NLP
Natural Language Processing
Style classique
Aujourd'hui
-
NLP classique
- tokens
- NER: Named Entity Recognition
- POS: Part of Speech
- topic modeling
- classification de texte : sentiment, hate speech, catégorisation, spam etc
-
quelques librairies : Spacy.io, NLTK
De la linguistique au NLP

- La linguistique est l'étude scientifique du langage humain—comment il est structuré, comment il fonctionne, comment il évolue, et comment les gens l'utilisent pour communiquer.
- Le NLP (Natural Language Processing) est un domaine de l'informatique et de l'IA qui vise à enseigner aux ordinateurs à comprendre, interpréter et générer le langage humain.
Le NLP applique les connaissances de la linguistique pour construire des technologies du langage. La linguistique fournit la compréhension théorique du fonctionnement du langage, tandis que le NLP utilise ces connaissances (ainsi que les statistiques et le machine learning) pour créer des applications pratiques comme les outils de traduction, les chatbots et les assistants vocaux.
En bref : la linguistique étudie le langage, le NLP fait travailler les ordinateurs avec le langage.
Autres références classiques
1957 Benveniste : Problèmes de linguistique générale

voir wikipedia Chomsky
La base de la théorie linguistique de Chomsky réside dans la biolinguistique, l'école linguistique qui soutient que les principes sous-tendant la structure du langage sont biologiquement prédéfinis dans l'esprit humain et donc génétiquement hérités. Il soutient que tous les humains partagent la même structure linguistique sous-jacente, indépendamment des différences socioculturelles.

Speech and Language Processing

Speech and Language Processing (3rd ed. draft) Dan Jurafsky and James H. Martin
Dernière version : 24 août 2025 !!
Chronologie
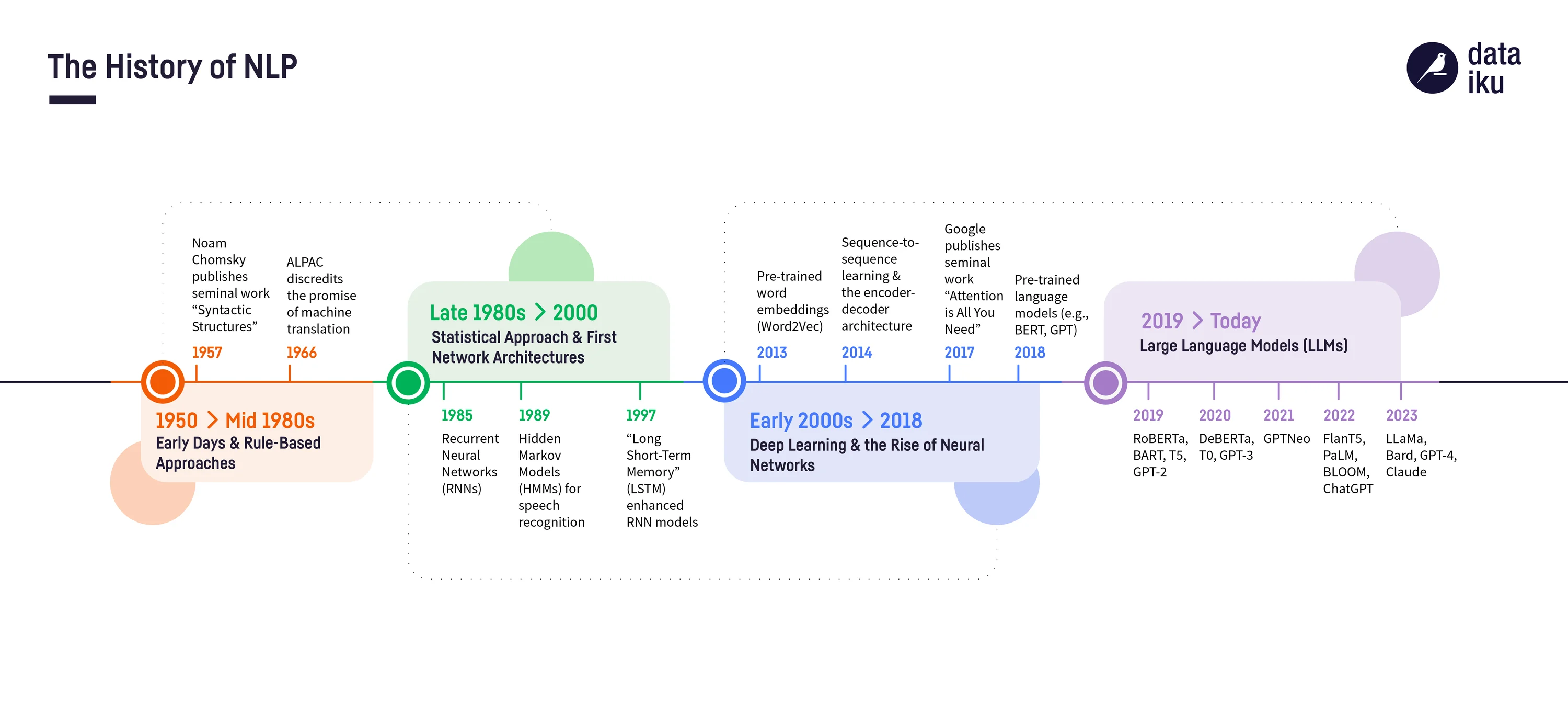
Chronologie du NLP : les débuts
| Époque / Année | Développements clés du NLP | Performance sur les tâches |
|---|---|---|
| Années 1950-1960 | Premières expériences de traduction automatique, ex. Georgetown-IBM (1954) ; théories de la grammaire générative (Chomsky, 1957) ; ELIZA (1964) | Traduction automatique primitive ; NER pas encore formalisé ; systèmes de dialogue purement basés sur des règles |
