Promesses
Beaucoup de promesses d’efficacité de gain de temps.
En realité, un melange de savonette et de fadeur et d’experiences bluffantes.
Notion de jagged frontier.
- l’IA trebuche sur certaines taches evidentes pour un humain
- mais excelle et depasse les humains dans des domaines d’excellence
ce matin:


POS : part of speech et dependency tagging
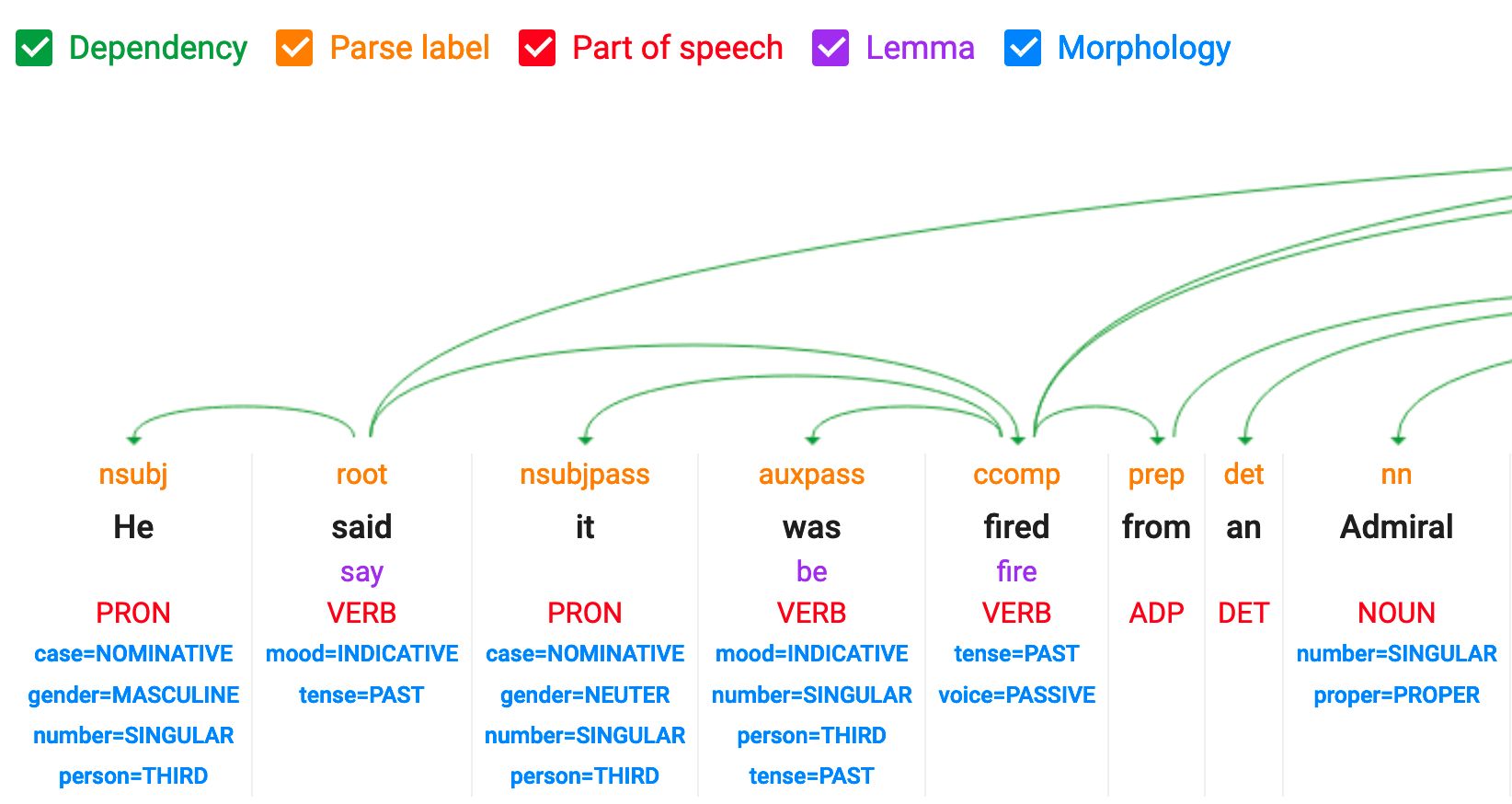
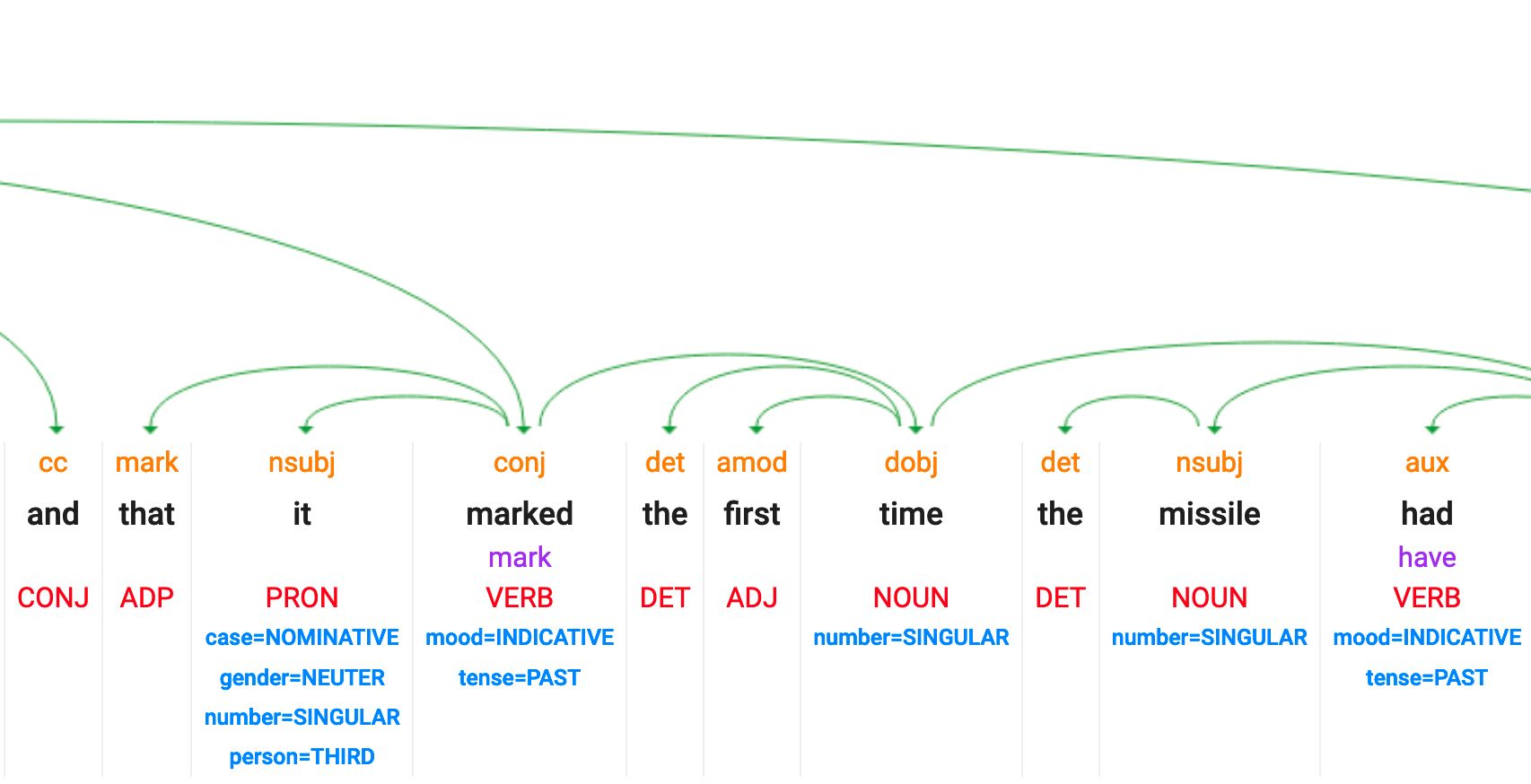
Malheureusement, cette fonctionnalité n’est plus disponible dans la démo NLP de Google.

