NLP
Natural Language Processing
Style moderne
NLP moderne - Embeddings
Le problème : comment trouver des textes similaires ?
Dans un large corpus, comment trouver des phrases, des paragraphes qui traitent de sujets similaires ?
Ou dit autrement, comment calculer une distance entre 2 textes qui conservent le sens des textes, distance sémantique?
Distance
Comment calculer une distance entre 2 textes pour pouvoir dire que
bananeest plus proche depommequ'il ne l'est deavion;le chien aboieest plus proche dele chat miaulequ'il ne l'est del'avion décolle, …
Avant 2013 : compter les mots et leurs fréquences relatives La méthode, rudimentaire, appelée tf-idf, fonctionnait bien pour la détection de spam, nécessite beaucoup de pré-traitement de texte (stopwords, lemmatization, ...). OOV, ne peut pas passer à l'échelle pour de grands vocabulaires, sensible aux fautes de frappe, etc etc
Word2vec 2013
Thomas Mikolov @Google Efficient Estimation of Word Representations in Vector Space
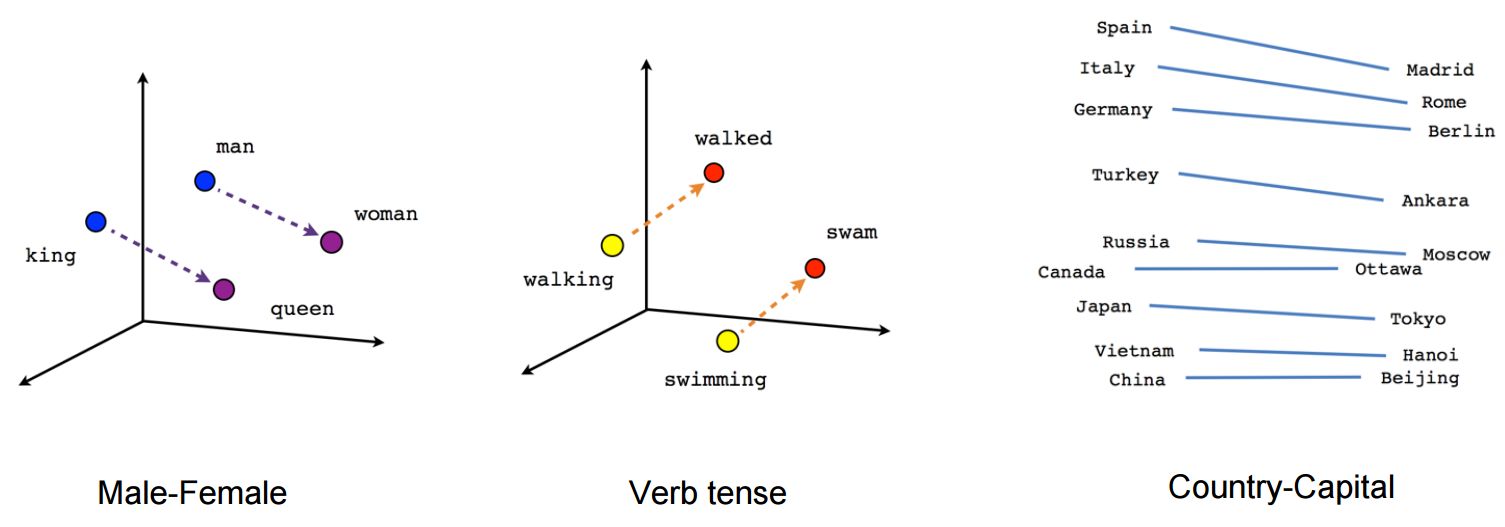
Distance sémantique de mots similaires
France + capital = Paris
Germany + capital = Berlin
mais toujours pas de désambiguïsation contextuelle : les vers de terre = je vais vers la table.
