from LLMs to Agents
What we saw last time
-
modern NLP
- embeddings
- LLMs
- RAG
-
Spacy.io for NER and POS and lemmatization
-
Demo with spacy.io
Today
we talk about LLMs but when you use a AI interface you are using an Agent, an Augmented LLM
- web search
- image creation
- reasonning
- memory
- etc
We're going to look at pkatforms for inference: groq, openrouter
At the end of this class
You
- understand what an Agent is
- can query an inference platform
In the News
What caught your attention this week?
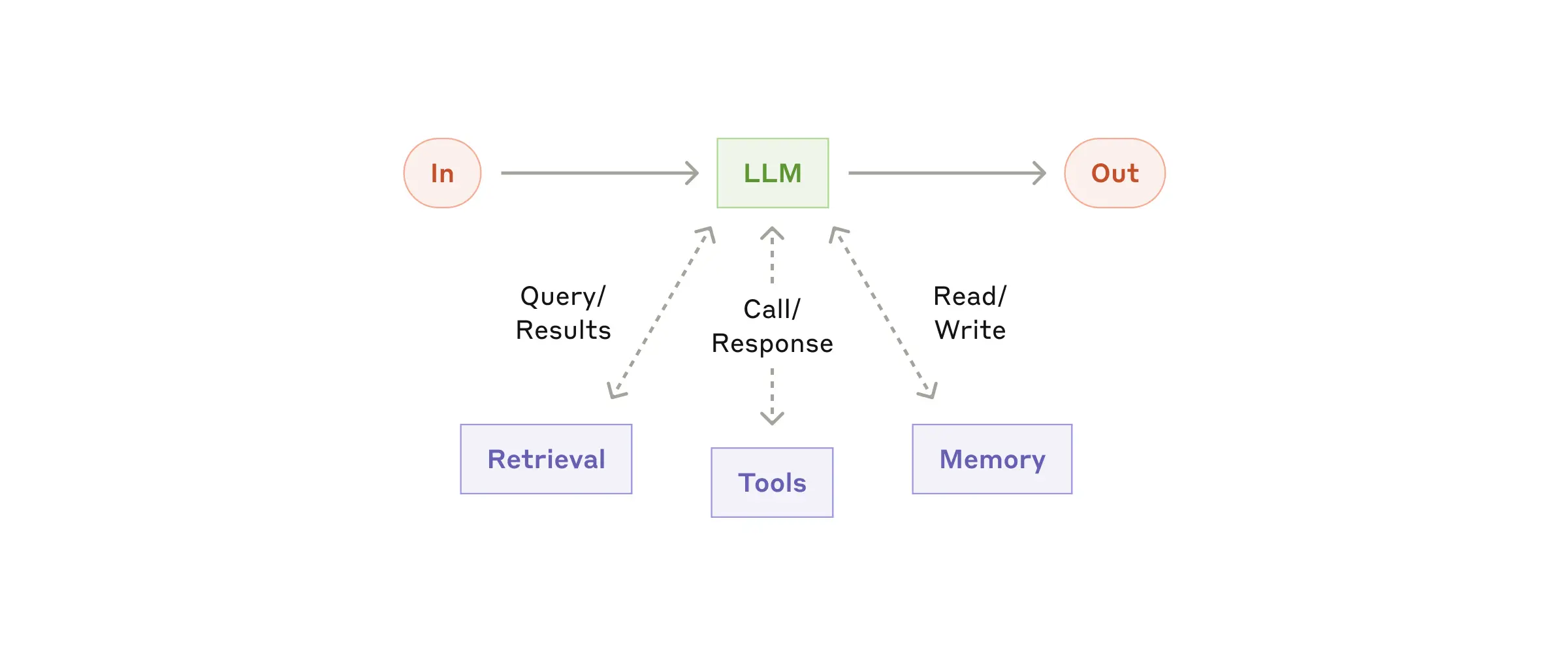