| Années 1970-1980 | SHRDLU (1970) ; PARRY (1972) ; essor des systèmes experts et règles artisanales | Compréhension du langage limitée à des domaines contraints |
| Fin années 1980-1990 | Adoption de modèles statistiques ; NER à partir d'actualités (MUC-7 ~1998) ; la traduction automatique statistique remplace les approches à base de règles | NER F1 ~93%, approchant l'humain (~97) ; traduction automatique statistique avec portée et qualité limitées |
| Années 2000 | Traduction automatique statistique généralisée (ex. Google Translate dès 2006) | Qualité de la traduction automatique en amélioration mais loin du niveau humain ; NER robuste dans des domaines limités |
Chronologie du NLP
| Époque / Année | Développements clés du NLP | Performance sur les tâches |
|---|---|---|
| 2010-mi-2010s | Introduction des word embeddings (Word2Vec 2013, GloVe) ; RNNs et modèles seq2seq ; débuts de la traduction automatique neuronale | Les embeddings permettent la similarité sémantique ; la traduction automatique neuronale obtient des améliorations notables |
| Fin années 2010 | Architecture Transformer (2016) ; BERT (2018) ; adoption dans les moteurs de recherche dès 2020 | NER et QA atteignent le niveau humain ou super-humain sur les benchmarks ; la traduction automatique approche la fluidité quasi-humaine |
| Années 2020 (ère LLM) | Émergence de GPT-3, ChatGPT, GPT-4, etc. (les LLMs dominent le paradigme NLP) | Excellence généralisée : performance au niveau humain ou supérieure en traduction, NER, résumé, raisonnement |
Le langage est... compliqué
Tu peux Léfer ? : tu demandes de l'aide pour Léfer (un nom de famille).
Tu peux l'E faire : tu demandes à quelqu'un d'écrire/dessiner la lettre E.
Tu peux l'éfer ? : tu demandes d'aiguiser quelque chose (argot).
Le langage est... compliqué
- Longueur variable
- Grande variété de complexité selon les langues
- Allemand :
Donaudampfschiffahrtsgesellschaftskapitän(5 "mots") - Chinois : 50 000 caractères différents (2-3k pour lire un journal)
- Langues slaves : Formes de mots différentes selon le genre, le cas, le temps
- Allemand :
- Encodage : unicode vs Ascii
- Données non structurées
- code switching
- idiomes, argot générationnel, slang
Problèmes classiques du NLP
- Text mining
- NER : Named Entity Recognition : LOC, PER,
- POS : Part of Speech Tagging : noms, adjectifs, verbes, ...
