Investigating
with AI
DHUM 25A43
Fall 2025

Who am I?
Alexis Perrier
- PhD TelecomParis 95'
- Developper, data scientist, author, teacher
- cycling, staying fit, scifi, ...
- grateful nerd
The Course
What is this course about?
Data Science for Social Sciences using AI
Data Search and Collection
Exploratory Data Analysis
Very data centric!
AI literacy
- LLMs, Agents, Models
- Hands on, how to build something
Is this what they call vibe coding ?
What do you do with all that data?
Data enrichment: semantic analysis, topic modeling, named entity recognition, etc. combining datasets, ...
Qualitative and Quantitative Analysis: stats, segmentation, insights, leveraging domain knowledge,etc.
Data visualization: What's the story, what's the narrative?

What's AI literacy?
- Pace of change is insanely fast
- things that was true, all the rage a few months ago is totally obsolete : prompting techniques for instance
- there is no curriculum
The only way to learn is to do!
- build things
- ask for stuff,
- try things out
- everyday
- practice, practice, practice
It goes way beyond writing emails or summarizing some text.
But it's hard. There's no "mode d'emploi".
What is this course about?
It is : **investigating with AI**
AI actors: LLMS, Agents, prompting, vibe coding, ... going meta
Hands-on: projects, practice, learning by doing
AI Literacy: Web, APIs, NLP, ML, DL, coding in python
Course Organization
Project
Hands on practice
Collaborative Work
Practical Focus
Session flow
- waking up, news review, coffee, questions (15mn)
- lecture, concepts, why and how (20mn)
- demo (30mn)
- nerdy cultural intermission (10mn)
- hands on practice / project work
- exit ticket: your feedback is muy importante
and questions, questions, and more questions
Office hours, support: discord! ![]()
Course Evaluation
-
group note (80%):
- website or report
- public presentation
-
individual : (20%):
- critical reflexion on your work and experience with IA.
- Write a personal report on your work with AI and propositions
AI:
- AI & LLMs
- major providers: OpenAI, Anthropic, Mistral, Qwen, Gemini
- tools and platforms: Groq, Huggingface, Open Routers
- Agents : combining LLMs for agency
Tech knowledge & culture:
- Web, APIs
- Coding in python and Pandas on Google Colab
- Data: how to collect and process
- NLP : Natural Language processing : analyzing text to extract information
- Machine Learning, deep learning : training models for prediction (knowledge)
Content & Tools
- discord for conversations
- skatai.com/inwai for documents
- Google colab notebooks for demos and practices
Course Project
Project Presentation
You are a team of data journalists. Choose your topic, ask the questions, exploit the data.
- Climate change, energy
- Politics, social medias, sports, food
- AI - robotics
- Brain–computer interface
- Data sources : media, social media, web, scientific publications, specific websites (COP, IMDB, wikipedia, Kaggle datasets)
Project Organization
Goal:. Design an engaging platform to showcase your report.
- Find Actionable datasets
- Formulate Research Questions
- Project Validation: Feasibility Check, Relevance
- Organization: 2 to 4, groups with complementary skills
- Evaluation, expectations
- Final exposé in front of class and experts
Getting to know you
All questions are optional (except your email)
Please fill out this form

State of AI
Why use AI?
- Super Powerful LLMs: Revolutionizing data analysis, interpretation, and automation.
- Impact on Data Science: Enhancing efficiency, accuracy, and scalability of workflows.
- Code Generation with LLM: Quickly develop data analysis pipelines
- Use of LLMs as an Autonomous Data Analysis Tool: extract patterns, trends, and insights from raw data. Analysis of large datasets or documents
- Accessible Methods: Simplifying complex data processes with user-friendly tools.
from Emergence to Transcendence
Language models are trained to mimic human behavioral data.
This mimicry makes it tempting to anthropomorphize a system—to think of it like a person. However, not only is the model not a person, it is not even trained to mimic a person.
Instead, the model has been trained to mimic a group of people with individual capacities, predilections, and biases. [...] but we also see the enormous advantage of training on data from a diverse set of people: often, it is possible to outperform any individual member of that group.