The Augmented LLM
Limitations of LLMs
Stand alone models:
- cutoff date
- limited access to data sources
- can't take actions
- hallucinations
- bias
Building effective agents - Anthropic
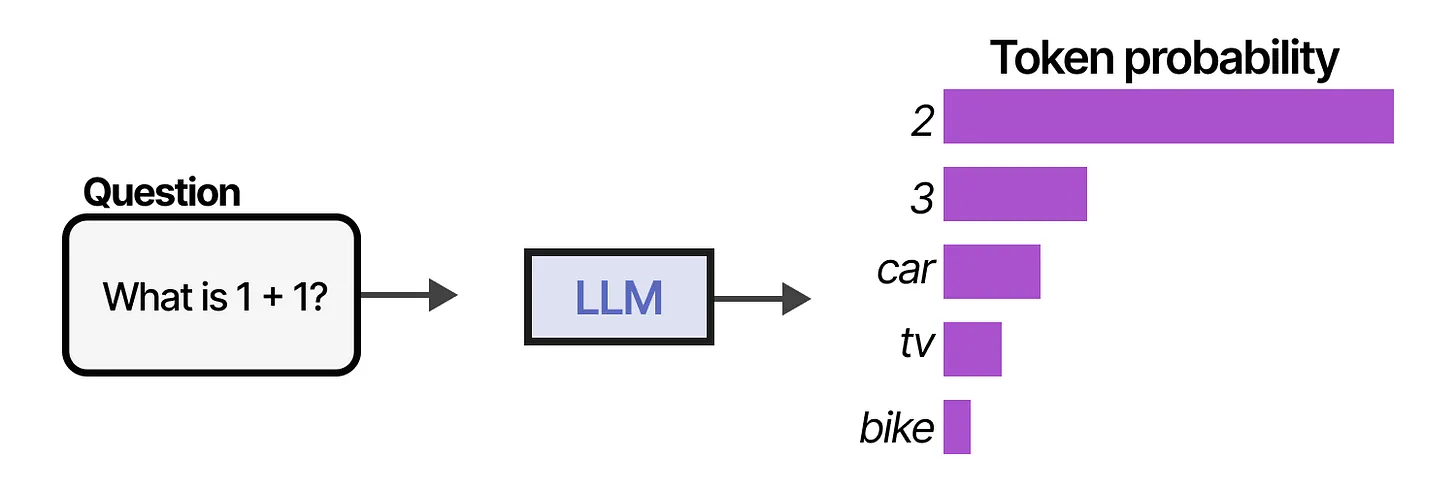
Traditional LLMs

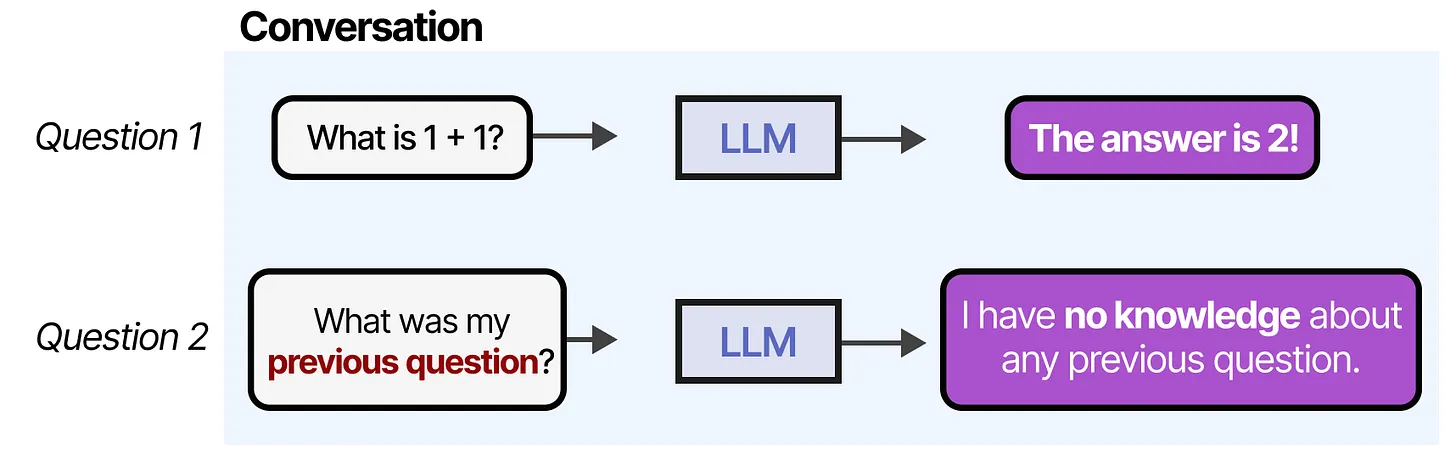
issues
No memory
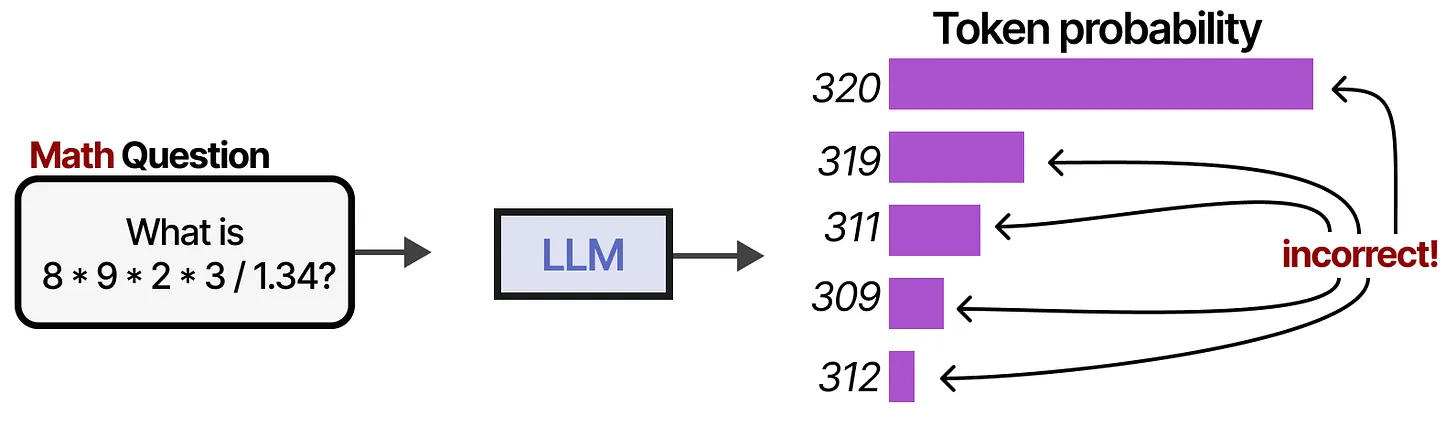
 wrong answer
wrong answer
What Are LLM Agents?
LLM Agents enhance basic language models with external tools, memory, and planning capabilities to interact autonomously with their environment.