- Classification : analyse de sentiment, spam, hate speech, ...
- Identification de topic, topic modeling
- WSD : word sense disambiguation : bank, fly
- STT : speech to text, text to speech
et des tâches plus difficiles telles que
- Traduction automatique, résumé, question answering
NLP classique
- déterministe (non probabiliste - LLMs)
- basé sur la décomposition du texte en éléments identifiables : mots, rôles grammaticaux, entités, etc.
- appliqué aux phrases, syntagmes nominaux, mots
- inclut des méthodes de pré-traitement du texte brut pour faciliter le traitement
- stop words : et, le, de, etc.
- stemming : universités, universel, univers -> univer (le sens est souvent perdu)
- lemmatization : cours, courir, couru -> courir (plus efficace que le stemming)
- subword tokenization : "malheureux" → ["mal", "heur", "eux"]
Nécessite des modèles, des règles qui sont spécifiques à chaque langue. Le russe ou le français ont besoin de lemmatizers différents de l'anglais.
Quelle est l'unité du texte ?
On pourrait travailler avec
- des mots, syllabes, tokens, lettres et ponctuation
- des Bigrams, n-grams : New York, cul-de-sac, pain au chocolat
- des syntagmes nominaux : groupe de mots qui fonctionne comme un nom : le gros chien brun avec des taches
- des phrases, paragraphes, tweets, articles, livres, commentaires
- un Corpus : un ensemble complet de textes
Il faut gérer
- Le vocabulaire est large / infini et change rapidement
- Les fautes de frappe, orthographes multiples
- les formes de mots : pluriel, déclinaison (maison, foyer), conjugaison, etc.
Subword tokenization
Quelle est l'unité de texte la plus efficace ?
-
Utiliser des mots est problématique : vocabulaire très large, formes multiples : pluriel, déclinaison (maison, foyer), conjugaison, etc.
-
Utiliser des lettres est trop court
-
Divisons les mots en plusieurs tokens : subword tokenization
- malheureux -> mal + heur + eux
- courant -> cour + ant
- universités -> uni + vers + ité + s
Avantages du subword tokenization
- aucun mot n'est OOV : out of vocabulary (gpt 3.5 ne connaissait pas COVID)
- capture mieux le sens sémantique et morphologique
- Gestion du vocabulaire : on obtient un vocabulaire infini à partir de tokens finis
C'est aussi pourquoi les LLMs sont très robustes face aux fautes de frappe et aux erreurs d'orthographe.
Bag of words pour la classification binaire
vous voulez construire un modèle qui peut prédire si un email est spam ou non spam, ou si un avis est positif ou négatif (analyse de sentiment)
Pour entraîner le modèle, vous devez transformer le corpus en nombres.
La principale méthode NLP classique pour cela est tf-idf (term frequency-inverse document frequency)
Pour chaque phrase, on compte la fréquence de chaque mot et on la normalise par le nombre de documents dans le corpus qui contiennent le mot.
Cela nous donne une matrice que nous pouvons utiliser pour entraîner un modèle.
mais cette approche a plusieurs problèmes
- OOV : les mots Out of Vocabulary ne sont pas pris en compte
- vocabulaire large => matrice énorme
- pleine de zéros
etc
- fonctionne pour les tâches faciles (spam, sentiment) mais échoue pour les tâches plus complexes

Exemple de tf (term frequency)
Prenons un exemple. Considérons les 3 phrases suivantes de la célèbre chanson Surfin' Bird et comptons le nombre de fois que chaque mot apparaît dans chaque phrase.
| about | bird | heard | is | the | word | you | |
|---|---|---|---|---|---|---|---|
| About the bird, the bird, bird bird bird | 1 | 5 | 0 | 0 | 2 | 0 | 0 |
| You heard about the bird | 1 | 1 | 1 | 0 | 1 | 0 | 1 |
| The bird is the word | 0 | 1 | 0 | 1 | 2 | 1 | 0 |
en français : sur le pont d'avignon
NER : reconnaissance d'entités nommées
Tous types d'entités prédéfinies : lieu, groupes, personnes, entreprises, argent, etc.