Tokens, temperature
génération de texte :
- prediction du prochain token suivant une distribution de probabilité
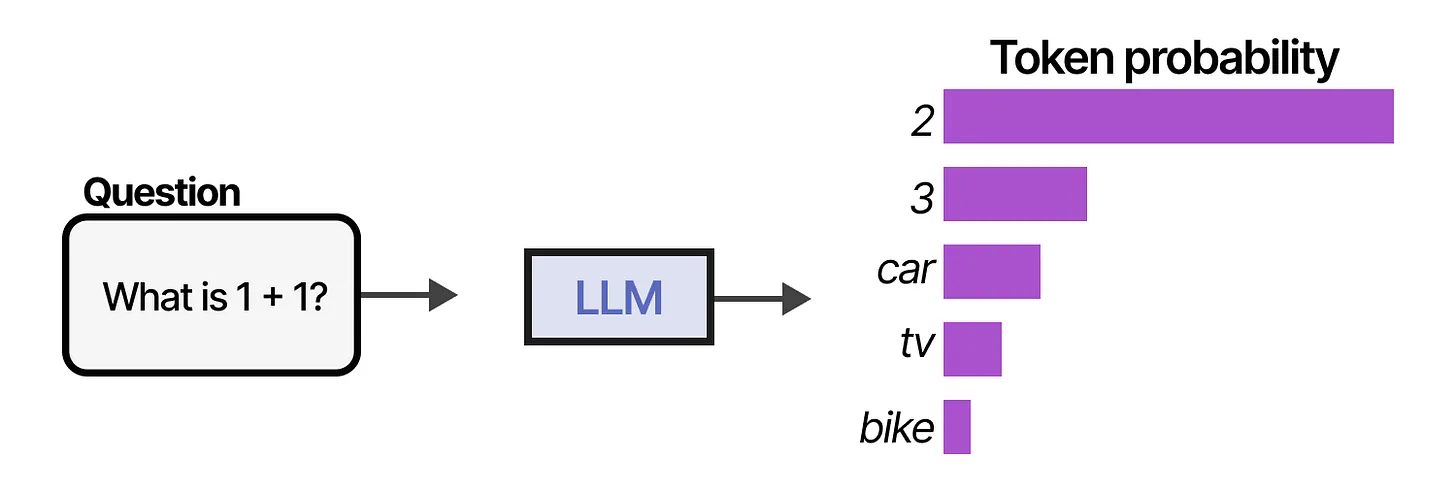
Autre exemple
Hier soir j’ai mangé
- de la pizza
- des broccoli
- des huitres
-
un camion
- fenêtre de contexte et tokens:
- 1 token ≈ 0.75 mot, 1 page ~200 a 300 mots,
- 1M tokens = 1.3 Guerre et Paix
- température : paramètre qui permet de changer la distribution de probabilité des tokens
- plus ou moins de créativité
- plus ou moins d’hallucinations
temperature = 0ne veut pas dire determinisme
