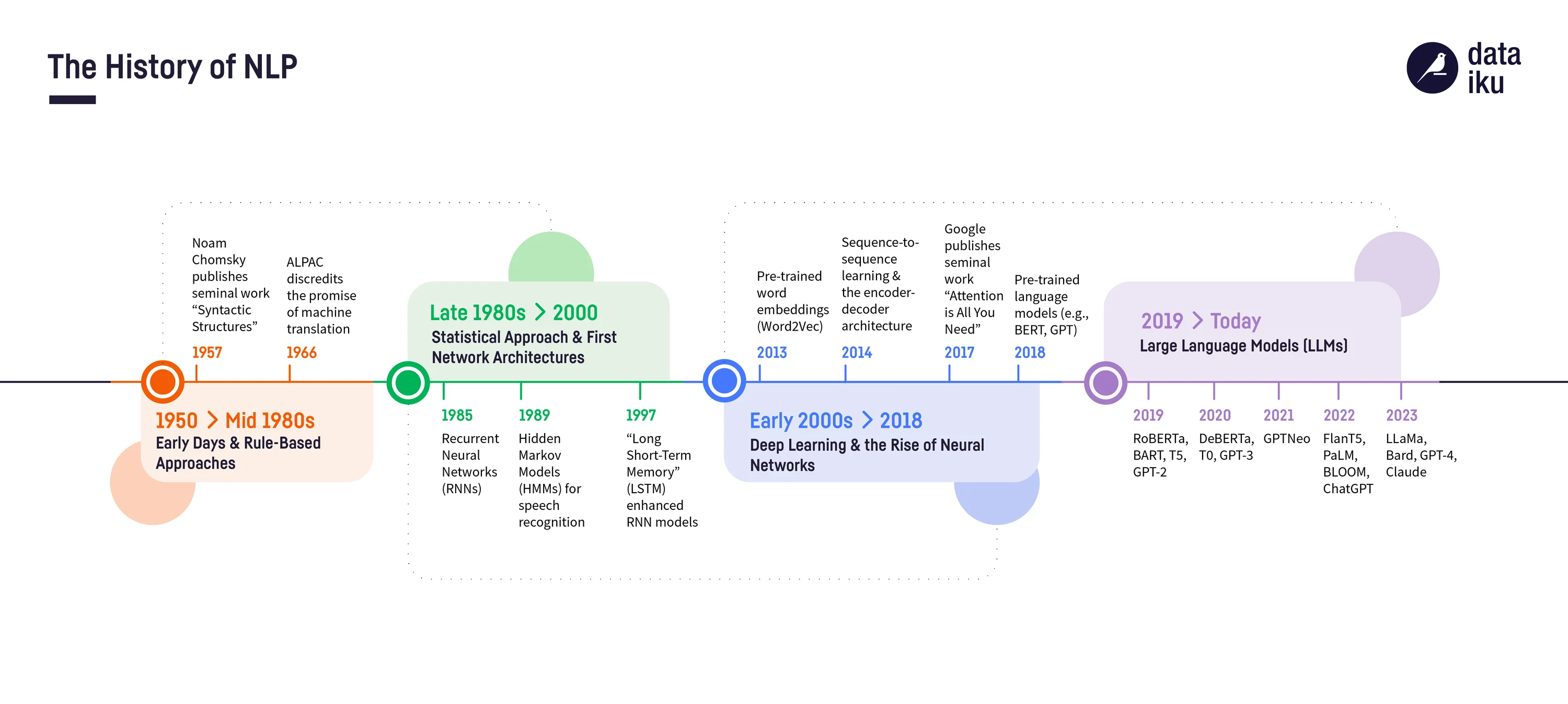
from Linguistic to NLP
Ferdinand de Saussure 1916

Linguistics is the scientific study of human language structure and theory
NLP (Natural Language Processing) is the computational field focused on building systems that can understand and generate human language.
Other classic refs
1957 Benveniste : Problemes de linguistique générale

1957 Chomsky : syntactic structures
The basis of Chomsky’s linguistic theory lies in biolinguistics, the linguistic school that holds that the principles underpinning the structure of language are biologically preset in the human mind and hence genetically inherited. He argues that all humans share the same underlying linguistic structure, irrespective of sociocultural differences.

