Demo : data backup
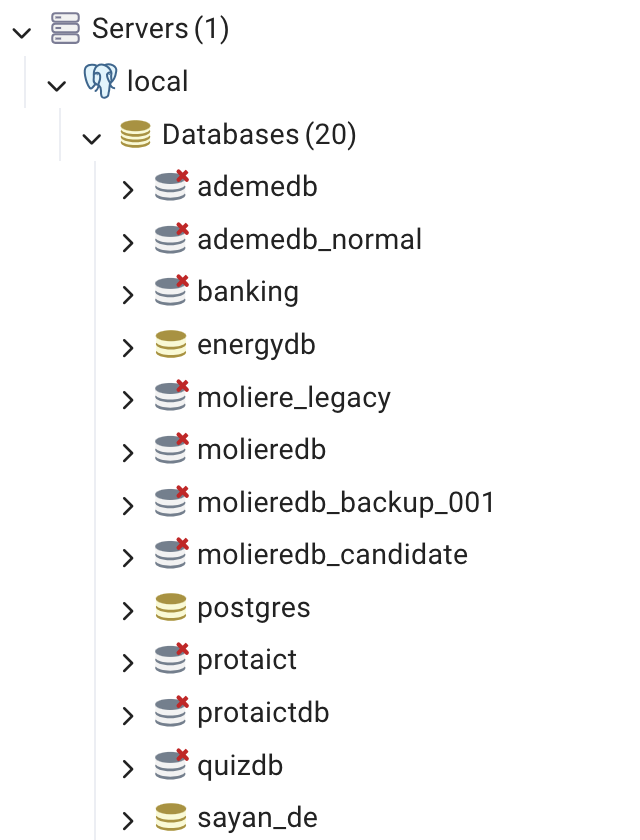
On my local, I have many databases
pgAdmin
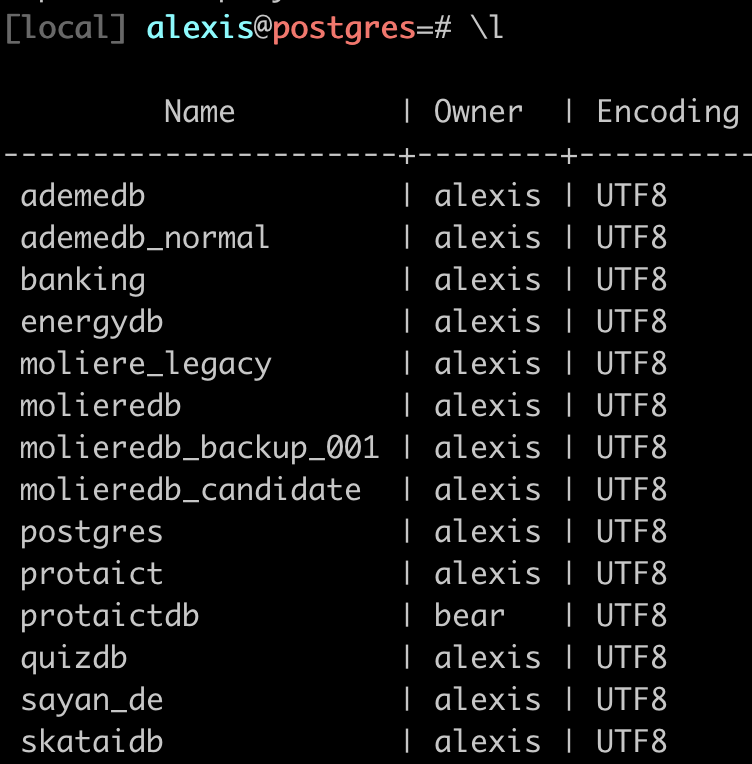
CLI : \l
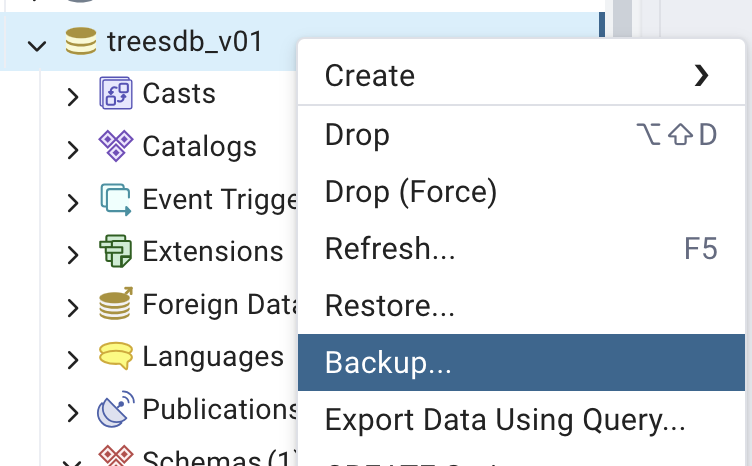
Let’s back up one of these, for instance the treesdb_v01 database
- Let’s name the backup file
treesdb_backup.pg_dump - Add a compression ratio from 1 to 9 (max) if you want to also compress your database. Then you should add