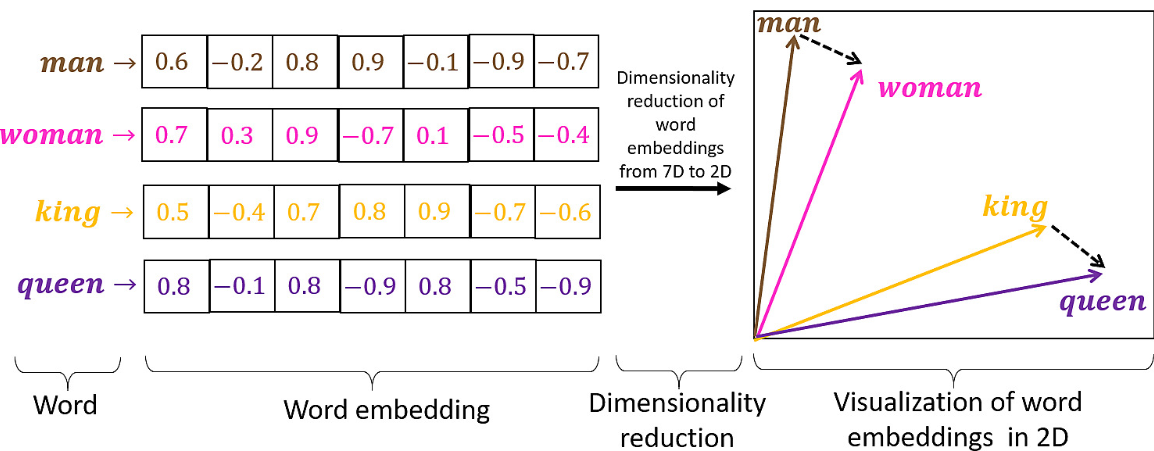
embeddings - vectorisation du texte
- texte -> vecteur
- cela donne une distance entre les textes qui respecte le sens des mots
- similarité sémantique :
d(chat, chien) < d(chat, banane) - il y a des modèles exclusivement dédiés à la création d’embeddings
Pléthore de modèles
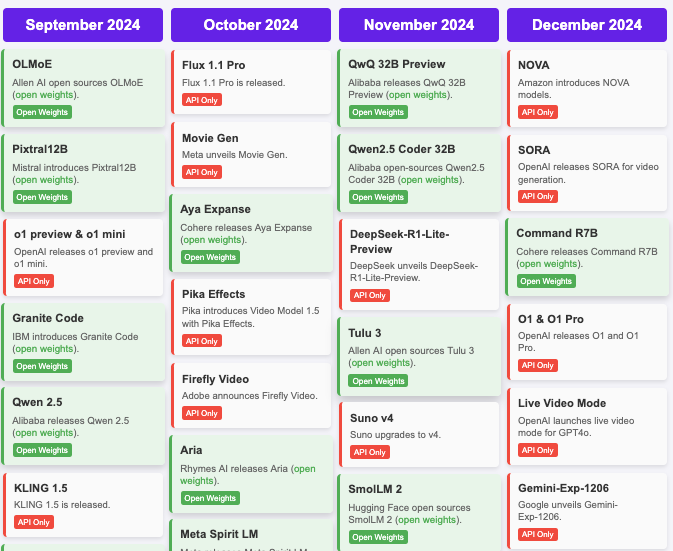
2024 AI Timeline - Hugginface release dashboards
Distinction majeure entre les modèles open source et closed source
Opensource vs Proprietaire: software
Open source:
- Le code est public : Linux