Speech and Language Processing

Speech and Language Processing (3rd ed. draft) Dan Jurafsky and James H. Martin
Latest release: August 24 2025!!

NER: named entities recognition
All types of predefined entities: location, groups, persons, companies, money, etc
NER uses
- Pattern matching: Looks for capital letters, titles (Mr., Dr.), known entity lists
- Context clues: Words like “works at” suggest an organization follows
- Statistical models: Trained on labeled data to recognize entity patterns
NER models and rules are language specific

POS: part of speech tagging
Identify the grammatical function of each word : ADJ, NOUN, VERBs, etc
POS uses:
- Word endings: “-ing” often = verb, “-ly” often = adverb
- Position rules: Determiners (“the”) come before nouns
- Context: Same word can be noun or verb (“run” vs “a run”)
POS models and rules are also language specific

NER

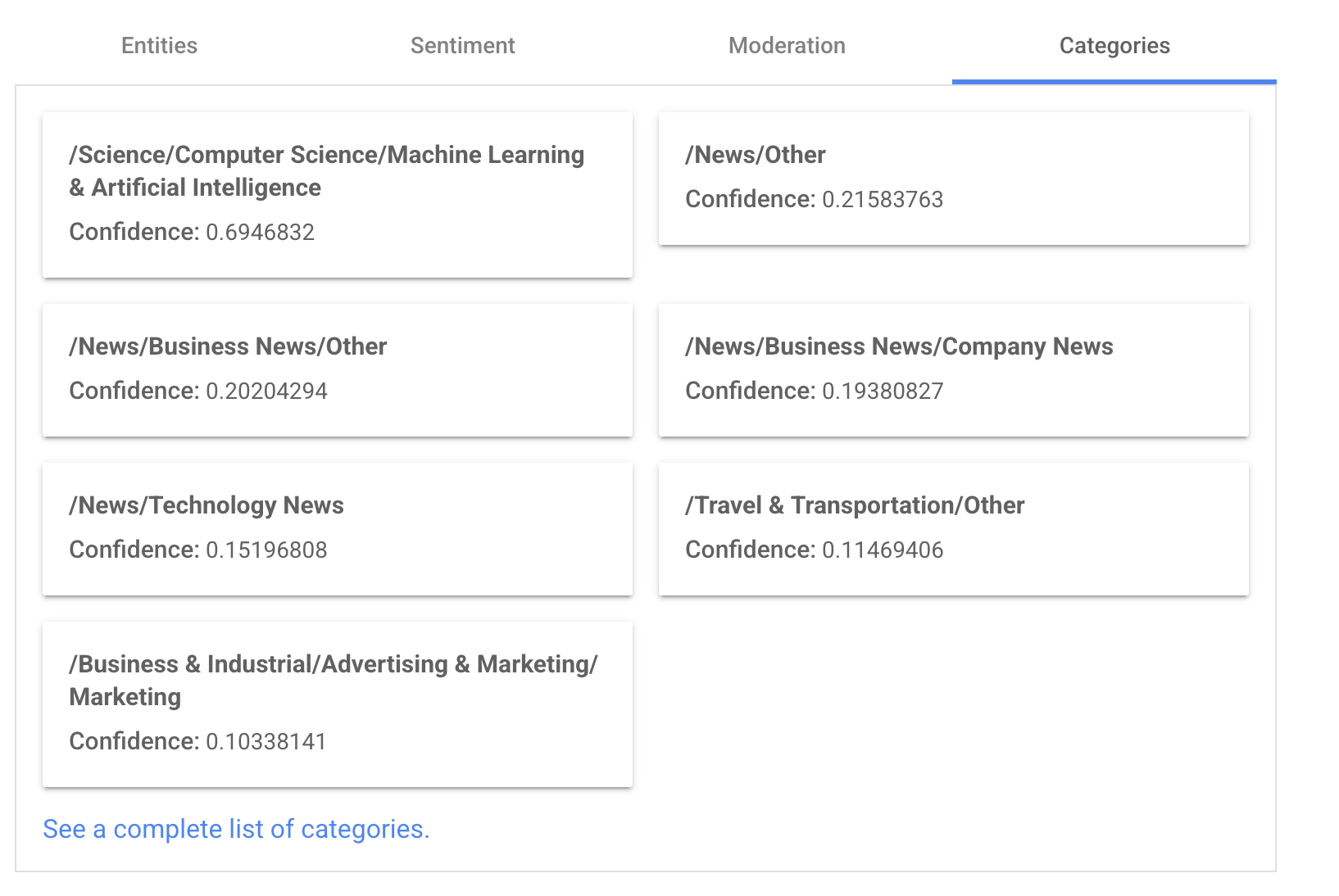
Classification
- sentiment scoring
- categories
- Moderation
POS : part of speech and dependency tagging
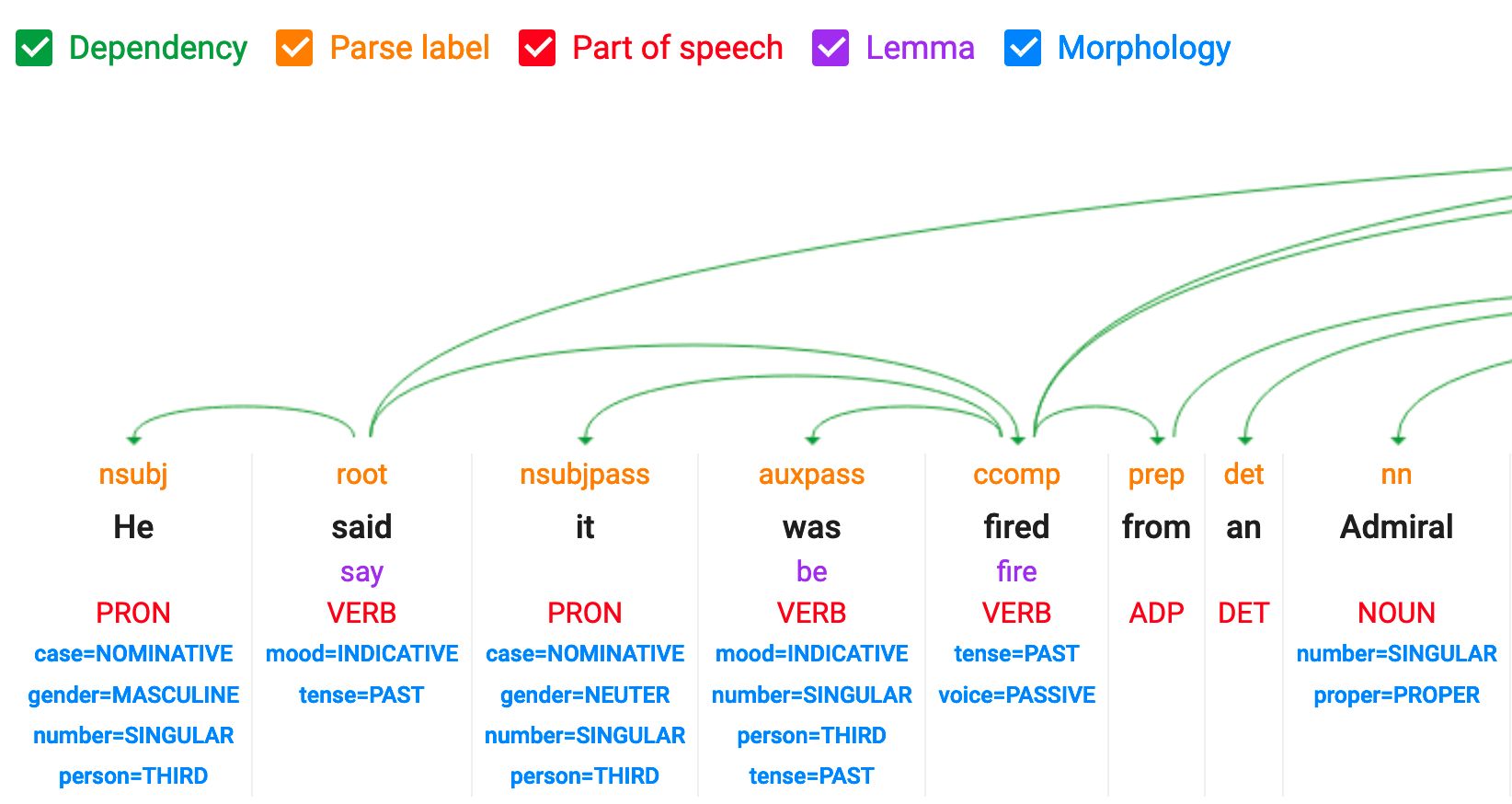
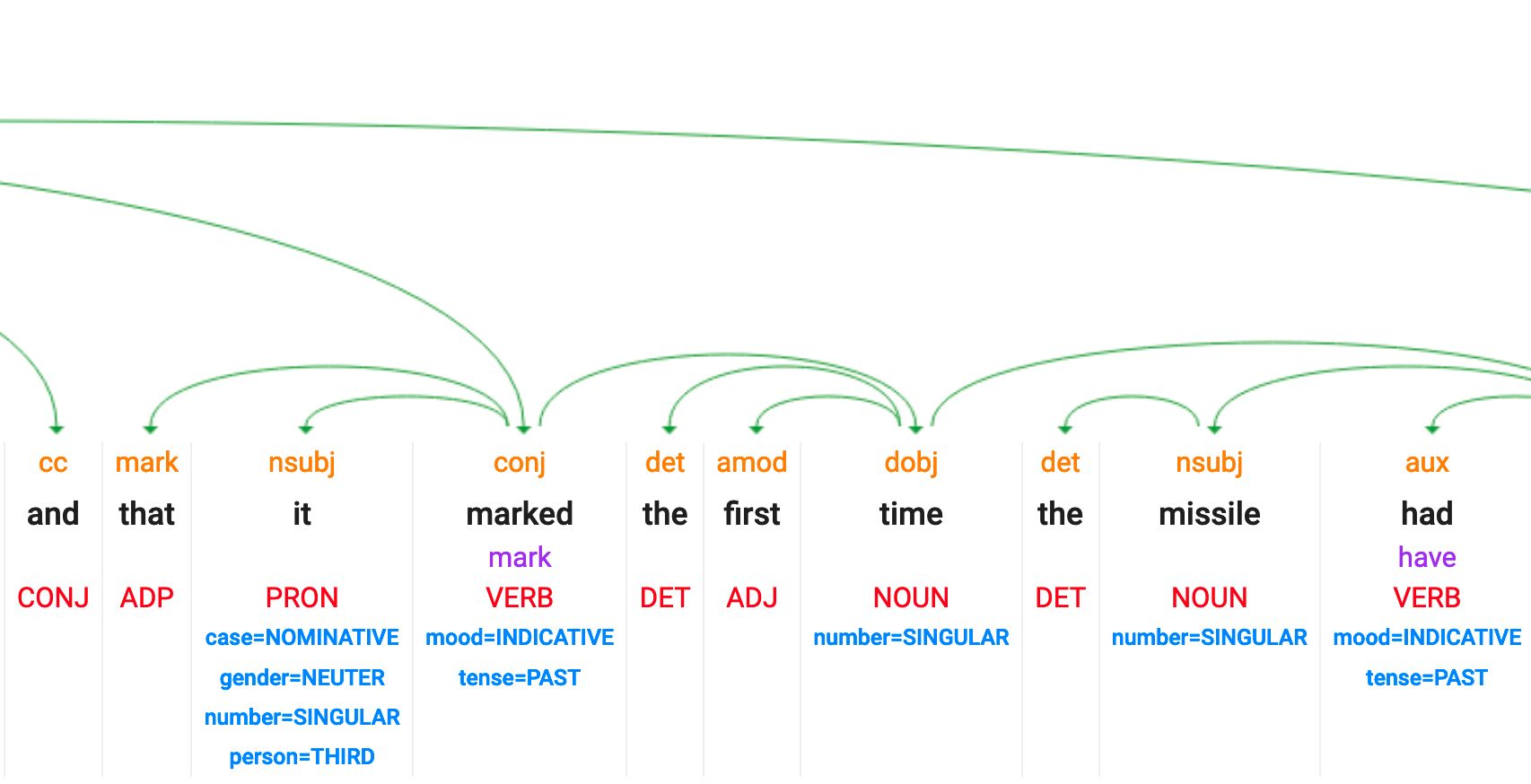
Unfortunately this features is no longer available in the NLP google demo.