The capacity of a generalist model to exceed individual ability is evident in a chatbot that can converse with equal competence about cryptography, international law, and the work of Dostoevsky. Our goal is to describe the circumstances in which a model, trained to mimic multiple people, is capable of transcending its sources by outperforming each individual.
New AI models every week
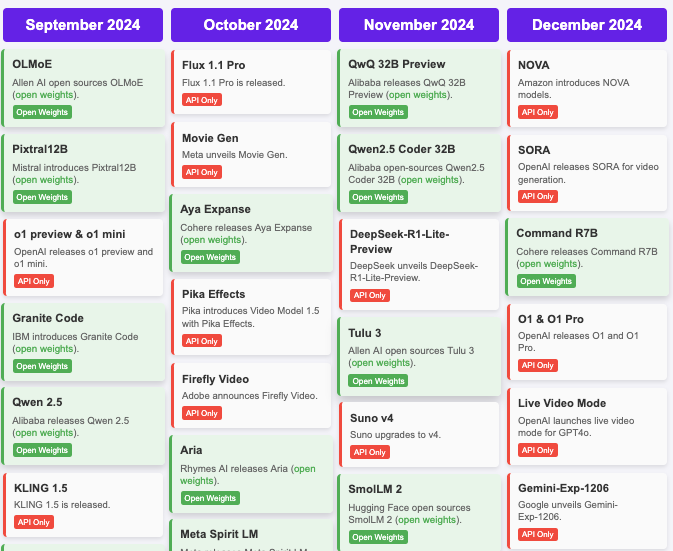
2025
- 2025-01-20 DeepSeek-R1 (DeepSeek)
- 2025-05-20 Veo 3 (May 20, 2025), text-to-video generator. also produces synchronized audio—marking
- 2025-05-22 Claude 4 (Anthropic) – Opus 4 + Sonnet 4. Long-horizon reasoning, memory features
- 2025-07-09 Grok 4 (xAI)
- 2025-08-07 GPT-5 (OpenAI), GPT‑5 is OpenAI's most advanced and unified model yet
- 2025-08-15 Solar Pro 2 by Upstage (South Korea)
Chatbot Arena: LLMs vs LLMs
Where LLMs compete LMArena.ai Leaderboard
- text
- webdev
- vision
- text-to-images
- search
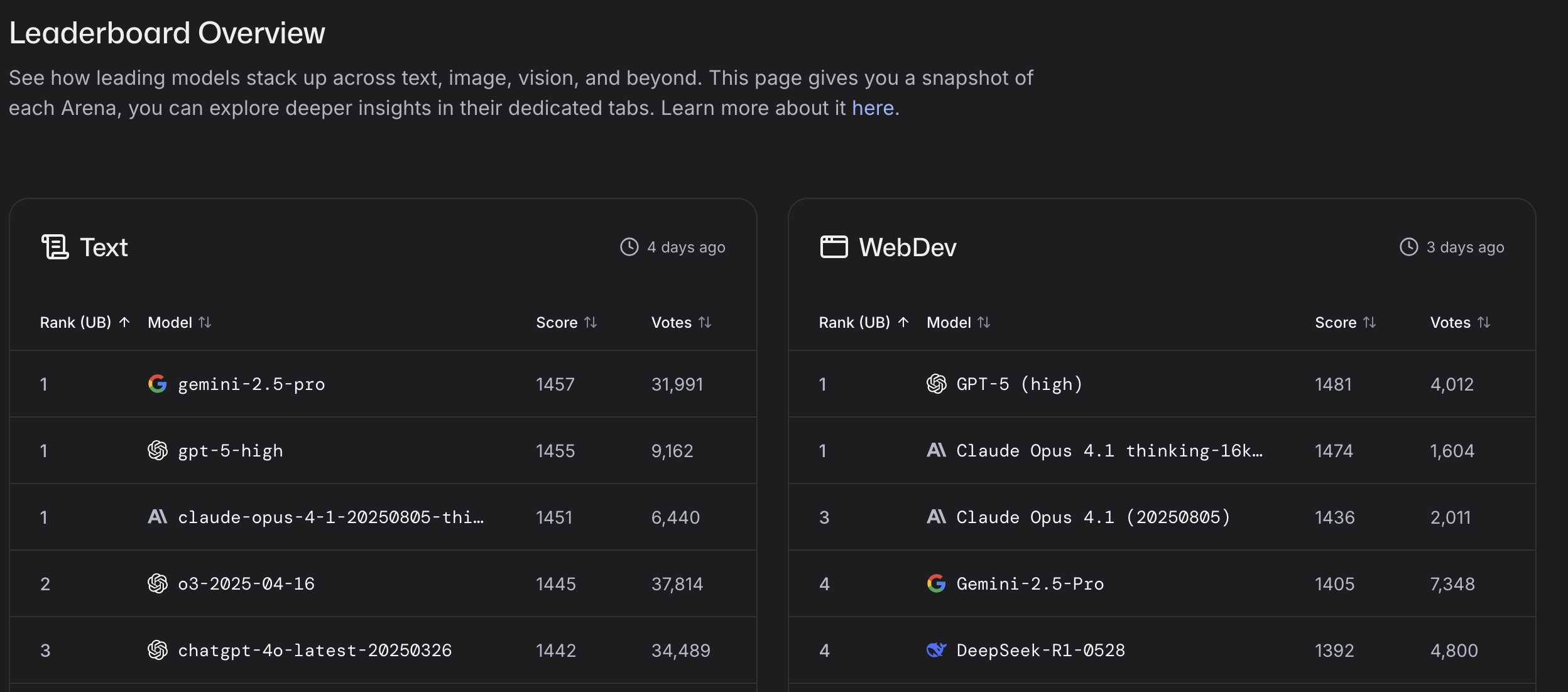
LLM Benchmarks
How do we evaluate and compare LLMs?
LLM benchmarks are tests that measure how well large language models perform on different tasks, like answering questions, solving problems, or writing text. They give a way to compare models side by side.
Challenges: Benchmarks don’t always reflect real-world use, can become outdated quickly, and models often “train to the test,” meaning high scores don’t always equal better usefulness.
Traditional Benchmarks:
- MMLU Massive Multitask Language Understanding: 16,000 multiple-choice questions
- HellaSwag: Can a Machine Really Finish Your Sentence?
- HumanEval: Code Generation