- Traditional LLMs only predict next tokens and lack memory
- Agents = LLM + Tools + Memory + Planning
- Perceive environment through text, act through tools
- Varying degrees of autonomy based on system design
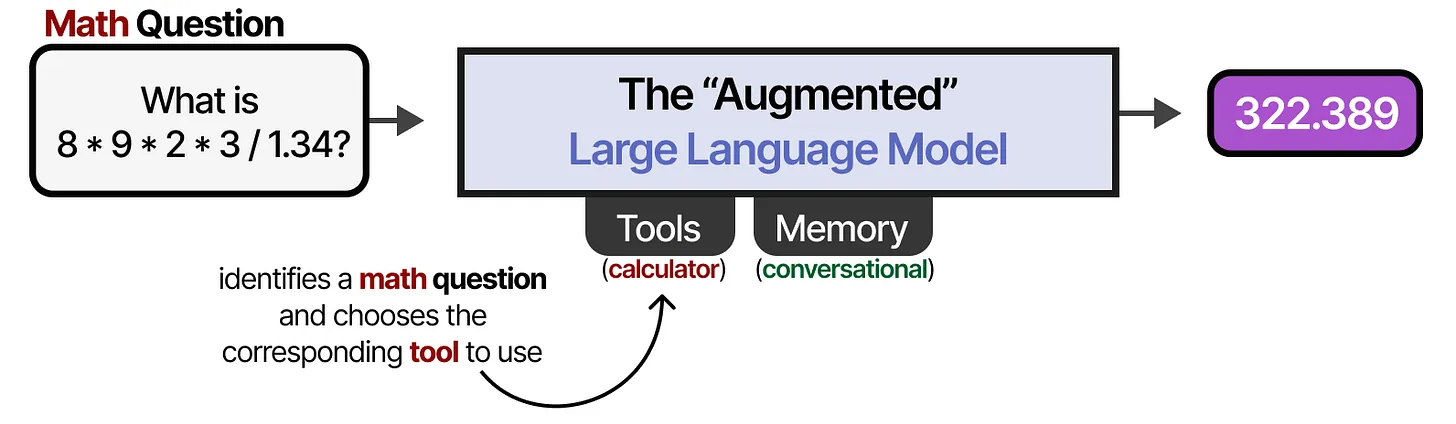
Core Components of Agents
Three essential components enable LLM Agents to function effectively in complex environments.
- Memory: Stores conversation history and past actions
- Tools: External systems for data retrieval and actions
- Planning: Reasoning and decision-making capabilities
