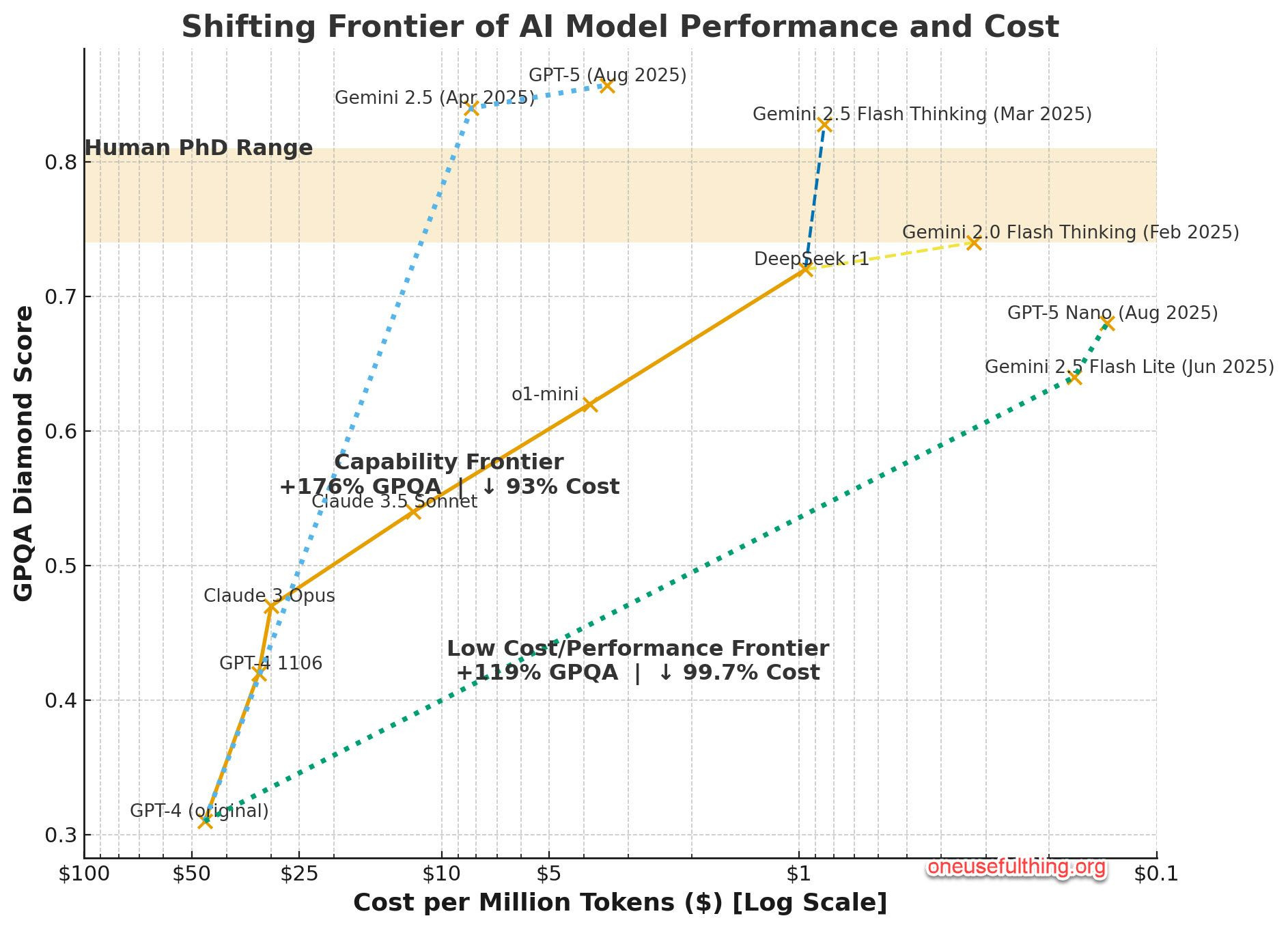
Performance vs Cost - 08/2025
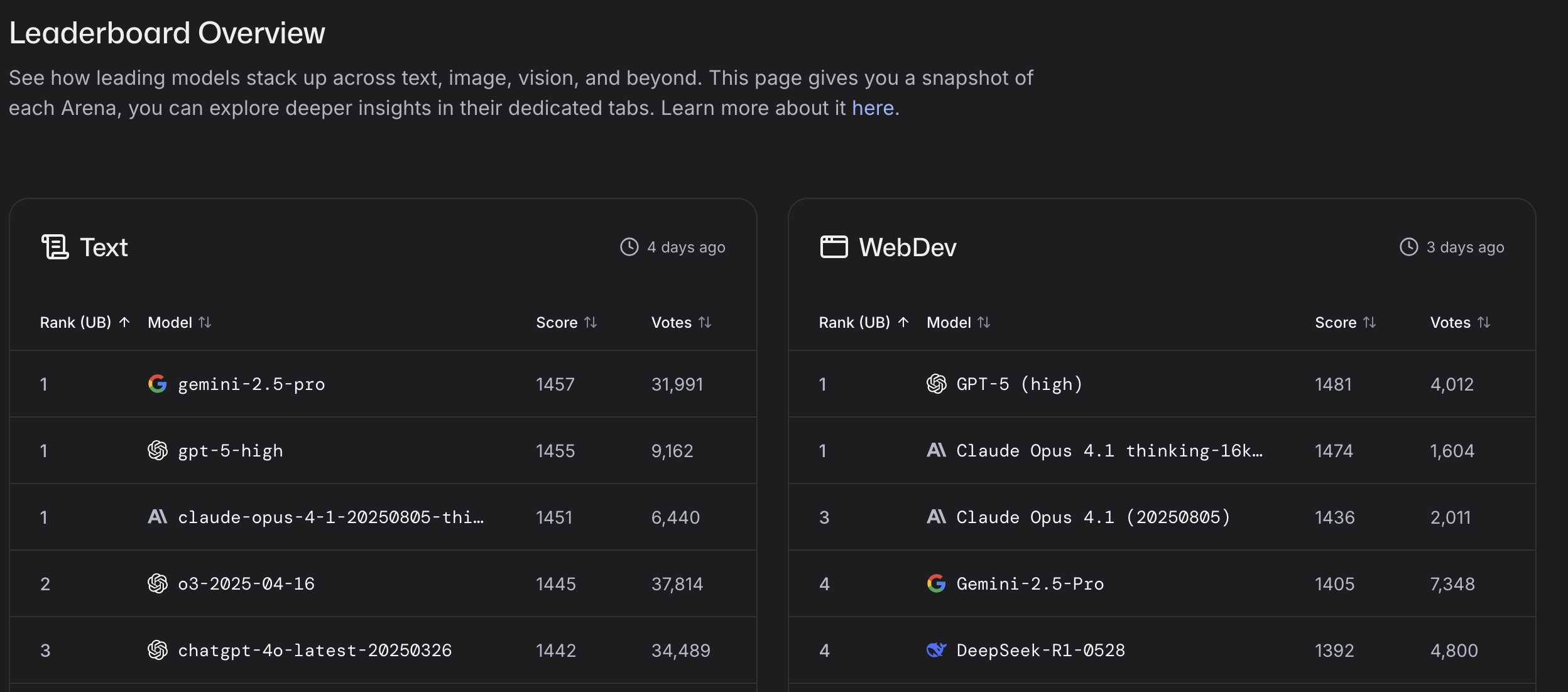
LM arena
Types de LLMs
- Licences : open source ↔ propriétaires
- Taille & usage :
- Mini-LLMs → Mid-size / spécialisés → Modèles de fondation
- généraux → multi tâches → spécialisés
- Langues : monolingues → multilingues
- Déploiement : local, cloud, embarqués (on-device)
- Entraînement : from scratch, fine-tuné
- Formats : textuels, multimodaux
- Modes d’utilisation : plateforme web ou application, API, intégration locale
Agents
LLMs augmentés
du LLM au LLM agentic : mémoire, outils, planification
Agent mode
les agents: newsletter.maartengrootendorst.com/p/a-visual-guide-to-llm-agents
-
mémoire :
- courte : résumé de chaque étape de la conversation dans le prompt
- longue : base de données
-
outils: websearch, etc
- Routing: étape du choix de l'outil
-
planification : Prompt chaining : décomposition de la requête en plusieurs sous tâches
-
Agent mode: planification + outils + mémoire + ... instance serveur
-
MCP : standard "universel" de connection. LLM a accès aux sources
- connection à Notion, Excel, Canva
Prompt
-
le contexte
-
le guider, l'aider à décomposer
-
des exemples si besoin pour ancrer
-
démarrer simple, passer progressivement au plus compliqué
Mon temps: écrire des spécifications comme prompts
system prompt vs user prompt
personnalité des modèles: le prompt system
Un prompt système est le fichier de politique et de personnalité de niveau racine que chaque demande d'utilisateur doit respecter. ... 'le manuel non officiel' des vraies capacités et garde-fous d'un modèle.
Claude 4 system prompt
claude 4 system prompt by simon Willison
focus sur chatGPT
- custom chatGPTs
- websearch
- deep search
- agent mode
sources d'info
-
les personnes à suivre: Ethan Mollick, Simon Willinson,
-
podcast: latent space + a16z
-
Mike Caulfield : do a second pass without putting a thumb on the scale almost always leads to a better result.