.gzto the filenametreesdb_backup.pg_dump.gzto indicate it is a commpressed file. - select
UTF-8for encoding. - for format : select plain (missing from the screenshot)
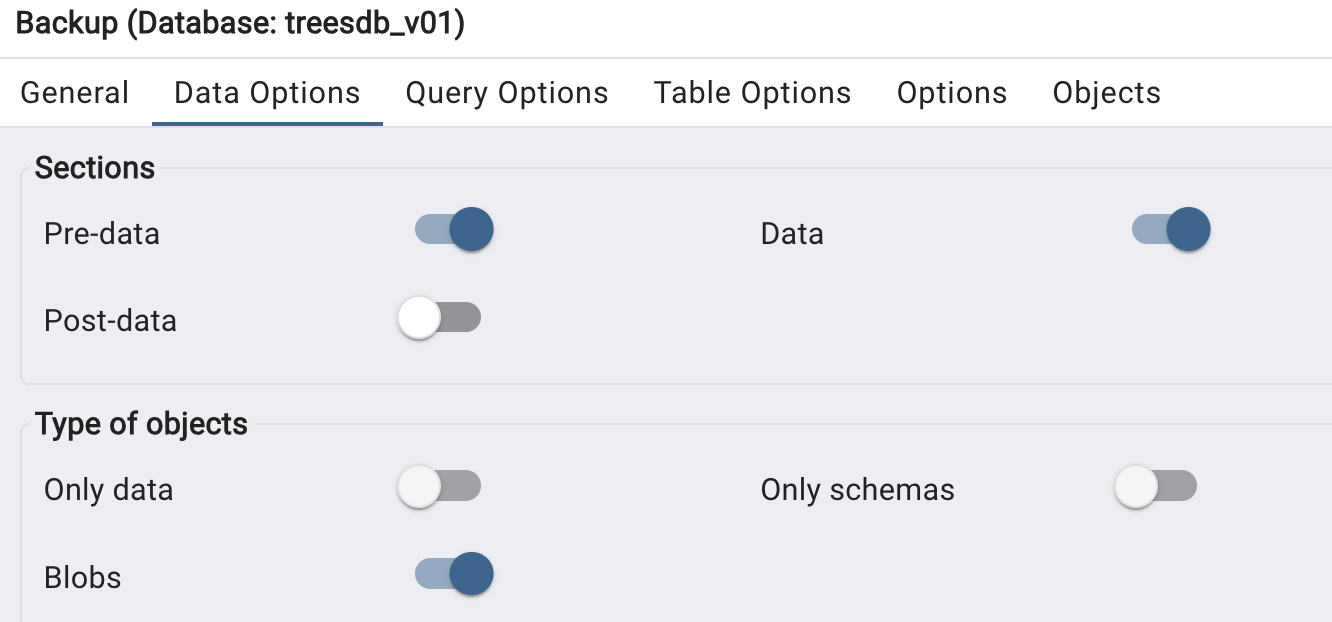
in the data options tab, select
pre data: includes the creation of the database and the userdata: includes the datablobs: includes all the data