- GSM8K Math Word Problems: Grade School Math 8K Q&A
Problem: Models quickly saturate these tests
The New Frontier:
- GPQA Diamond: 198 MCQ in biology, chemistry, and physics, from “hard undergraduate” to “post-graduate level”.
- LiveCodeBench: contamination-free evaluation benchmark of LLMs for code that continuously collects new problems over time
- Humanity's Last Exam: questions from nearly 1,000 subject expert contributors affiliated with over 500 institutions across 50 countries – comprised mostly of professors, researchers, and graduate degree holders.
These represent humanity's cognitive boundaries
GPQA Diamond: Science at PhD Level
Graduate-Level Google-Proof Q&A
- Physics, Chemistry, Biology questions at PhD level
- Designed to be Google-proof - can't be solved by search
- Human PhD holders: ~65% accuracy
Why it matters: Tests deep scientific reasoning, not memorization
- Current AI leaders:
- Grok 4: 87.5%
- GPT‑5: 87.3%
- Gemini 2.5 Pro: 86.4%
- Grok 3 [Beta]: 84.6%
- OpenAI o3: 83.3%
LiveCodeBench
Real programming challenges from competitive coding platforms
- Problems released after model training
- Tests actual problem-solving, not memorization
- Updated continuously with fresh challenges
The question: What happens when AI exceeds human performance on every cognitive benchmark?
2025 Math Olympiad!
Google A.I. System Wins Gold Medal in International Math Olympiad
AI achieves gold medal solving International Mathematical Olympiad problems
two 4.5 hour exam sessions, no tools or internet, reading the official problem statements, and writing natural language proofs.