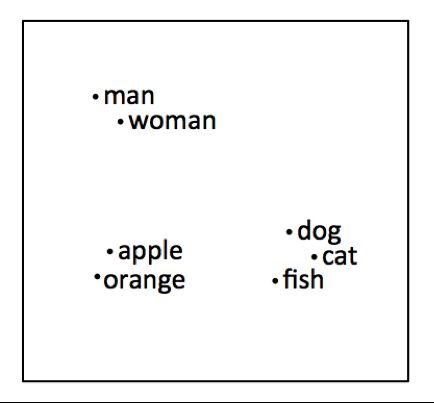
word2vec 2013
Chaque mot est un vecteur de grande dimension
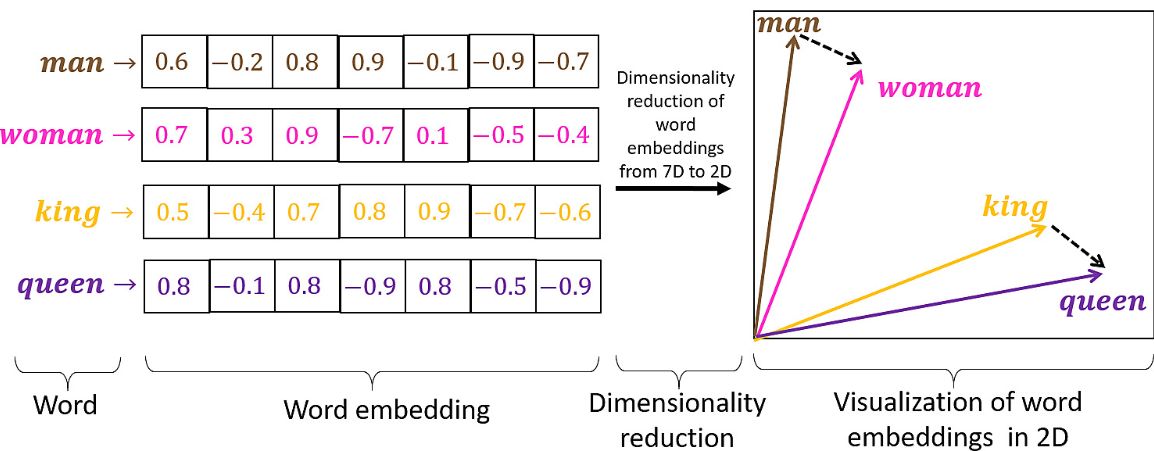
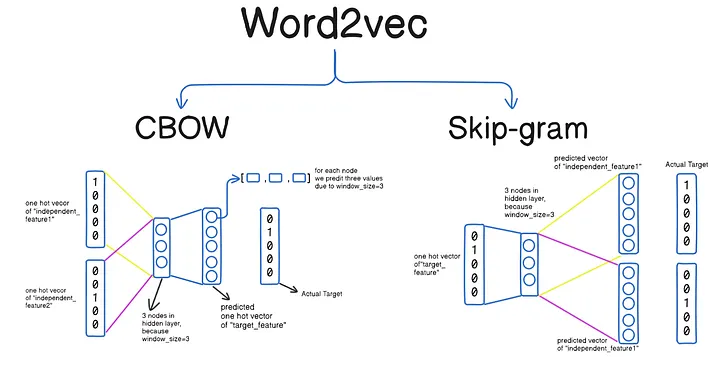
CBOW vs skip-gram
- CBOW (Continuous Bag-of-Words): Predict the target word (center word) from the surrounding context words.
- skip-gram: Predict the context words from the target word (center word).
Cosine similarity
Une fois que vous avez les embeddings (vecteurs, séries de nombres) de 2 textes (phrases, mots, tokens, ...), leur distance est donnée par la similarité cosinus de leurs embeddings
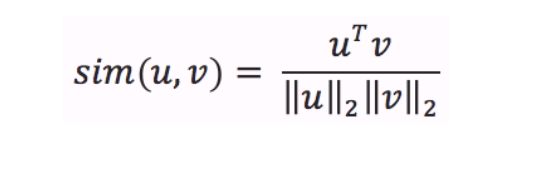
Word2Vec (2013)
- Static embeddings : chaque mot = 1 vecteur fixe
- Pas de contexte : "avocat" (fruit, profession) → même vecteur
- Capture la similarité (king - man + woman ≈ queen)
- Basé sur la co-occurrence des mots
- Shallow neural network (1-2 couches)
Évolution des Word Embeddings
BERT/GPT (2018+)
- Contextual embeddings : même mot = vecteurs différents selon le contexte
- "bank of the river" vs "bank account" → vecteurs différents
- Utilise les Transformers et le mécanisme d'attention
- Capture le contexte dans les deux directions (BERT) ou unidirectionnel (GPT)
- Deep neural networks (12-96 couches)
Comment le contexte sémantique est préservé ?