- Components work together for autonomous behavior
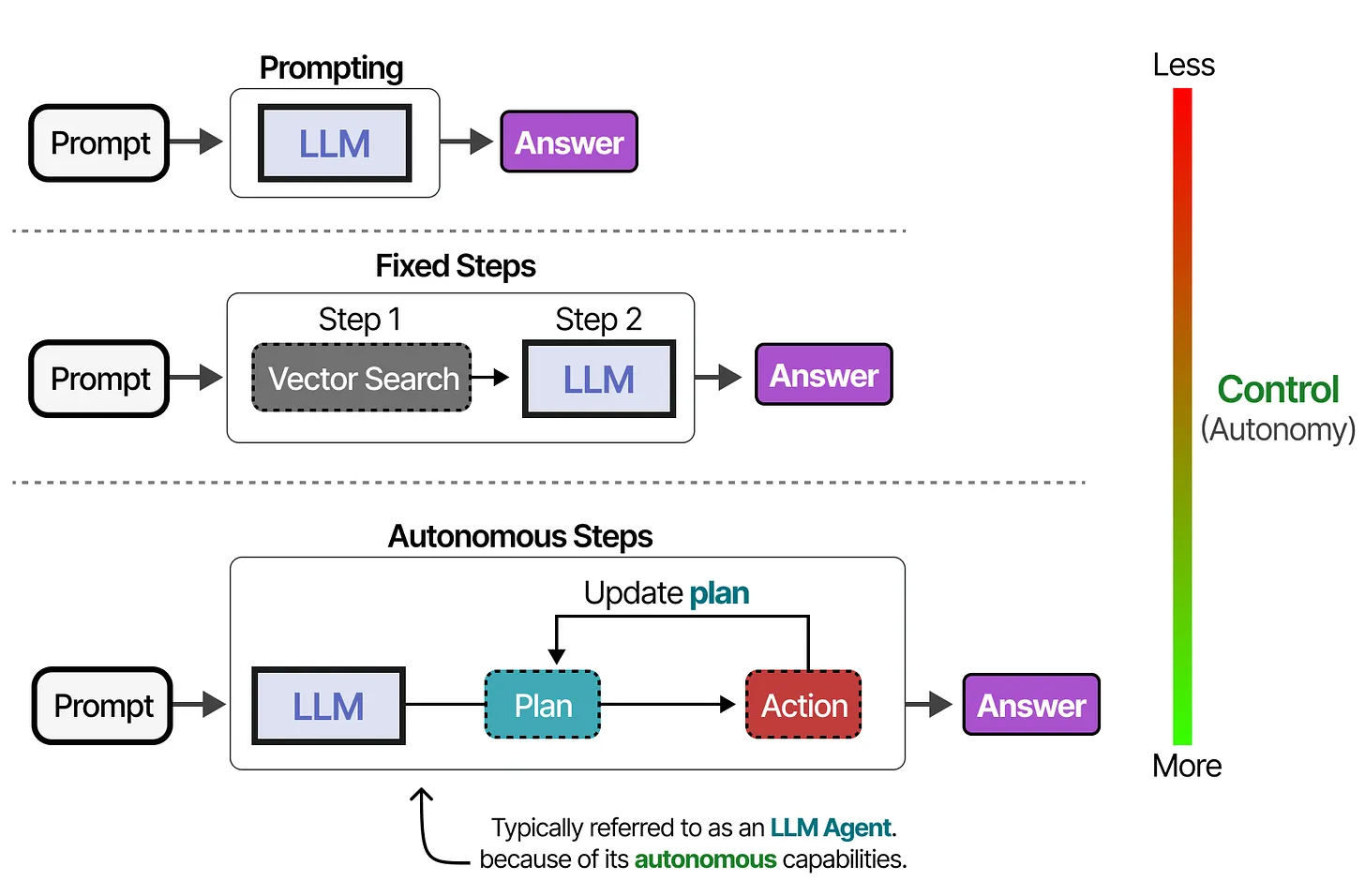
Anthopomorphising
- 🦵 Web browsing
- 📚 File upload - projects - knowledge base
- 🧠 Dynamic memory
- 👁️ Streaming
- 🖐️ Function calling
- 👄 speech
- 👂 voice
Hive Mind
My whole family shares the same account
ChatGPT remembers facts from previous conversations from everybody
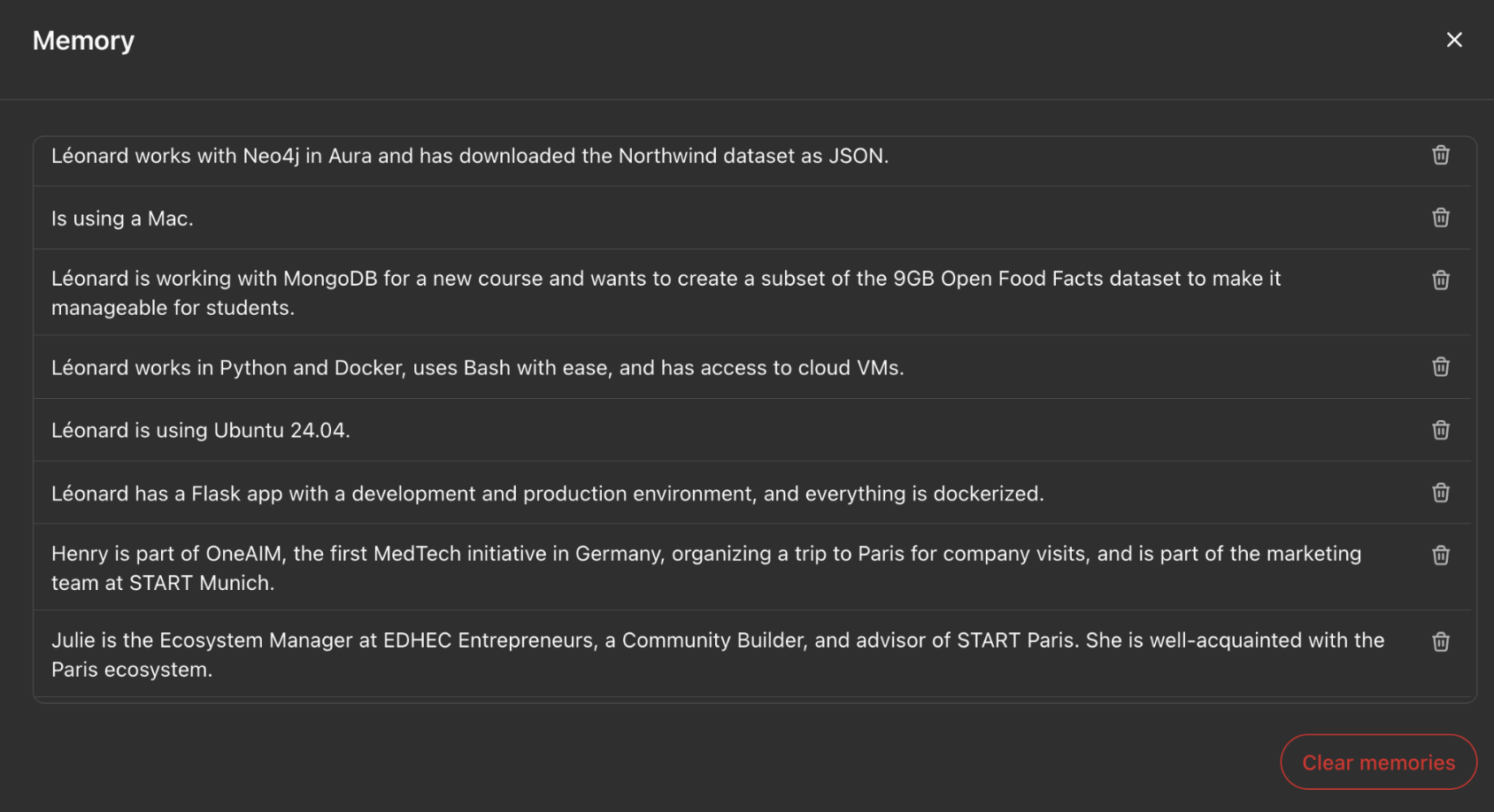
Memory Systems
Agents use short-term and long-term memory to maintain context and learn from interactions.