in the “Query Options section”, select
- include Create database
- include DROP database
- include IF EXISTS
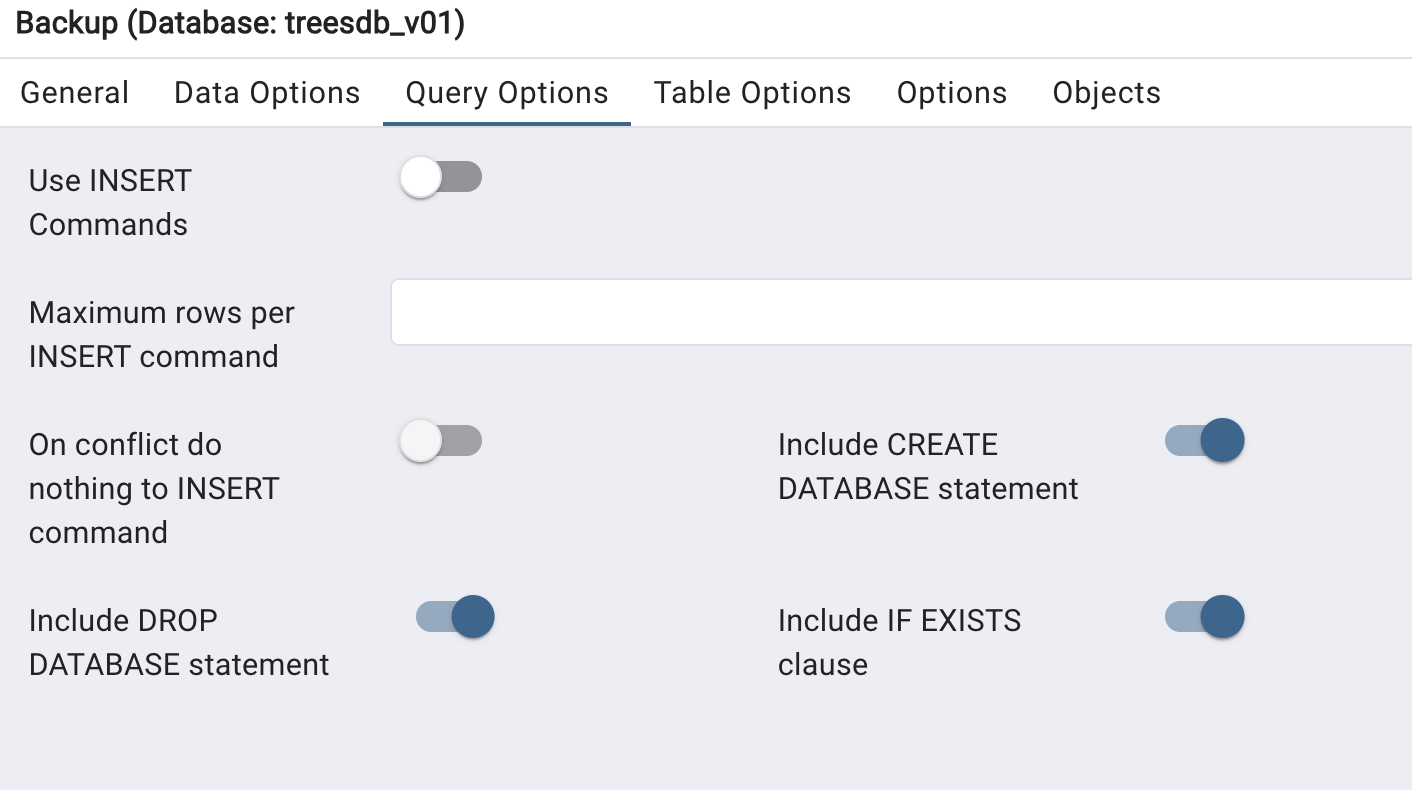
Nothing to do for the other tabs
and click Backup
Process
if we click on the process we see the CLI equivalent
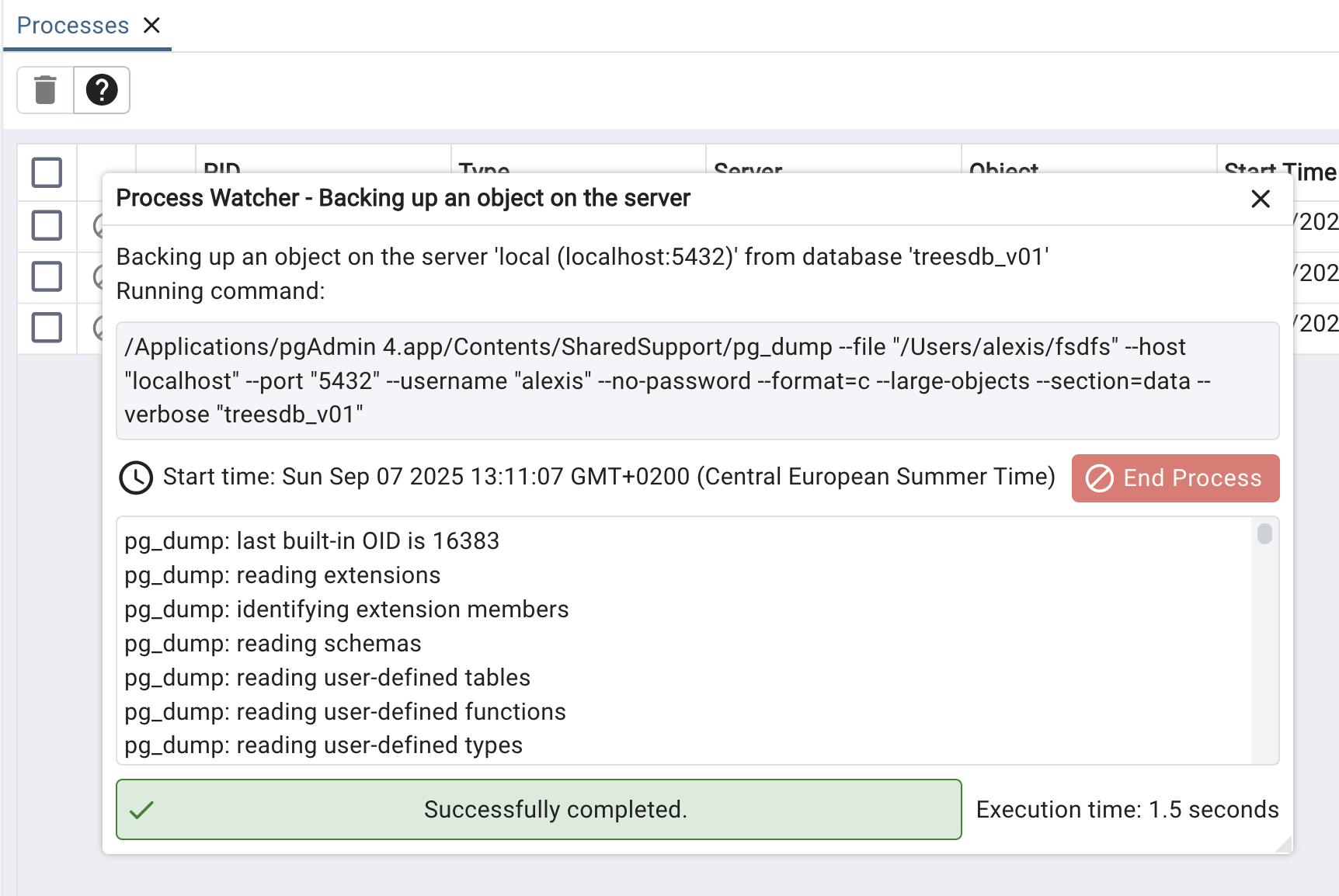
/<path>/pg_dump
--file "/Users/alexis/treesdb_backup.pg_dump"
--host "localhost" --port "5432" --username "alexis" --no-password