- Linux, OpenOffice, Firefox, Chromium, Python, grandes bases de données,
- Peut être copié et modifié par n’importe qui
![]()
Closed source:
- Le code n’est pas accessible.
- Windows, Word, Chrome, Edge, Oracle
- nécessite une licence pour utiliser, boîte noire

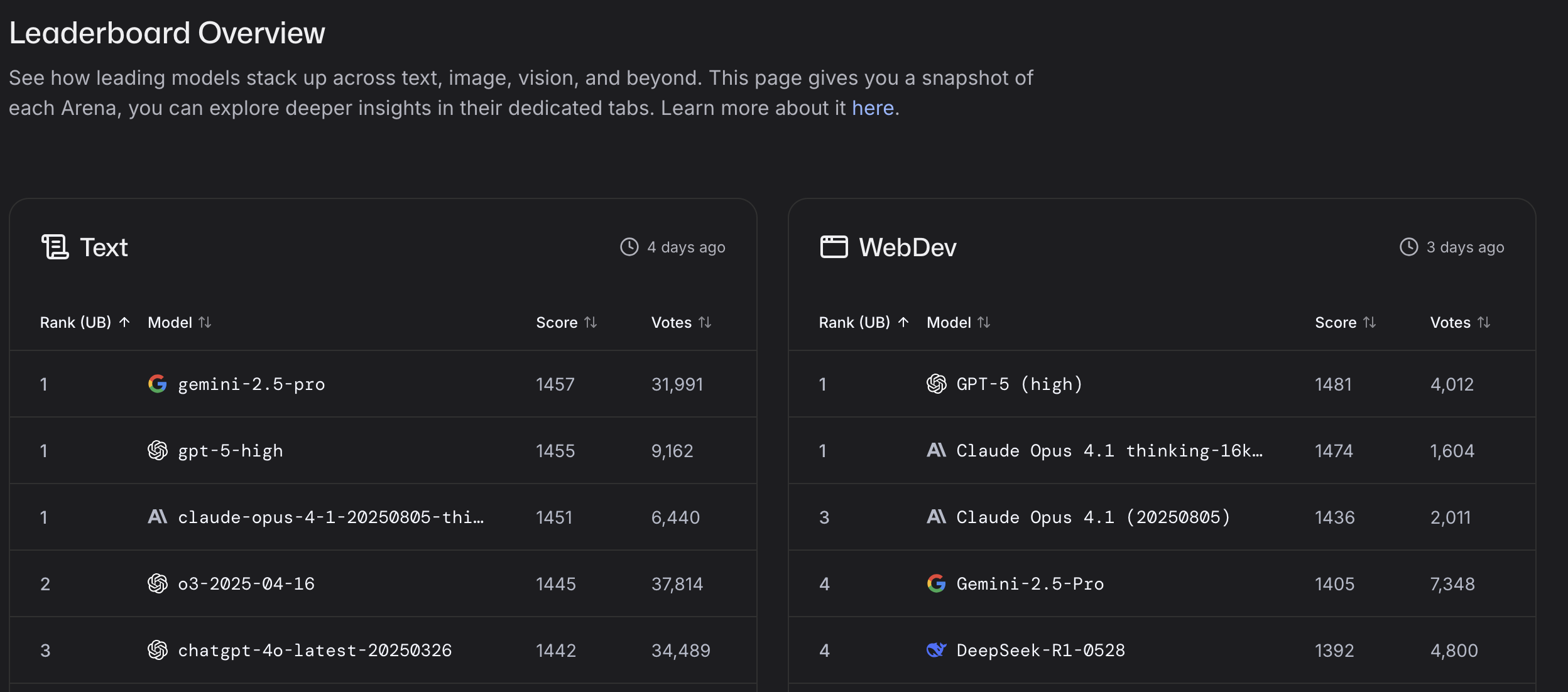
Artificial Analysis Intellligence Index
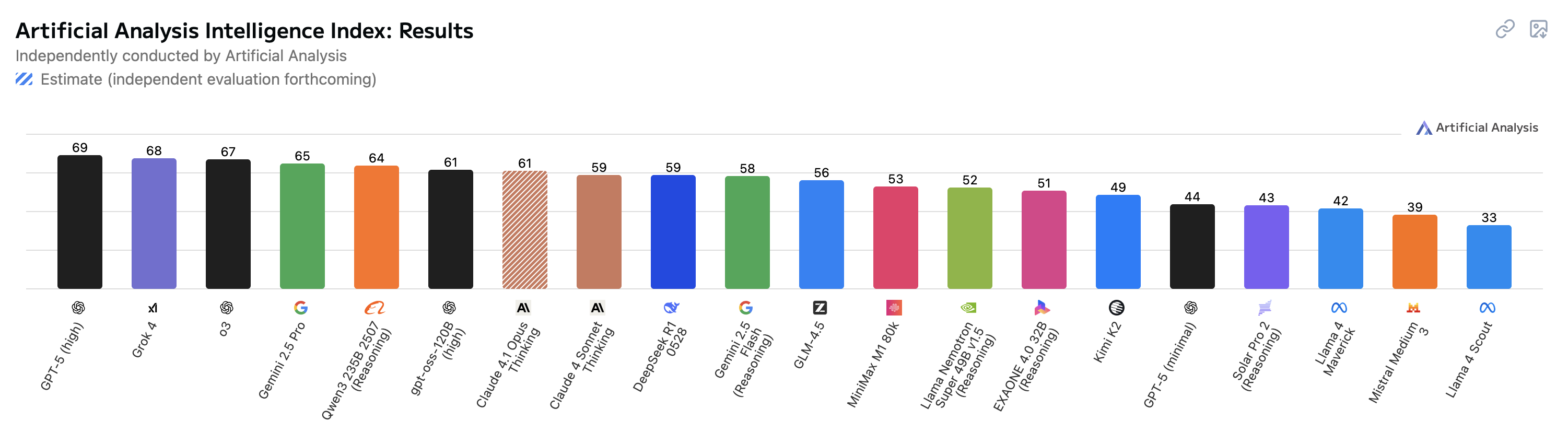
Artificial Analysis Intelligence Index combine les performances sur sept évaluations : MMLU-Pro, GPQA Diamond, Humanity’s Last Exam, LiveCodeBench, SciCode, AIME 2025, et IFBench.