- Short-term memory: Uses context window for immediate context
- Long-term memory: External vector databases (RAG)
- Conversation summarization for efficiency
- Different memory types: semantic, working, episodic, procedural
Short term memory
Each prompt + output is summarized and added to the context window
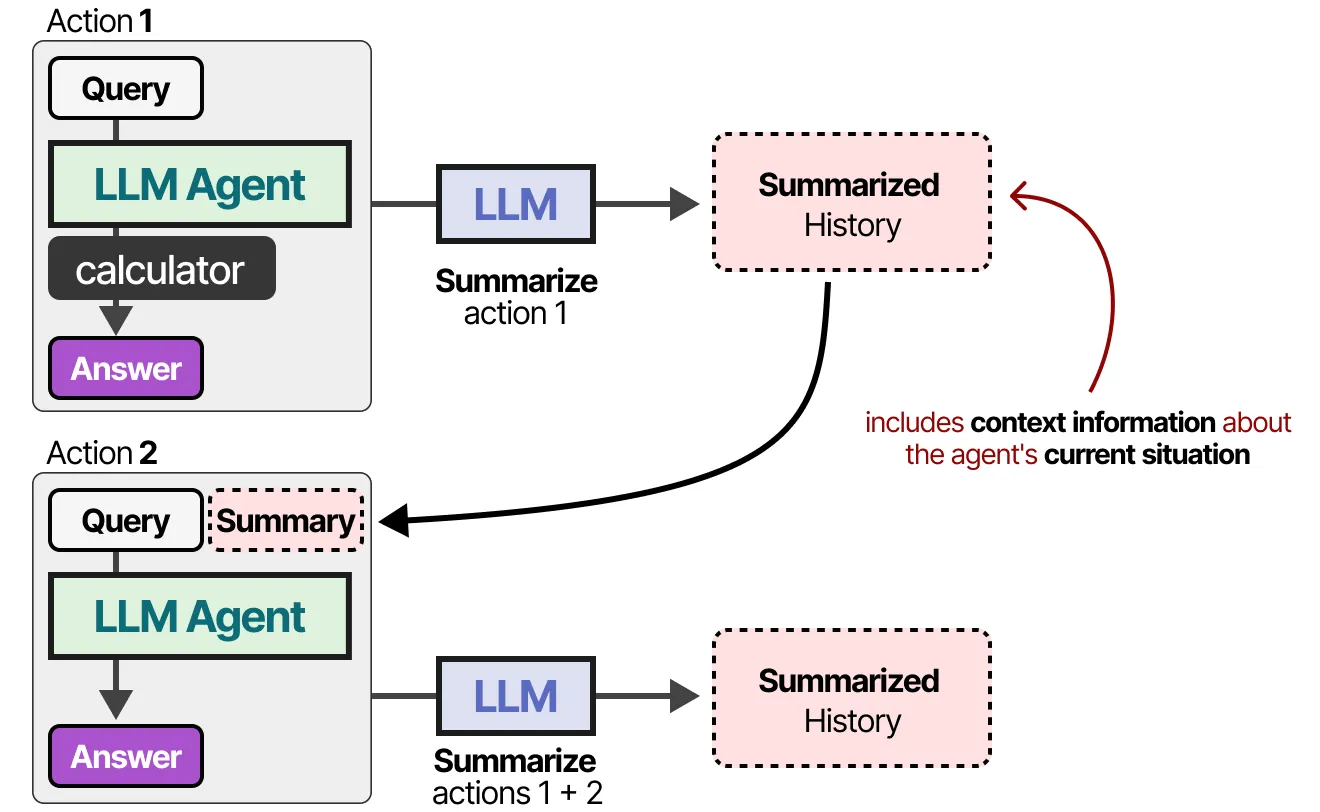
Long term memory : RAG
- Each prompt + output is summarized and added to a database
- vector search (embeddings) is used to find the most relevant information
- relevant info is added to the new user prompt
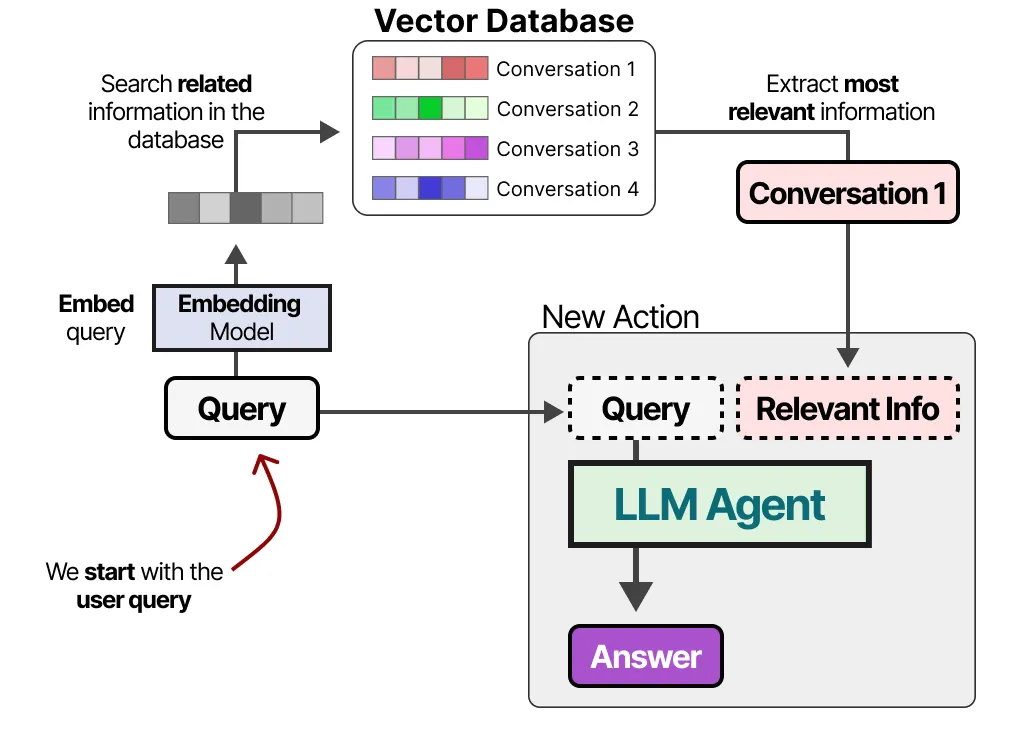
RAG: retreival augmented generation
Tools and Function Calling
Tools extend LLM capabilities by connecting to external APIs and services.