NYT API
Offers free access: developer.nytimes.com/apis
follow instructions on developer.nytimes.com/get-started
- open an account on the NYT developer website
- create an app
- get an API key

An API key is SECRET
Public API keys cost lives and money, …,
ok, …., mostly money
DO not publish your API key publicly

see ref
Secret keys in google colab

left menu
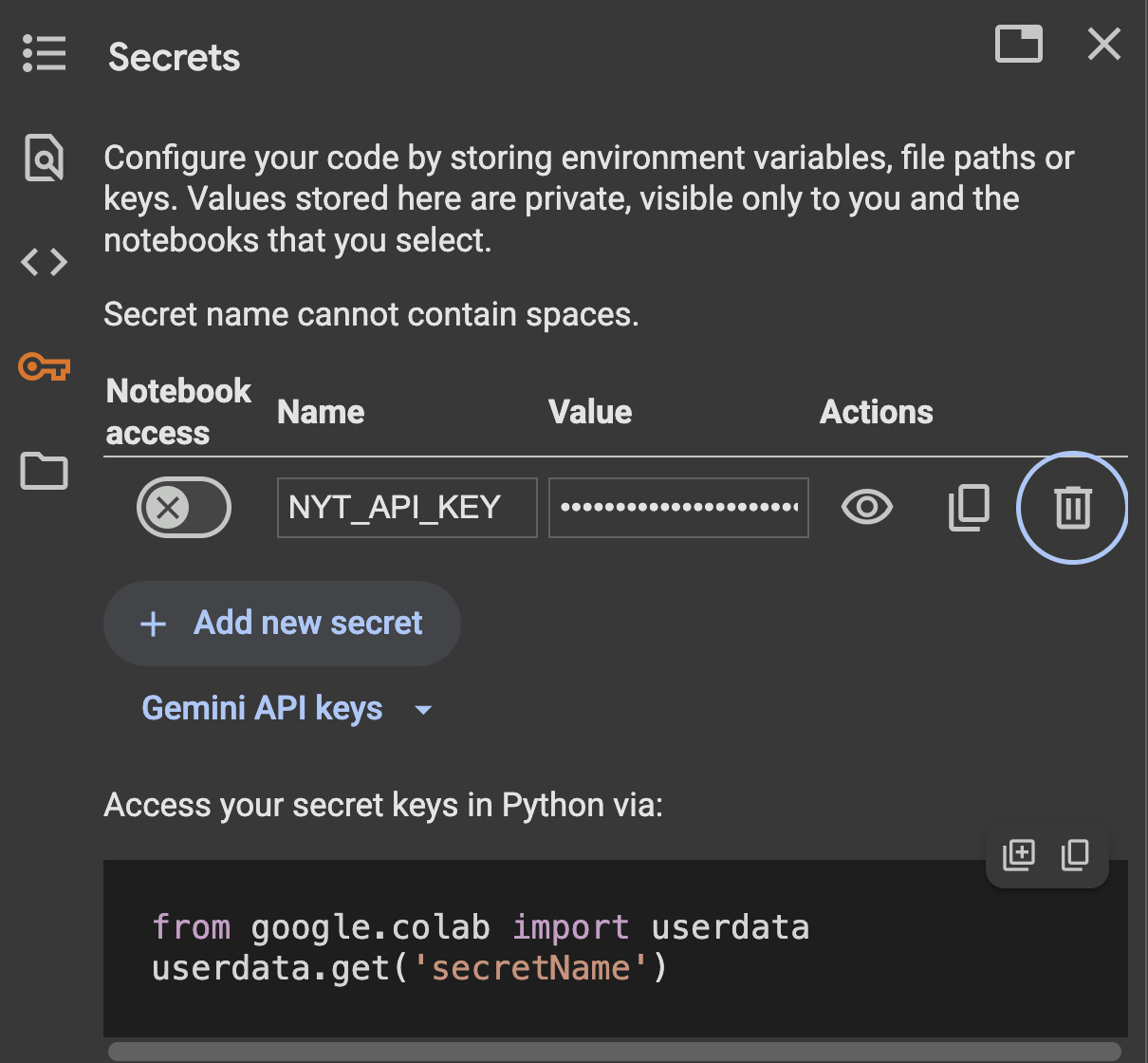
add key