Mécanisme d'attention
- Chaque mot "regarde" tous les autres mots de la phrase
- Calcule des scores d'attention : quels mots sont importants pour comprendre ce mot
- Exemple : "The cat sat on the mat"
- "sat" prête attention à "cat" (qui fait l'action) et "mat" (où)
Positional encoding
- Ajoute l'information de position dans la phrase
- Permet de distinguer "Le chien mord l'homme" vs "L'homme mord le chien"
Layers empilées
- Chaque couche capture des relations plus abstraites
- Couches basses : syntaxe
- Couches hautes : sémantique complexe

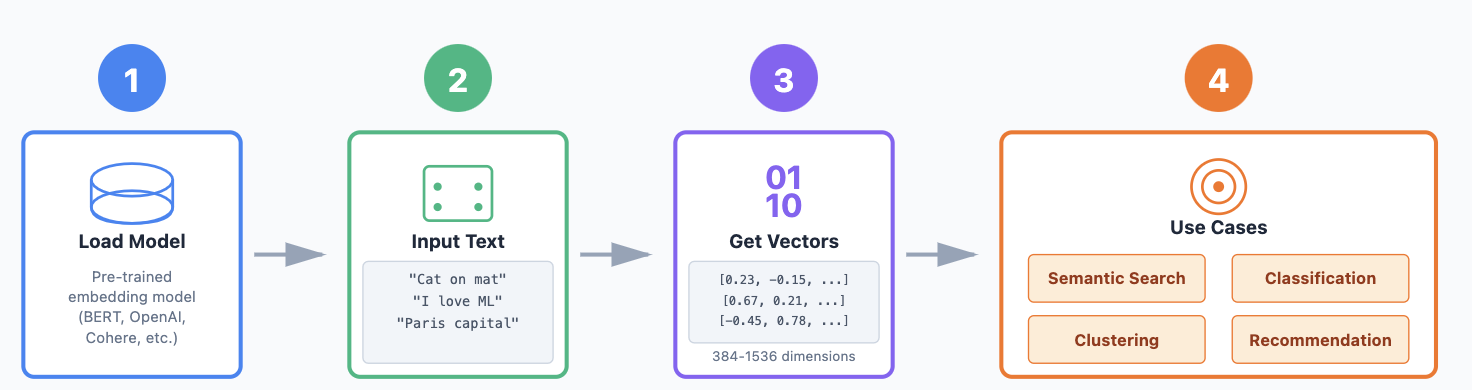
Exemple de workflow :
- Charger un modèle d'embedding pré-entraîné.
- Passer les phrases dans le modèle.
- Obtenir un vecteur de dimension N (embedding) pour chaque phrase.
- Utiliser ces embeddings pour la tâche en aval.
Embeddings spécialisés
Différentes entreprises optimisent pour différentes priorités—facilité d'utilisation, support multilingue, expertise de domaine, ou reduction des coûts !
Principales entreprises de modèles d'Embedding
OpenAI – Embeddings polyvalents, usage général
- Spécialité : Embeddings de texte de haute qualité qui fonctionnent dans de nombreux domaines
- Focus : API facile à utiliser, performance solide prête à l'emploi
- Modèles populaires : text-embedding-3-small, text-embedding-3-large
Cohere – Embeddings multilingues, orientés entreprise
- Spécialité : Excellente recherche sémantique et support multilingue (100+ langues)
- Focus : Applications business, RAG (Retrieval Augmented Generation)
- Caractéristique remarquable : Embeddings spécialisés pour différents cas d'usage (recherche, classification)
Voyage AI – Embeddings personnalisables, spécifiques au domaine
- Spécialité : Embeddings adaptés à des industries spécifiques (finance, juridique, santé)
- Focus : Précision maximale grâce à l'adaptation au domaine
- Approche : Modèles fine-tunés qui comprennent la terminologie spécialisée
Jina AI – Embeddings multimodaux et open-source
- Spécialité : Embeddings texte, image et cross-modaux
- Focus : Solutions adaptées aux développeurs, personnalisables, économiques
- Caractéristique remarquable : Embeddings à contexte long (8K+ tokens)
Google (Vertex AI) – Embeddings intégrés et évolutifs
- Spécialité : Intégration transparente avec l'écosystème Google Cloud
- Focus : Échelle entreprise, modalités multiples
- Modèles : Gecko (texte), embeddings multimodaux
Ressources
- https://platform.openai.com/docs/guides/embeddings
- https://airbyte.com/data-engineering-resources/openai-embeddings
RAG : Retrieval Augmented Generation
La limitation du context window des LLMs
Les Large Language Models ont une context window—une limite sur la quantité de texte qu'ils peuvent traiter à la fois (typiquement 32K-200K tokens, soit ~25-150 pages).