- Fetch real-time data and take actions
- Function calling through JSON-formatted requests
- Model Context Protocol (MCP) standardizes API access
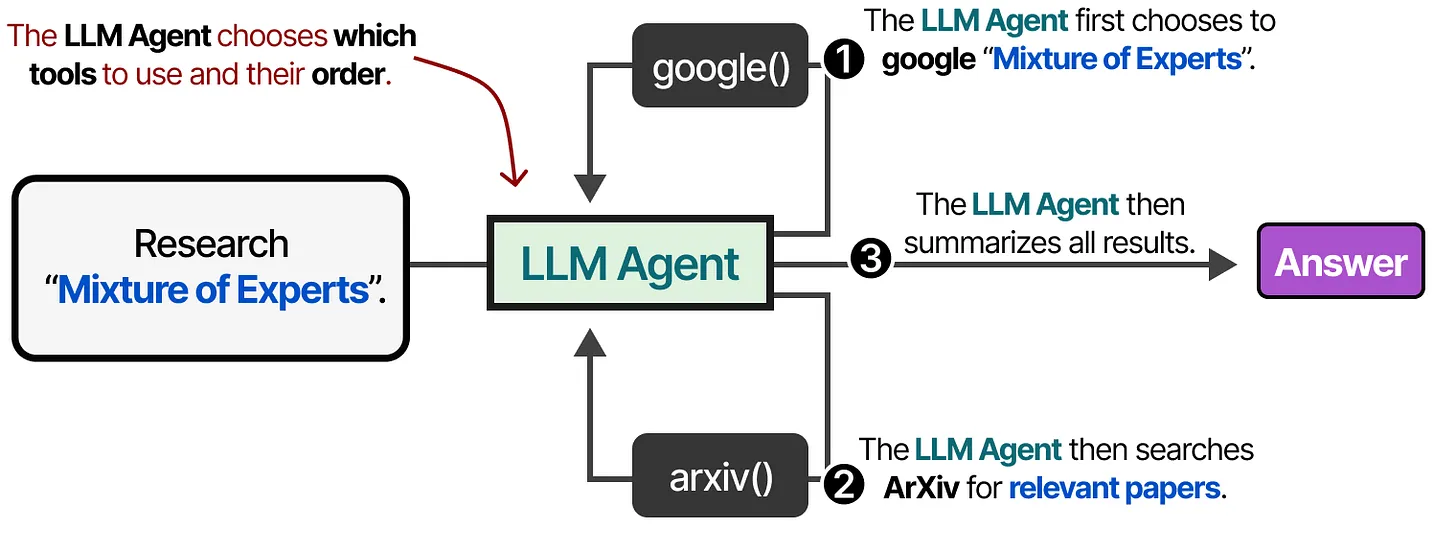
Planning Through Reasoning
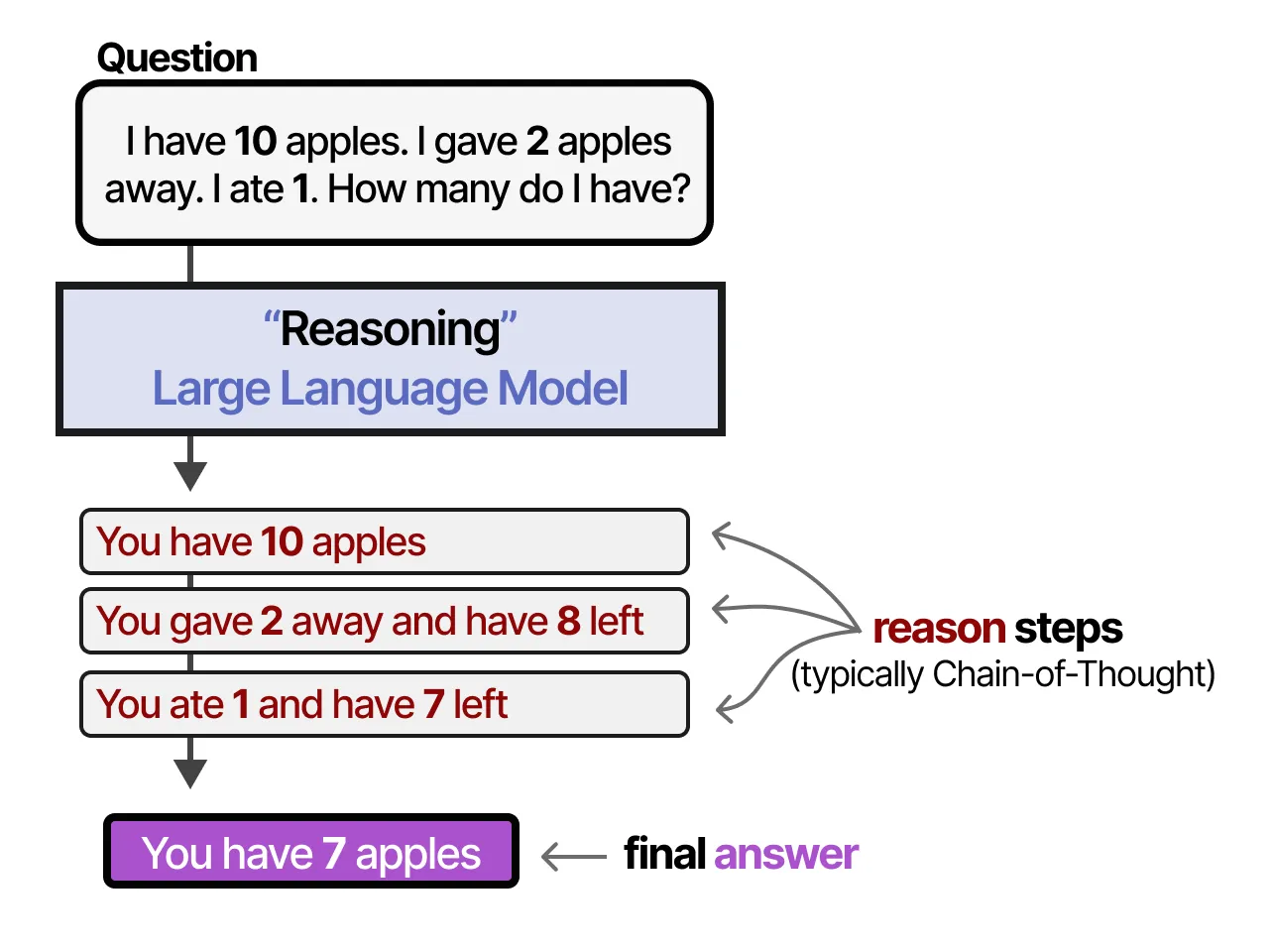
Planning breaks complex tasks into actionable steps through reasoning techniques.
- Chain-of-Thought prompting enables step-by-step thinking