Le NER utilise
- Pattern matching : Recherche de majuscules, titres (M., Dr.), listes d'entités connues
- Indices contextuels : Des mots comme "travaille chez" suggèrent qu'une organisation suit
- Modèles statistiques : Entraînés sur des données étiquetées pour reconnaître les motifs d'entités
Les modèles et règles NER sont spécifiques à chaque langue

POS : étiquetage des parties du discours
Identifier la fonction grammaticale de chaque mot : ADJ, NOUN, VERBs, etc.
Le POS utilise :
- Terminaisons de mots : "-ment" souvent = adverbe, "-tion" souvent = nom
- Règles de position : Les déterminants ("le") viennent avant les noms
- Contexte : Le même mot peut être nom ou verbe ("cours" vs "je cours")
Les modèles et règles POS sont également spécifiques à chaque langue

Démo NLP classique : NER et POS
https://cloud.google.com/natural-language
Entrez du texte : (texte du FT sur l'impact de l'IA sur le trafic dû aux résumés IA dans la recherche Google)
"Like everyone, we have definitely felt the impact of AI Overviews. There is only one direction of travel; not only are AIs getting better, but they're getting better in an exponential fashion," said Sean Cornwell, chief executive of Immediate Media, which owns the Radio Times and Good Food brands in the UK.
NER

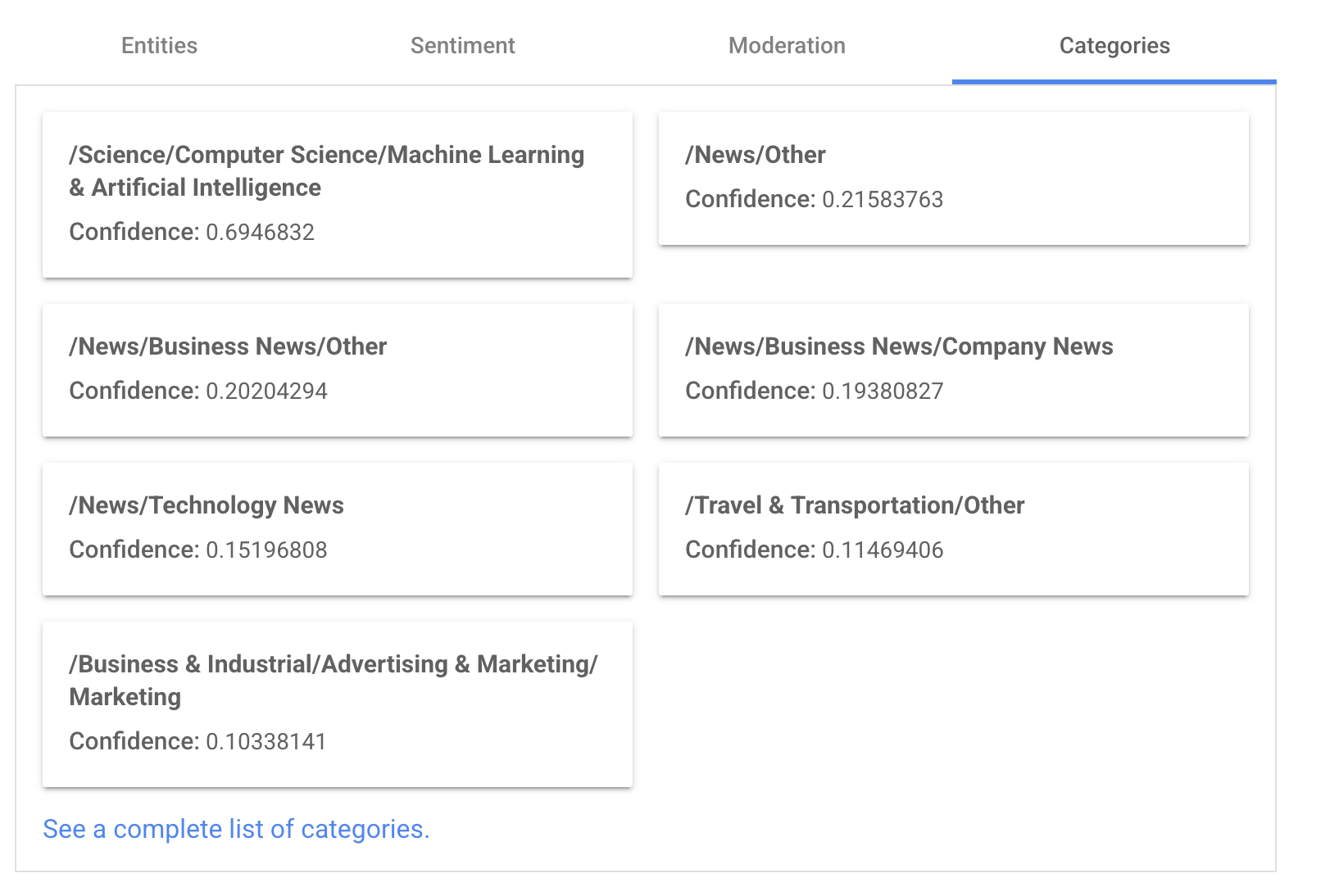
Classification
- scoring de sentiment
- catégories
- Modération
POS : part of speech et dependency tagging
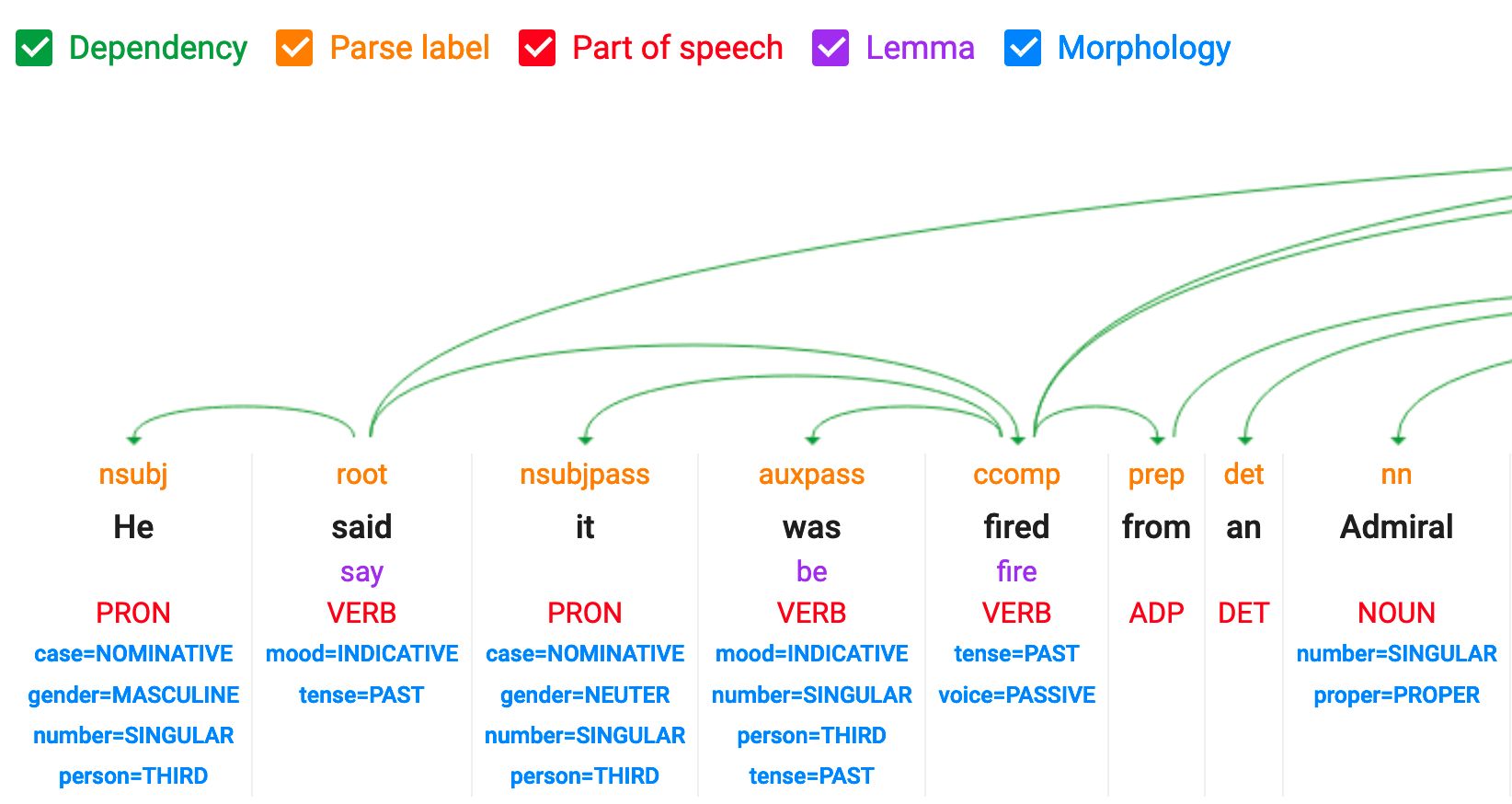
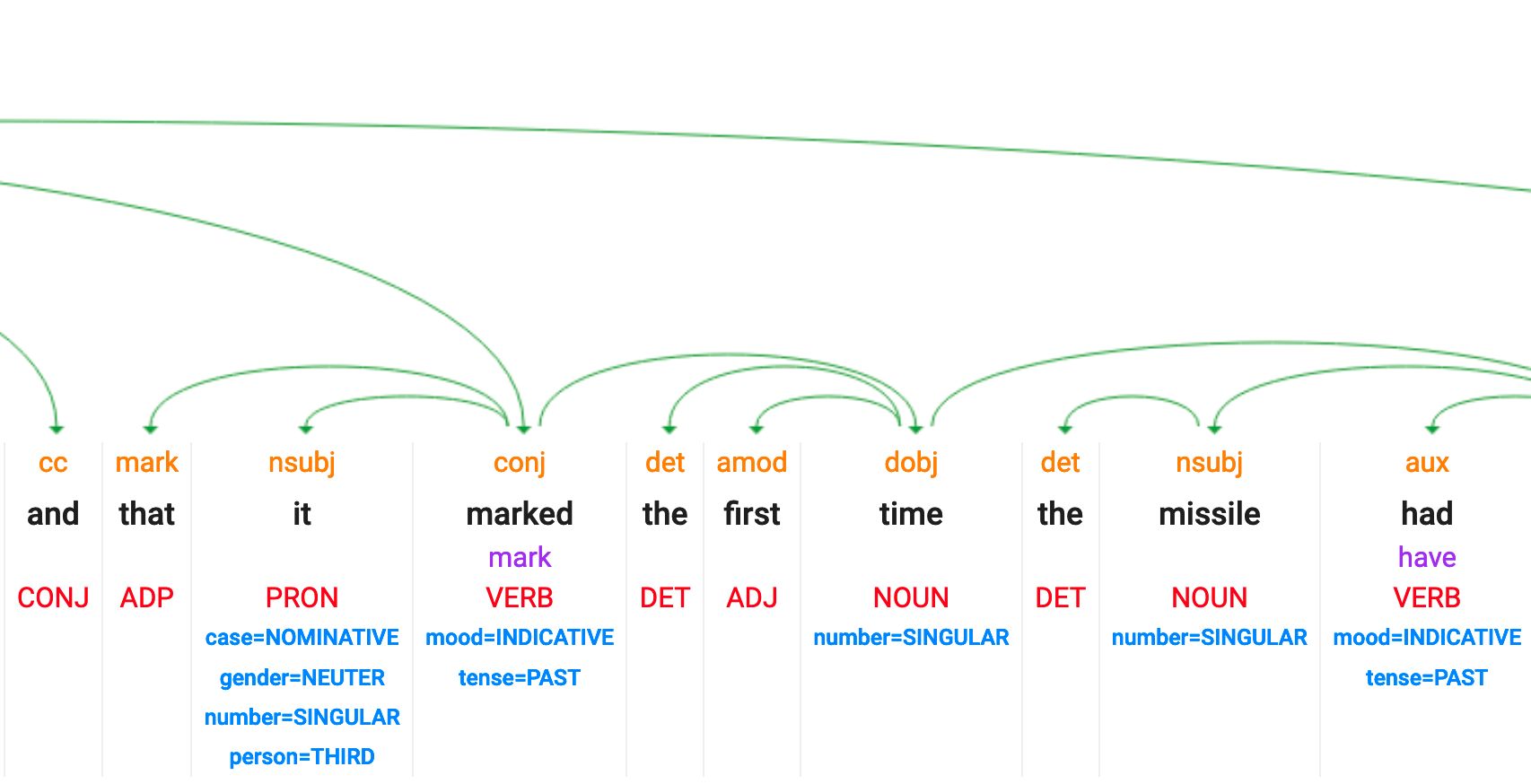
Malheureusement, cette fonctionnalité n'est plus disponible dans la démo NLP de Google.
