Fast Inference via APIs
What we saw last time
- from LLMs to Augmented LLMs to Agents
Any questions?
Today
We have used Gemini in google colab and web platforms (chatgpt.com, claude.ai etc )
We’re going to look at platforms for inference: groq, openrouter
The goal is to compare models on a simple task
Use a 3rd LLM to judge the outputs
At the end of this class
You
- use an LLM API to process data
- mix and match LLMs for different tasks
In the News
What caught your attention this week?
Inference
Inference
Inference in LLMs
Inference is the process of running a trained LLM to generate predictions or responses from input prompts - essentially the “thinking” phase where the model processes your request and produces output.
Key Points:
• What it is: Using a pre-trained model to generate text, not training it • Process: Input (prompt) → Model processing → Output (tokens/text) • Computational need: Requires significant GPU/TPU resources for each request
In Context of Groq & OpenRouter:
Groq: • Specialized inference hardware (LPU - Language Processing Unit) • Optimized for extremely fast token generation (up to 500+ tokens/second) • Focuses purely on inference speed, not training • Achieves low latency through custom silicon designed for LLMs
OpenRouter: • Inference routing service that connects to multiple LLM providers • Aggregates different inference endpoints (OpenAI, Anthropic, Meta, etc.) • Handles load balancing and failover between providers • You pay for inference compute across various models through one API
Inference
Bottom line: Inference is “running the model to get answers” - Groq makes it blazingly fast with custom chips, while OpenRouter gives you access to many different models’ inference endpoints through a single interface.
dataset
- use the European parliament dataset
- or your project dataset
see /Users/alexis/work/ncc1701/eu-scrape/data/debates_small.json for EU dataset
Groq
Open an account on groq
then go to
https://console.groq.com/
and create an API key
create a new google colab
add the API key to the colab (left side secret )
load the dataset into a pandas dataframe
Enriching data with LLMs
classic or modern NLP is mostly about
- classification: topic, detection, sentiment etc
- extractions of existing element : NER, POS
- unsupervised analysis: topic modeling
We can use an LLM to extract much richer information from text
Consider a corpus of verbatim debates, or online posts on a given topic, or articles or scientific papers.
| Category | Use Case | Description |
|---|---|---|
| Content Analysis & Extraction | Argument/claim extraction | Identify main arguments, supporting evidence, counterarguments |
| Entity recognition | Extract people, organizations, locations, events, concepts | |
| Relationship mapping | Identify connections between entities, ideas, or actors | |
| Quote attribution | Match statements to speakers/authors | |
| Topic modeling | Identify main themes and sub-topics | |
| Key points summarization | Extract main takeaways per document |
| Category | Use Case | Description |
|---|---|---|
| Semantic & Linguistic Annotation | Sentiment analysis | Positive/negative/neutral stance on topics |
| Emotion detection | Identify emotional tone (anger, joy, fear, etc.) | |
| Stance detection | Position on specific issues (pro/con/neutral) | |
| Rhetorical device identification | Metaphors, analogies, logical fallacies | |
| Writing style analysis | Formal/informal, technical level, complexity | |
| Intent classification | Inform, persuade, criticize, question | |
| Structural Organization | Temporal extraction | Timeline of events, chronological ordering |
| Hierarchical categorization | Taxonomies, nested topic structures | |
| Section segmentation | Break into logical parts (intro, methods, conclusion) | |
| Thread reconstruction | Link replies, responses, follow-ups | |
| Citation network analysis | Who references whom, influence mapping |
| Category | Use Case | Description |
|---|---|---|
| Quality & Meta-Analysis | Fact-checking flags | Mark claims needing verification |
| Bias detection | Political, cultural, or demographic biases | |
| Quality scoring | Rate argument strength, evidence quality, coherence | |
| Contradiction detection | Find conflicting statements within/across documents | |
| Gap analysis | Identify missing topics or underexplored areas | |
| Discourse type classification | Narrative, expository, argumentative | |
| Knowledge Synthesis | Comparative analysis | How different sources treat same topic |
| Consensus identification | Points of agreement across documents | |
| Evolution tracking | How arguments/positions change over time | |
| Cross-reference generation | Link related content across corpus | |
| Glossary creation | Extract and define domain-specific terms | |
| Question generation | Create relevant questions the corpus answers |
Demo
Let’s pick arguments
We have this dataset of verbatim debates of the European parliament.