--format=p
--large-objects
--encoding "UTF8"
--section=pre-data
--section=data
--create
--clean
--if-exists
--verbose "treesdb_v01"
We can find all the settings that we selected in pgAdmin
I can copy paste that command into my terminal and it will / should work
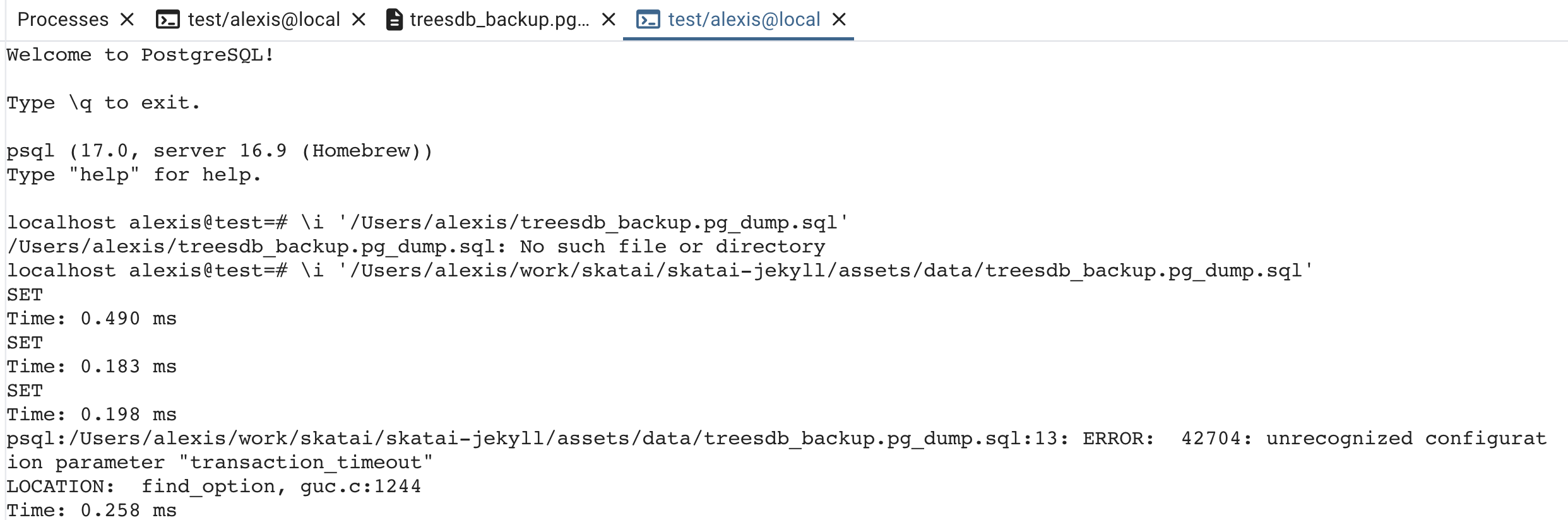
✅ run a sql file In pgAdmin
First rename your file from treesdb_backup.pg_dump to treesdb_backup.pg_dump.sql
pgAdmin won’t open the file when it does not have the .sql extension
Then to run a dump file or any SQL file:
- Select a database (
postgresis fine) - Open the Query Tool on your server/DB.
- Go to the File icon / Open and select your
treesdb_backup.pg_dump.sqlfile. - The contents load into the Query Editor.
- Press the Execute (▶) button to run it.