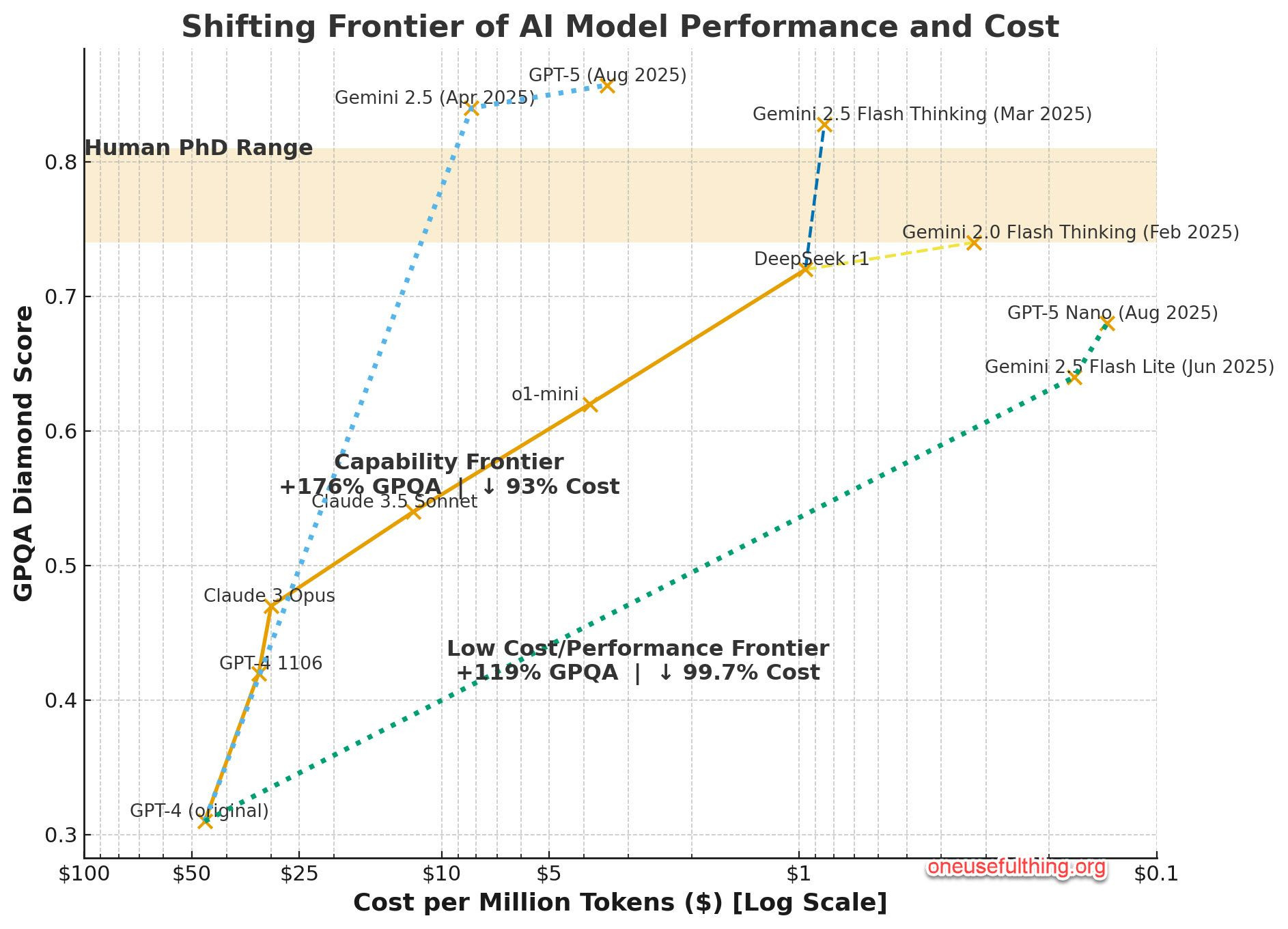
Score vs release date
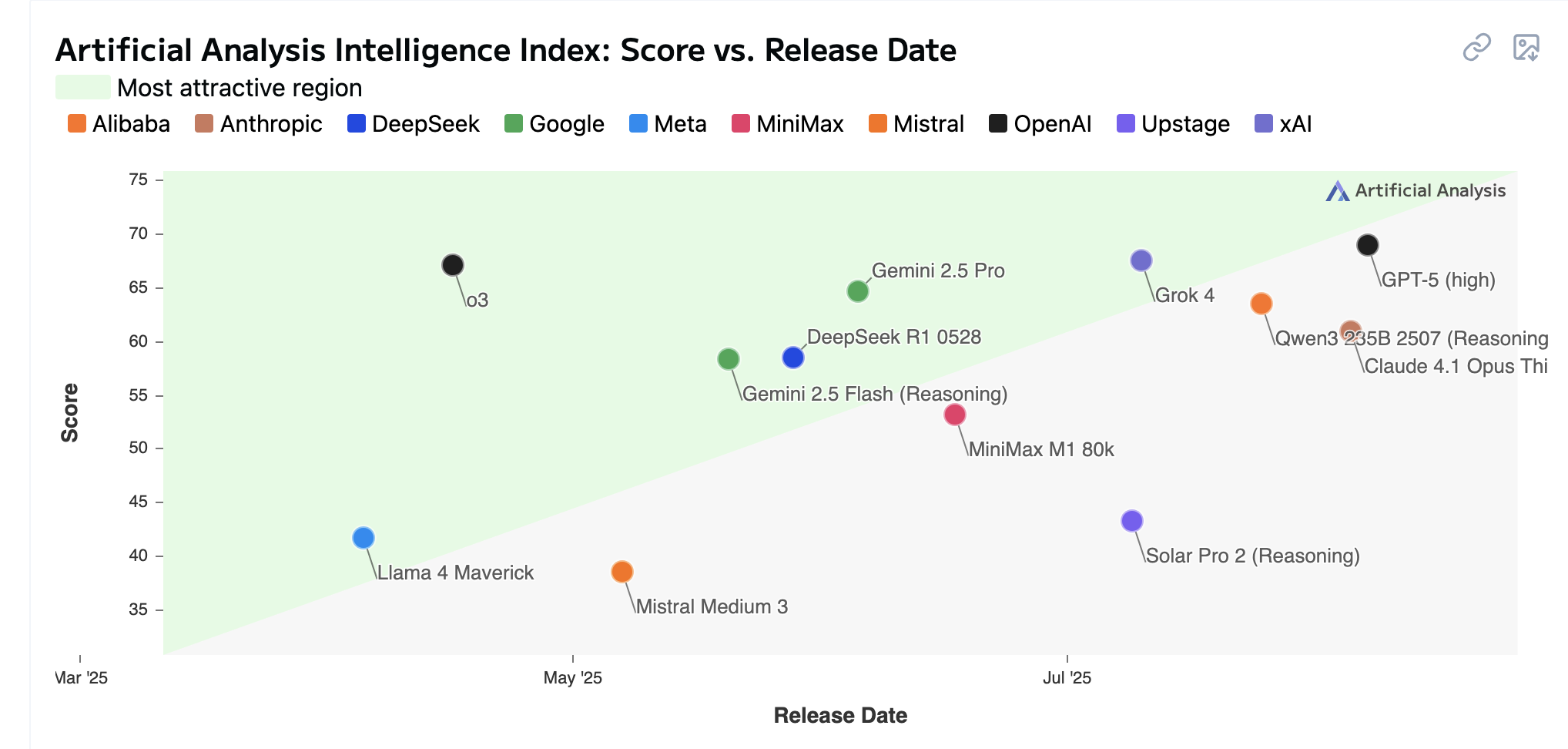