I will connect to a model via groq
and use it to extract arguments from the debates.
and enrich the original datasets
I work on a samll subsample of the whole dataset (45M)
API caps
Using an API is limited in two ways
- frequency
It’s important to not ovewhelm the endpoint. Always add some pause in your loops
import time
time.sleep(1)
- volume
LLMs APIs have limits wrt to the amount of data you can send and retrieve.
Specially for free APIs!
Your alloted amount of free tokens is severaly limited as you will see
Method
always work on the smallest subset of data that’s relevant.
start with one or two samples to verify the code works
once the code works, slowly scale up, do not process the whole dataset right away
you never know if some weird row will break your code
Some code best practices
DRY: Don’t Repeat Yourself KISS: Keep It Simple, Stupid YAGNI: You Ain’t Gonna Need It SRP: Single Responsibility Principle PIE: Program Intently and Expressively
Indempotency
A very very important aspect of API calls is indempotency.
An operation that produces the same result no matter how many times you perform it.
Example: The Elevator Button 🛗
- 1st press: Elevator called ✅
- 2nd press: Still called (doesn’t call 2 elevators)
- 50th press: Still just one elevator coming
Result: Always the same - one elevator arrives
data example
- remove all stopwords
- capitalize words
not idempotent
- replace
lwithll - add a period before each capitalized letter