Artificial Analysis Intellligence Index
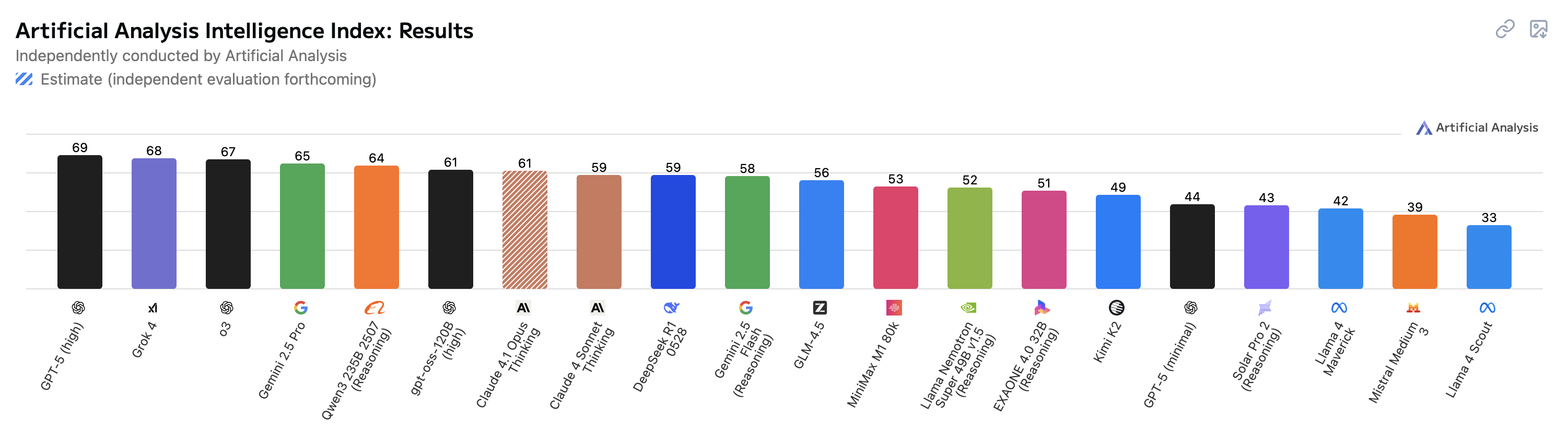
Artificial Analysis Intelligence Index combines performance across seven evaluations: MMLU-Pro, GPQA Diamond, Humanity's Last Exam, LiveCodeBench, SciCode, AIME 2025, and IFBench.
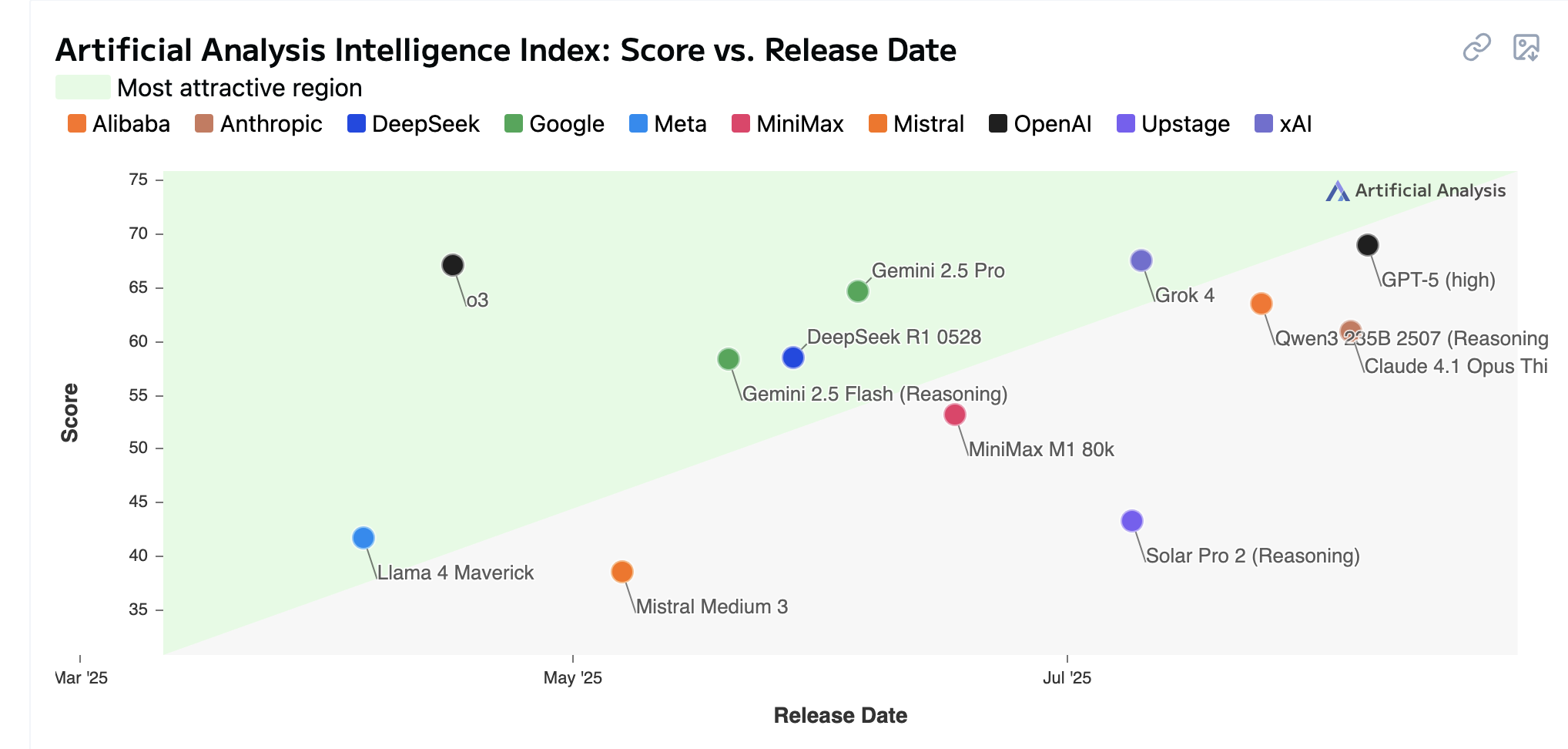
Score vs release date
Cost
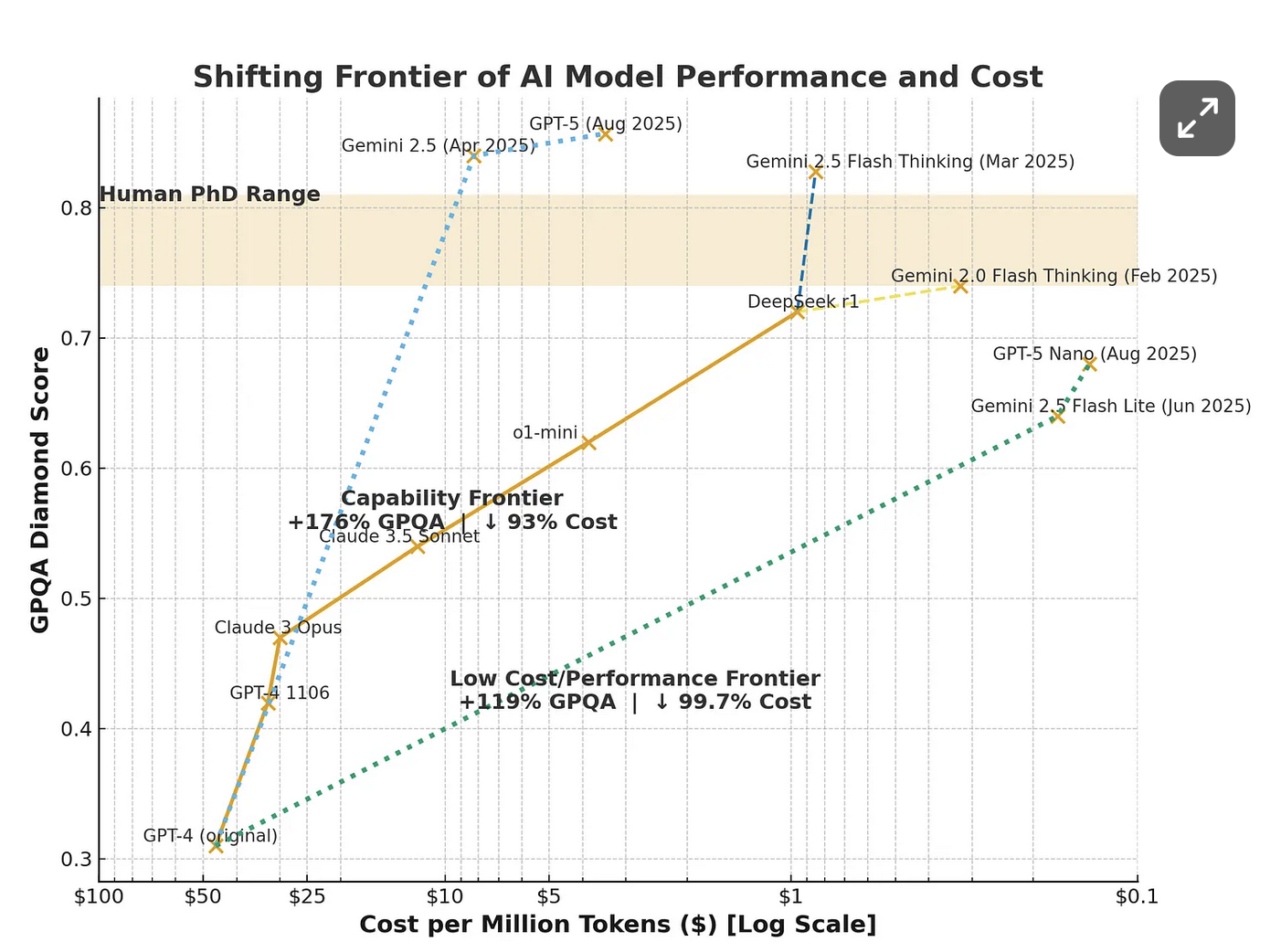
"When GPT-4 came out it was around / Mtokens to use GPT-5 nano. GPT-5 nano is a much more capable model than the original GPT-4."
Enery and water consumption
see measuring the environmental impact of delivering ai at google
"Google has reported that energy efficiency per prompt has improved by 33x in the last year alone.
The marginal energy used by a standard prompt from a modern LLM in 2025 is relatively established at this point, from both independent tests and official announcements.
It is roughly 0.0003 kWh, the same energy use as 8-10 seconds of streaming Netflix or the equivalent of a Google search in 2008.
Image creation seems to use a similar amount of energy as a text prompt.
How much water these models use per prompt is less clear but ranges from a few drops to a fifth of a shot glass (.25mL to 5mL+)