- Few-shot vs zero-shot prompting approaches
- Fine-tuning models for reasoning (e.g., DeepSeek-R1)
- Iterative refinement of plans based on outcomes
instead of having LLMs learn “what” to answer they learn “how” to answer!
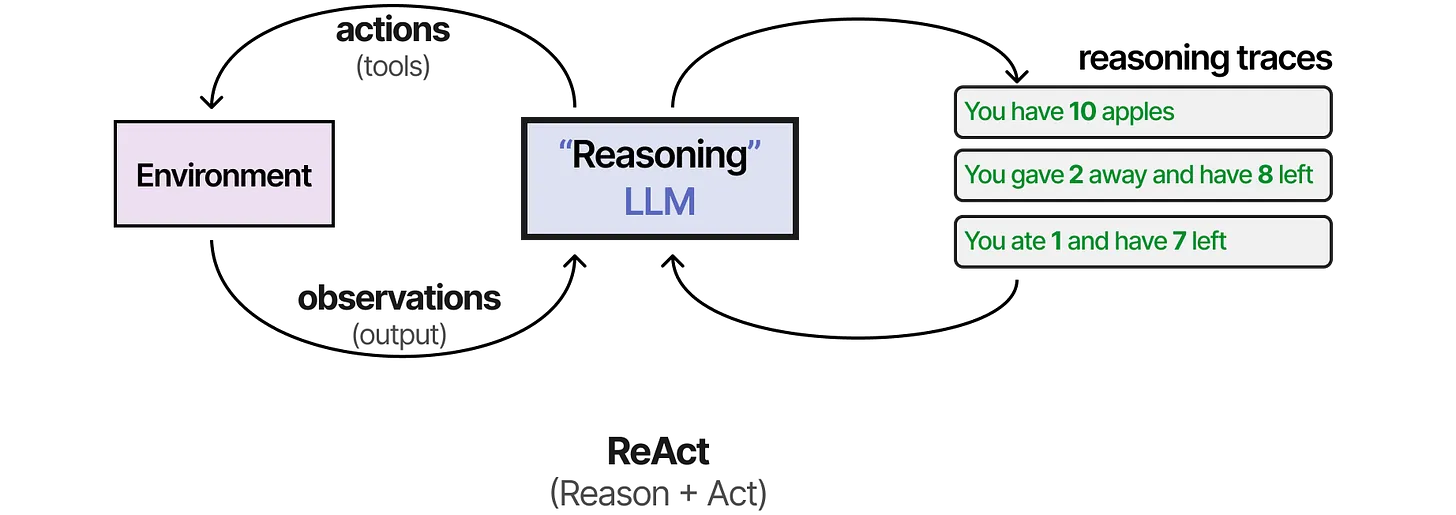
ReAct Framework
ReAct combines reasoning and acting in a structured cycle for autonomous behavior.