Code quality
you can ask your coding agent to respect these principles
and make the functions idempotent by not chaging the input but by outputing a new object / varraible
Let’s open a new collab
- save the API
- paste the template code in the first cell. so that Gemini knows about it
- load the dataset into a pandas dataframe
- ask Gemini to create a function that sends a prompt to the Groq API and return a JSON
- write a prompt, specify that the output must be JSON
- write a function add the returned JSON to the original dataframe.
Open Router
Now let’s see what we can do with open router
multiple LLM providers: 494 models
Let’s open a new account on openrouter and create an API key
https://openrouter.ai/
https://openrouter.ai/settings/keys
Open Router leaderboard
https://openrouter.ai/rankings
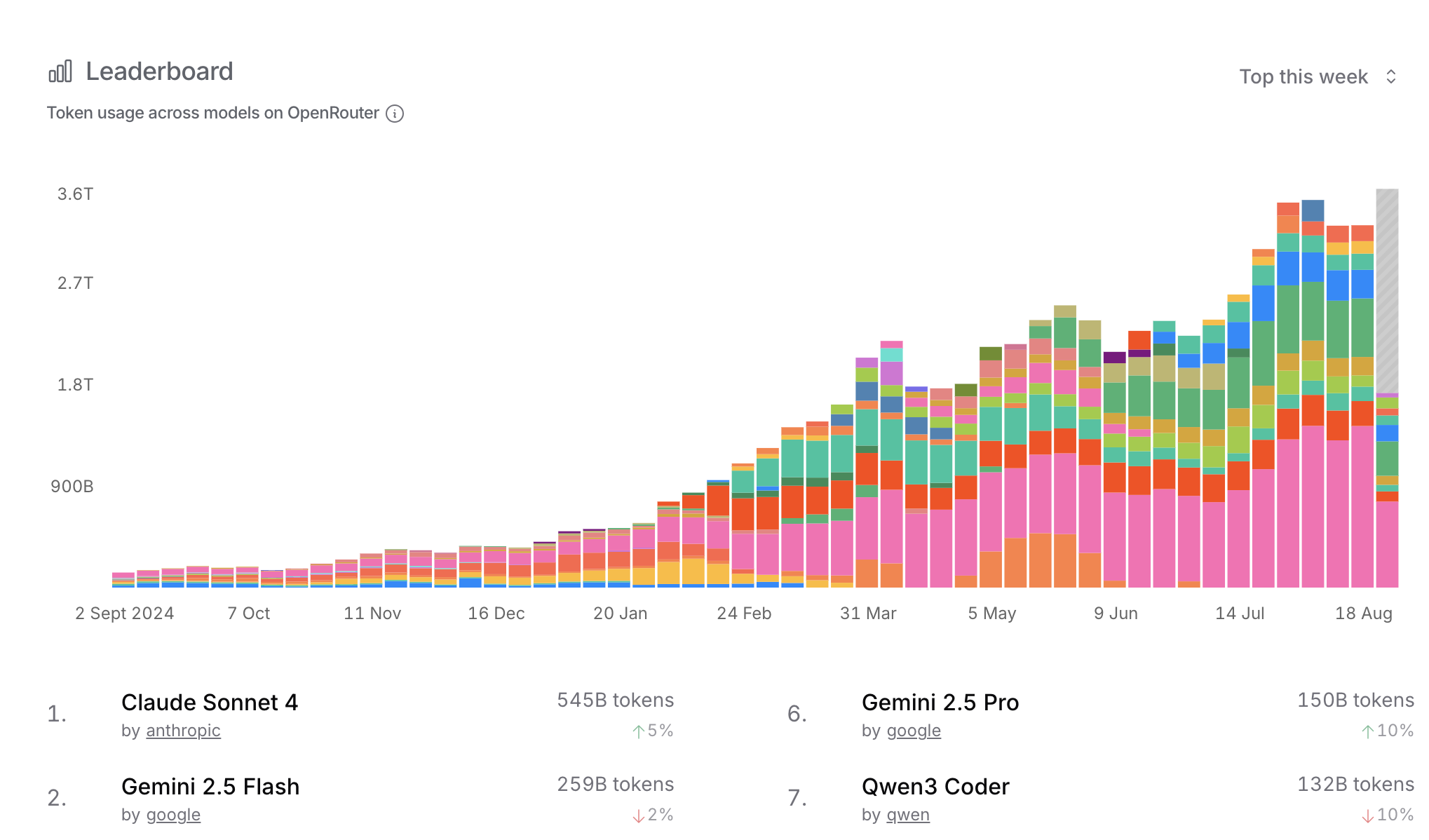
Open Router models
https://openrouter.ai/models
filter by
- input
- output
- pricing
there are multiple (57) free models that you can use
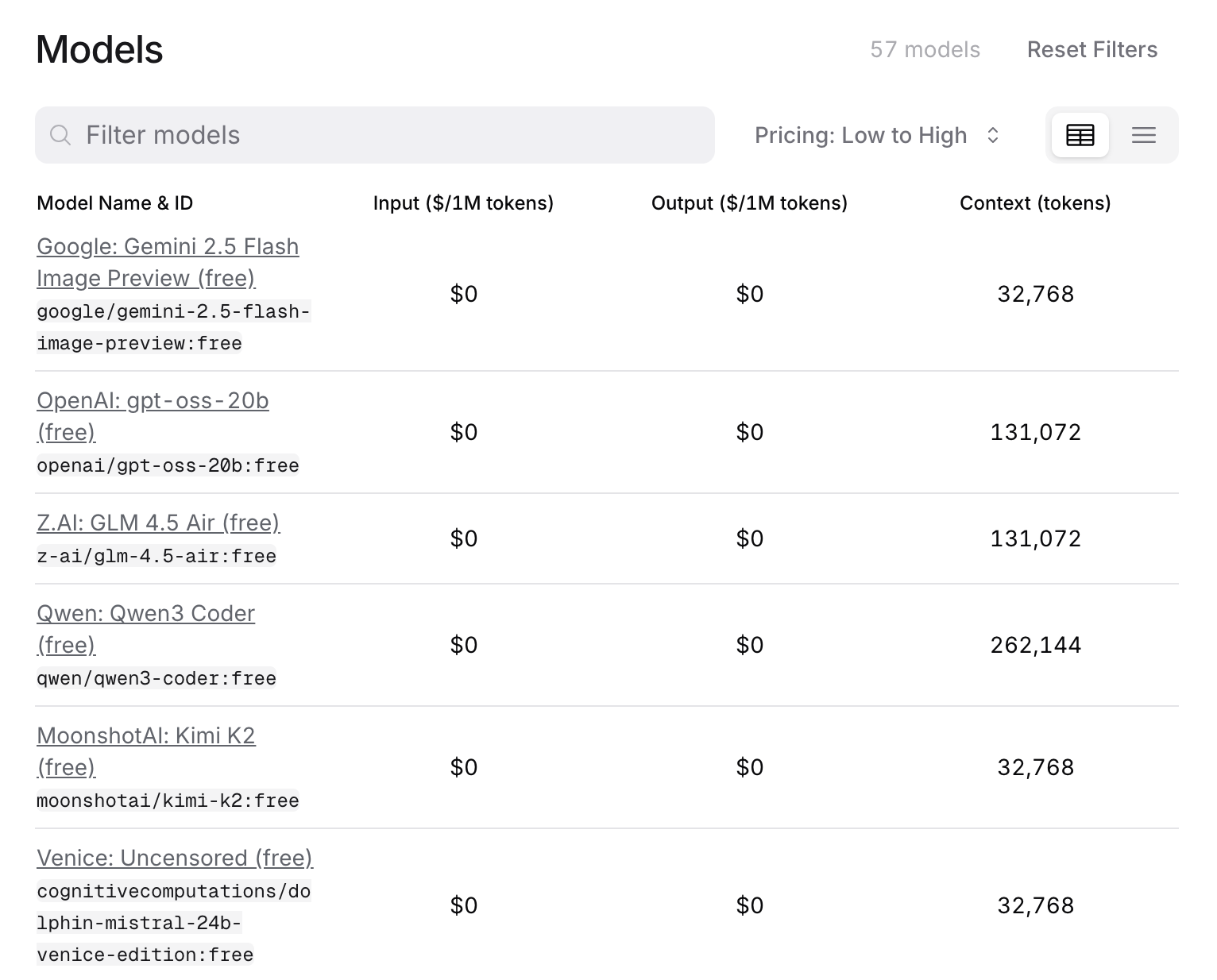
Compare model performance
Let’s go back to our small dataset
write the inference code for openrouter
with params: models (so we can switch models easily )
ask Gemini to create a function that sends a prompt to the OpenRouter API and return a JSON
write a prompt, specify that the output must be JSON
write a function add the returned JSON to the original dataframe.
pick 2 models!
Evaluate the 2 models
ok now let’s evaluate the 2 models
Most of the times it’s super difficult to say that on model is better than another one.
On some samples or some prompts one model will perform better than another one.
and sometimes vice versa.
we’re going to aks a rd model to evaluate the output of the 2 models
LLM as a judge
let’s try to use a model from groq as a judge
flow:
enrich the initial small dataset with the 2 open router
set the judge prompt with
- the original instructions (extract arguments)
- ask for a score
- ask for a justification
Then scale up!
Extra : data viz
Ask gemini for a visualization of the results
Continue to investigate on the difference in quality output
maybe you had something in mind, some expectation of how you wanted the data to be enriched. n what you wanted to see. and that did not come through
how can you improve the initial data enrichment prompt ?
The try fail loop
The iterative cycle of experimenting with models/approaches, analyzing failures, and refining until you find what works.
Why It’s Essential:
- Learning through failure - Each fail teaches what doesn’t work
- Progressive refinement - Incrementally improve understanding
- Hidden insights - Failures often reveal data issues, wrong assumptions
- Reality check - “My fancy model / prompt combo is worse than the baseline”
The Truth: If you’re not failing, you’re not trying hard enough. The magic happens in iteration 47, not iteration 1! 🎯