This will execute the SQL statements in your dump (including CREATE DATABASE if you included it).
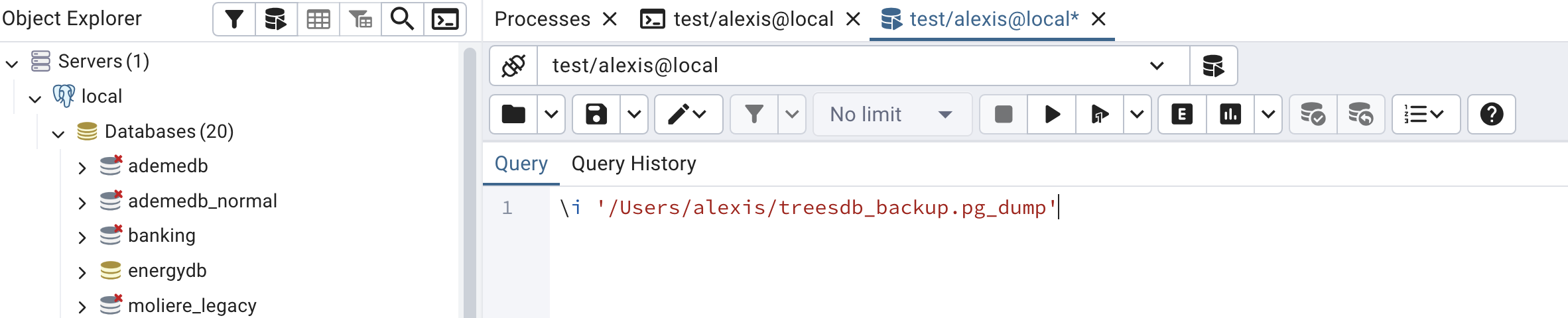
At this point you can simply use the PSQL tool in pgAdmin and run the above command
The titanic dataset is a classic dataset used in machine learning competitions

A list of the 891 passengers with their survival status, age, sex, class, fare, etc.
The kaggle competition is to predict the survival of the passengers based on their features.
Here we will just load the dataset into a database and review some basic SQL queries.