La course: open source vs propriétaires
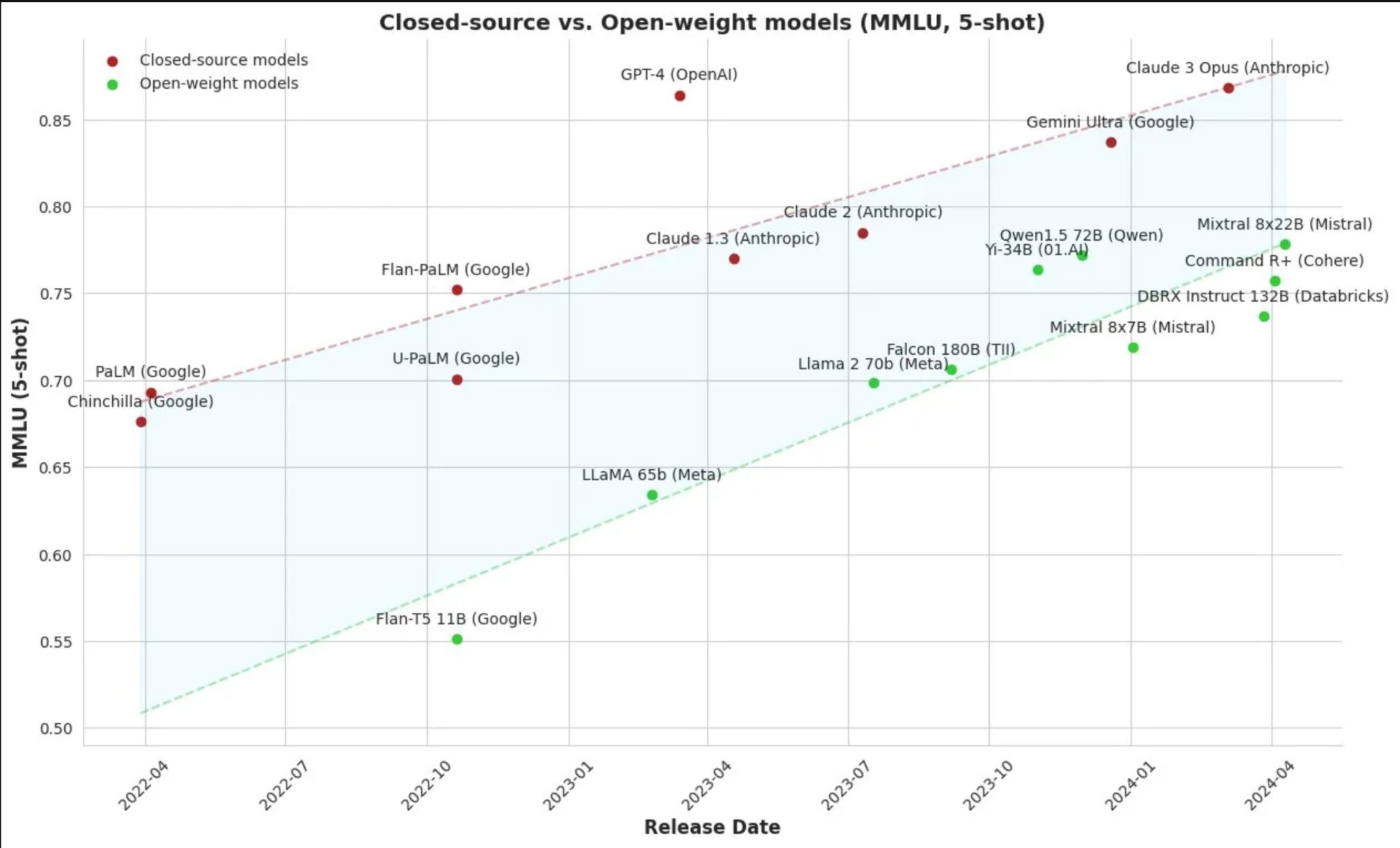
Les modèles open source rattrapent les modèles closed source
Performance vs Cost - 08/2025