Le défi :
- Votre entreprise a 10 000+ documents, des millions de pages de données
- Les LLMs ne peuvent pas tout lire en une fois—ça ne rentre pas dans la context window
- Sans les bonnes informations, les LLMs hallucinent ou disent "Je ne sais pas"
Comment RAG résout cela :
Avant RAG : Vous demandez : "Quelle est notre politique de retour pour l'électronique ?" Le LLM pense : "Je n'ai pas accès aux politiques spécifiques de cette entreprise... Je vais faire une supposition éclairée basée sur les pratiques courantes" ❌
Avec RAG :
- Votre question est convertie en embedding
- RAG recherche dans TOUS vos documents et récupère seulement les 3-5 pages les plus pertinentes (vos documents de politique de retour)
- Ces pages spécifiques sont insérées dans le prompt du LLM comme contexte
- Le LLM répond en se basant sur VOTRE politique réelle ✓
RAG agit comme un système de recherche intelligent qui trouve l'aiguille dans la botte de foin, puis donne SEULEMENT cette aiguille au LLM comme contexte. De cette façon, le LLM a toujours les bonnes informations pour répondre avec précision—sans avoir besoin de faire rentrer toute votre base de connaissances dans sa context window.
En résumé : RAG = Retrieval (trouver les bons docs) + Augmented (les ajouter au prompt) + Generation (le LLM crée une réponse à partir de ce contexte)
RAG : retrieval augmented generation

Principaux défis des systèmes RAG
Problèmes de chunking
- Trouver la bonne taille de chunk : trop petit perd le contexte, trop grand dilue la pertinence
- Des limites mal placées cassent le sens (diviser des tableaux, des phrases ou des blocs de code)
Qualité du retrieval
- Décalage sémantique : les mots de l'utilisateur ne correspondent pas à la terminologie des documents
- Échecs de classement : le document le plus pertinent n'apparaît pas dans les premiers résultats
Contrôle de version et fraîcheur
- Les documents obsolètes restent dans la base de données vectorielle
- Plusieurs versions d'un même document causent des réponses contradictoires
Limitations de contexte
- Le contenu récupéré dépasse la capacité de la context window du LLM
- Décider quels chunks inclure quand vous avez trop de résultats pertinents
Les hallucinations persistent
- Le LLM extrapole au-delà des documents récupérés
- Des sources contradictoires conduisent à des compromis inventés
Coût et latence
- Ré-embedder de grandes collections est coûteux
- Le retrieval ajoute 2-5 secondes au temps de réponse
Pratique NLP classique et moderne
Sur l'API Wikipedia
- Construire un corpus sur l'API Wikipedia
- diviser le texte en phrases (en utilisant spacy.io)
- Extraire les personnes, les lieux en utilisant NER (en utilisant spacy.io)
- pour chaque phrase : obtenir les embeddings en utilisant la librairie huggingface transformers
- trouver des phrases similaires à partir d'un mot-clé ou d'une requête
- visualiser avec un graphe
Colab
https://colab.research.google.com/drive/1FT5hdlnj23c85CEYvaIc6nh4xDWu7VSW#scrollTo=cYFFIRy-6Ign
Pratique
-
extraire tous les NER dans une nouvelle colonne
-
extraire tous les adjectifs ou noms dans une nouvelle colonne
-
diviser la colonne de texte principale en phrases
-
construire un nouveau dataframe avec les phrases (garder une référence au dataframe original)
-
en utilisant la librairie huggingface transformers, construire des embeddings pour chaque phrase
-
étant donné un texte (mot, phrase, ...), trouver toutes les phrases qui lui sont les plus similaires