The goal of the exercise is to be able to import any csv dataset into a database.
sequence ?
Let’s check out the sequence
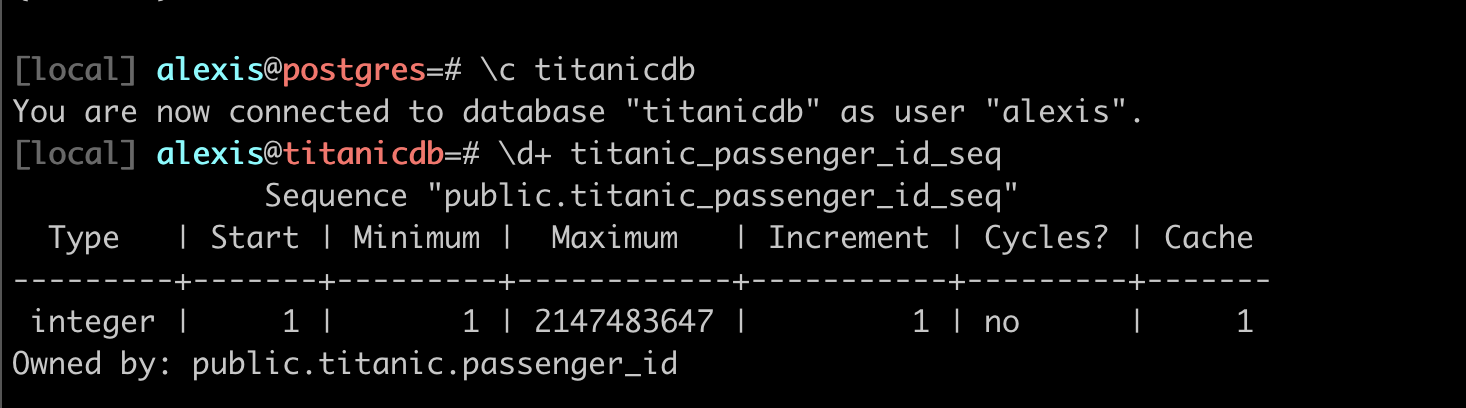
shows the behavior of the passenger_id serial number: from 1, increment 1, etc
Table
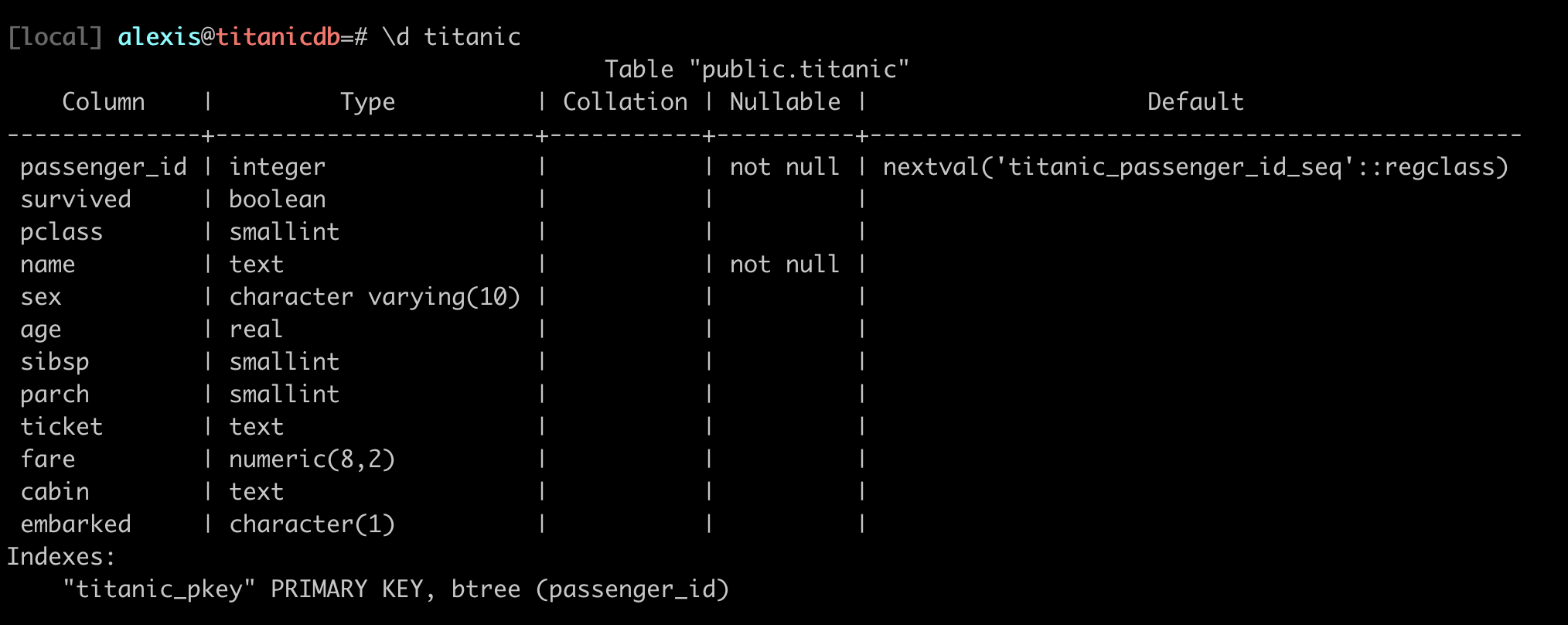
Notice in the last column.
nextval('titanic_passenger_id_seq'::regclass)
We can actually select the next value of the sequence
SELECT nextval('titanic_passenger_id_seq'::regclass);
Since our table is empty, this will return 1, then 2 etc