Tokens et LLMs
- Context Window = mesuré en tokens, pas en mots : fenêtre de 1M tokens, fenêtre de 200k tokens, ...
- Pricing Model = coût par token (entrée + sortie)
- Texte non-anglais = plus de tokens nécessaires
- Token Limits = pourquoi les réponses sont coupées
- Tâches au niveau des caractères = difficiles (les LLMs voient des tokens, pas des lettres)
- L'efficacité varie = selon la langue, le domaine, la complexité
Tarification basée sur les tokens
https://openai.com/api/pricing/

NER et POS avec spacy.io
Il existe quelques importantes bibliothèques Python pour le NLP : Spacy.io et NLTK
Spacy.io supporte 75 langues,
- reconnaissance d'entités, étiquetage part-of-speech, analyse de dépendances, segmentation de phrases, classification de texte, lemmatisation, analyse morphologique, entity linking et plus
=> suivez Ines Montani (website) elle est super cool
Code Spacy
Pour utiliser Spacy.io nous devons
- installer et importer la bibliothèque
- puis télécharger un modèle associé à la langue du corpus.
- Chaque langue offre plusieurs modèles de tailles variables
- Chaque modèle est entraîné pour gérer POS et NER et la lemmatisation
- Une fois le modèle disponible, nous instancions l'objet spacy
docsur le texte que nous voulons analyser - puis nous pouvons facilement extraire les NER comme les lieux ou les personnes avec ces lignes simples
- De même, nous pouvons identifier tous les ADJ et NOUNS dans un texte
# pip install -U spacy
# python -m spacy download en_core_web_sm
import spacy
# Load English tokenizer, tagger, parser and NER
nlp = spacy.load("en_core_web_sm")
# Process whole documents
text = ("When Sebastian Thrun started working on self-driving cars at "
"Google in 2007, few people outside of the company took him "
"seriously. "I can tell you very senior CEOs of major American "
"car companies would shake my hand and turn away because I wasn't "
"worth talking to," said Thrun, in an interview with Recode earlier "
"this week.")
# instanciate the spacy object
doc = nlp(text)
# Analyze syntax
print("Noun phrases:", [chunk.text for chunk in doc.noun_chunks])
print("Verbs:", [token.lemma_ for token in doc if token.pos_ == "VERB"])
# Find named entities, phrases and concepts
for entity in doc.ents:
print(entity.text, entity.label_)
Pratique
Construire un dataset en utilisant l'API NYT
API NYT
Offre un accès gratuit : developer.nytimes.com/apis
suivez les instructions sur developer.nytimes.com/get-started
- ouvrez un compte sur le site développeur du NYT
- créez une application
- obtenez une clé API

API NYT - Pratique
https://colab.research.google.com/drive/1PoFhONvZZxcpIG-_XMoN9wKTT1U7KS7X#scrollTo=aJVkXUfIFjqX
Objectif :
- choisir un sujet, un ensemble d'articles
- construire un dataset d'articles
- extraire les entités, noms, verbes, adjectifs en utilisant spacy.io
- et aussi sauvegarder le dataset sur votre ordinateur portable