- Thought: Reasoning about current situation
- Action: Executing tools or operations
- Observation: Analyzing action results
- Continues until task completion

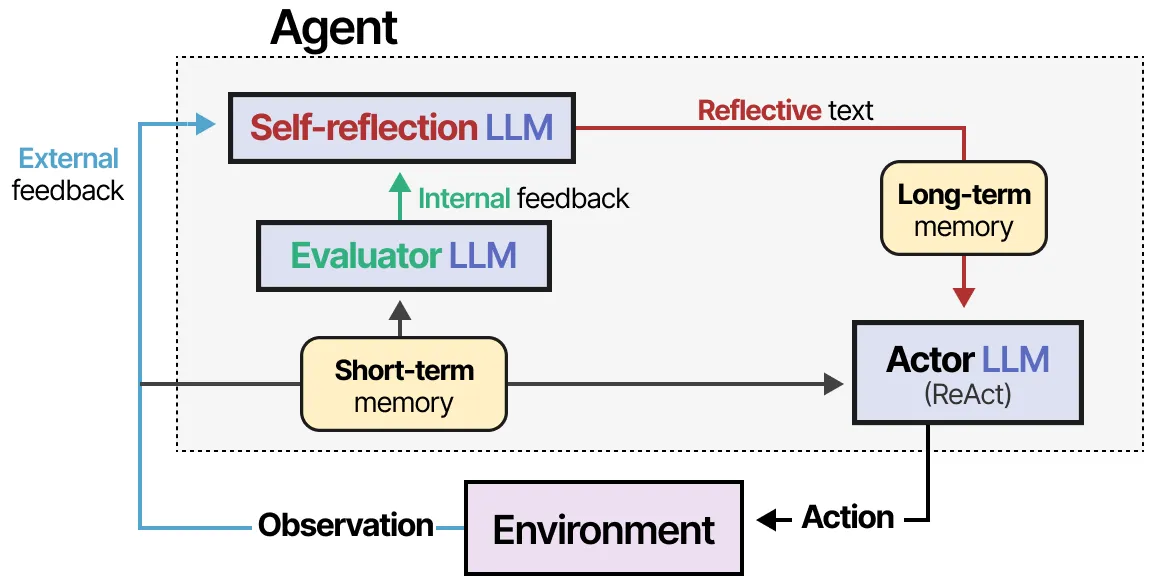
Self-Reflection and Learning
Agents improve through reflection on past failures and successes.
- Reflexion: Verbal reinforcement from prior failures
- Three roles: Actor, Evaluator, Self-reflection
- SELF-REFINE: Iterative output refinement
- Memory modules track reflections for future use
 ---
---
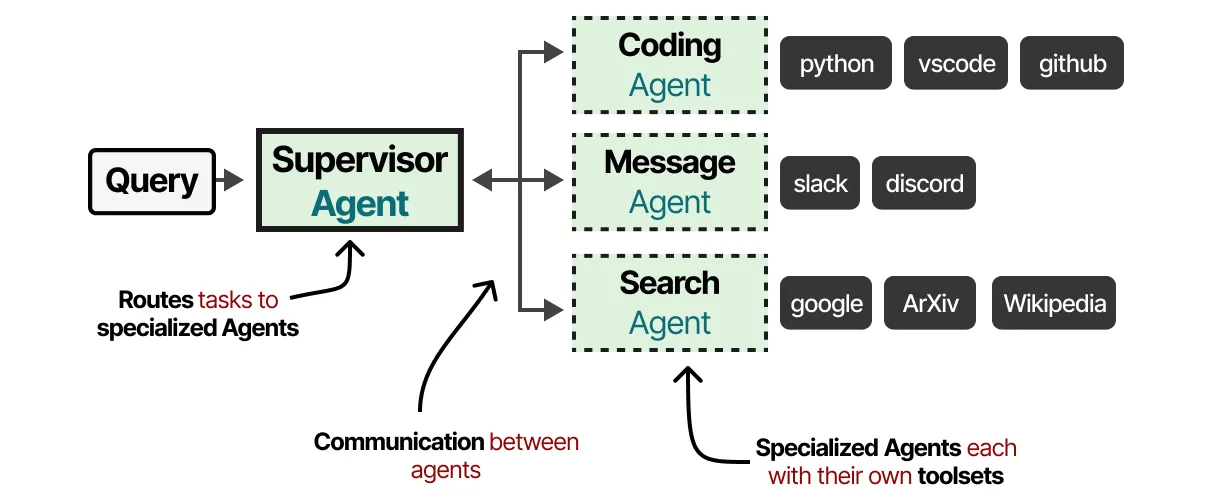
Multi-Agent Systems
Multiple specialized agents collaborate to solve complex problems.
- Each agent has specific tools and expertise
- Supervisor orchestrates agent communication
- Reduces complexity through specialization
- Examples: AutoGen, MetaGPT, CAMEL frameworks
Claude coding
This is not sci-fi
I use such agents everyday for coding in claude code
I also use Gemini / jules as another agent platform to review and improve Claude production. (security audit, code review, refactoring, SEO improvements, performance audit,etc )
Both platform
- have a plan or generate mode (different models)
- always create a plan
- can call tools : web search, github connection, file upload
- call a multitude of functions : search the codebase, execute command line
- have memory : context window
- can self reflect
How do we augment humans ?

- sports ?
- Gene editing with CRISPR (might take a few generations)
Intermission
Projects
Let's take the rest of the time to work on your projects
Next time
- Inference via APIs : openAI, Gemini,
- Fast Inference with Other models: openrouter, groq.
- compare open source LLMs vs closed source ones
new data source: ChinAI
Exit ticket