Ethan Mollick - Mass Intelligence - Aug 28, 2025
Questions
Intermission
41'37"
Google Colab
Google Colab
Shareable, collaborative work
A notebook is a series of executable cells
- code (python)
- text with Markdown
https://colab.research.google.com/
Text with Markdown
What you write
Simple Syntax
# Header 1
**this is bold**, not bold
[a link](https://sciencespo.fr)
Demo
markdown and code in colab
Let's explore some penguins
... with pandas

The dataset
Demo
In this demo, I will
- load the penguins data into a pandas dataframe
- do some basic exploration
- ask for visualizations and analysis
Your turn
Simple exercise on google colab with a similar dataset : the Titanic!
The titanic dataset is a classic in machine learning.
- List of 200 passengers
- some features (age, sex, name, ticket price, etc.)
- and a target variable : survival or not. 0 or 1

You will write text in Markdown, run a simple Python function (with Gemini’s help)
Then load some data and explore it. And try to understand the code.
✅ Task 1 – Write in Markdown
- Open a new Colab notebook
- Add a markdown Text cell
- Write a title, a short paragraph and a bullet list
✅ Task 2 – Ask Gemini for Code
- In a new Code cell, ask Gemini to “Write a Python function that greets someone by name.”
- Run the code with your name
✅ Task 3 – Exploration and analysis of a dataset
Ask gemini
- open the file https://raw.githubusercontent.com/SkatAI/DHUM25A43/refs/heads/master/data/titanic.csv
- questions about that data : how many rows etc
- explore the file and produce interesting insights with visualizations
Gemini probably knows this file by heart. It's a classic!
✅ Task 4 – going meta
Take one of the cell code generated by Gemini and ask Gemini to explain the code.
Dive deep to really understand what's going on.
Gemini never tires, never judges
Next week
- Topic: Web and APIs
- Practice : data formats and the pandas library
For next week
Project
- topics,
- team mates,
- data sources,
- research questions
Read the news
EXIT ticket

Need help ? Got a question ? Share something ?
- Ask an LLM
- Ask another LLM
- I am available on discord
Please post your questions in the course channel #sciencespo-dhum25a43 not in private messages, so all can contribute.