Investigating with AI
Web, JSON and pandas
- More about LLMs
- Data formats
- More Pandas
- Projects
=> you can record me
What we saw last time
- Course
- Projects
- State of AI
- Tools: Colab
- Demo: data analysis using Colab and Gemini
Questions ? Feedback ?

Today
- news review
- open source vs closed source
- data sources
- data formats
- working with pandas
- the web
-
Project reviews
- Guided practice: data formats (json, csv) and the python pandas library
At the end of this class
You
- understand what an API is
- know the 4 operations in the REST protocol
- can edit a JSON file
In the News
What caught your attention?
News Sept 8th 2025
-
Google dismentlement case not happening because of genAI which changes the monopoly status of google
Some numbers
- Anthropic now serves over 300,000 enterprise customers, with accounts worth $100k+ in annual revenue growing sevenfold in 2025. The company’s Claude Code assistant now generates $500M in annual revenue, with usage up 10x in three months.
Open source vs closed source
the hugging face release dashboard
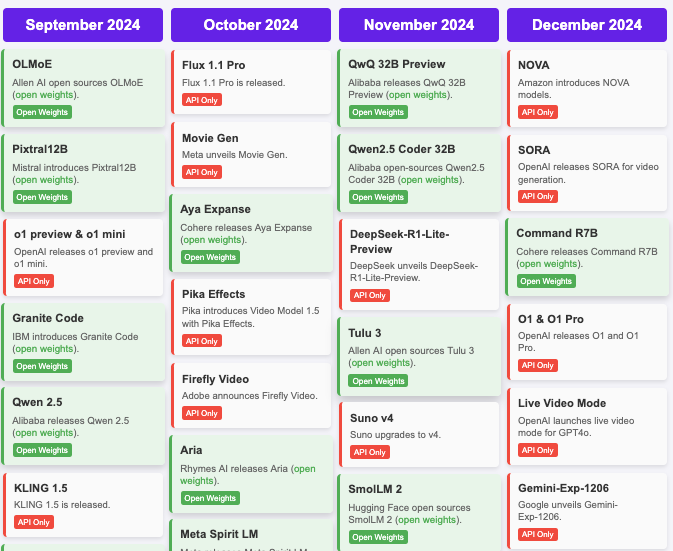
Major distinction between open and closed source models
Open source vs closed source
A distinction relevant for all software including AI models
Open source:
- The code is public : Linux
- Linux, OpenOffice, Firefox, Chromium, Python, major databases,
- Can be copied and modified by anyone
![]()
Closed source:
- The code is not accessible.
- Windows, Word, Chrome, Edge, Oracle
- needs a license to use, black box

Open source
Since the code is public: Transparency, security, innovation, cost-effectiveness
- Innovation & Flexibility: Users modify and enhance the software independently. Community-driven development, faster bug fixes, customization of code
- Security & Transparency: Security, there’s no virus. Issues are identified and patched quickly by the community.
- Cost-Effective: for users: free to use and modify, reduced licensing costs; no vendor lock-in. and for creators: community driven intelligence.
- Knowledge Sharing: Developers learn from existing code, accelerating skill development and innovation, shared knowledge and best practices.
Linux is open source
- Linux is an operating system (OS)
- software that manages the computer’s hardware (CPU, memory, storage) and lets you run applications.
- Created in 1991 by Linus Torvalds as a free alternative to proprietary systems.
- the code is public (GPLv2 license), anyone can copy, improve, and share.
- Runs most (85 - 90%) of the internet
- Powers Android phones, TVs, cars, spaceships and nearly all supercomputers.
- Vendor-neutral: scales from a $5 microboard (rasberry Pi) to hyperscale datacenters.
- Cost & control: open source, huge ecosystem, no forced upgrade cycles.
- excellent security: no virus, no bugs
- exists in 200–300 active distributions (versions)
Open source LLMs
Different levels of openness:
- model : you can download the model and use it as is
- code: the code to create the model
- training data: the data used in training the model
Some models are fully open (DeepSeek), partially open (LLama, Mistral 7B), or closed (OpenAI o1, Claude Sonnet, Gemini)
If you have the weights of a model you can fine tune it on your own data. Light version of training a whole model
Closed source models: issues
Lack of Transparency & Reproducibility: architecture, weights, hyperparameters, and training data hidden
- copyright issues : on what data was the model trained. Many ongoing lawsuits.
- see aifray an excellent resource on artificial intelligence regulation
- model bias :
- grok controversy MechaHitler
- hard to detect systemic biases, skewed behaviors, or harmful training artifactss
The HUGE Impact of LLMs on society demands transparency and accountability
Recent open source
| Model / Family | Date | Company | Key Highlights |
|---|---|---|---|
| GPT-OSS-120B / 20B | Aug 2025 | OpenAI | Open-weight MoE models; long context; consumer-friendly |
| Llama 4 (Scout, Maverick) | April 5, 2025 | Meta | Mixture-of-experts; multimodal; long context; multilingual |
| DeepSeek-R1 | Jan 2025 | DeepSeek | Strong reasoning & math performance |
| Gemma 3 | March 12, 2025 | Google DeepMind | Multimodal, multilingual, long-context |
| Qwen 2.5 (VL-32B, Omni-7B) | March 2025 | Alibaba (Qwen Team) | Vision–language and multimodal capabilities |
| Qwen 3 family | April 28, 2025 | Alibaba (Qwen Team) | Dense & sparse variants up to 235B |
| Mistral Small 3.1 | March 2025 | Mistral AI | Efficient small-scale open model |
| Magistral Small | June 10, 2025 | Mistral AI | Reasoning-focused, chain-of-thought tuned |
| GLM-4.5 | July 2025 | Zhipu AI | Agent-oriented model |
| BitNet b1.58 2B4T | April 2025 | Microsoft Research | 1-bit quantized, ultra-efficient |
| AM-Thinking-v1 | May 2025 | Academind / Qwen community | Qwen-based advanced reasoning model |
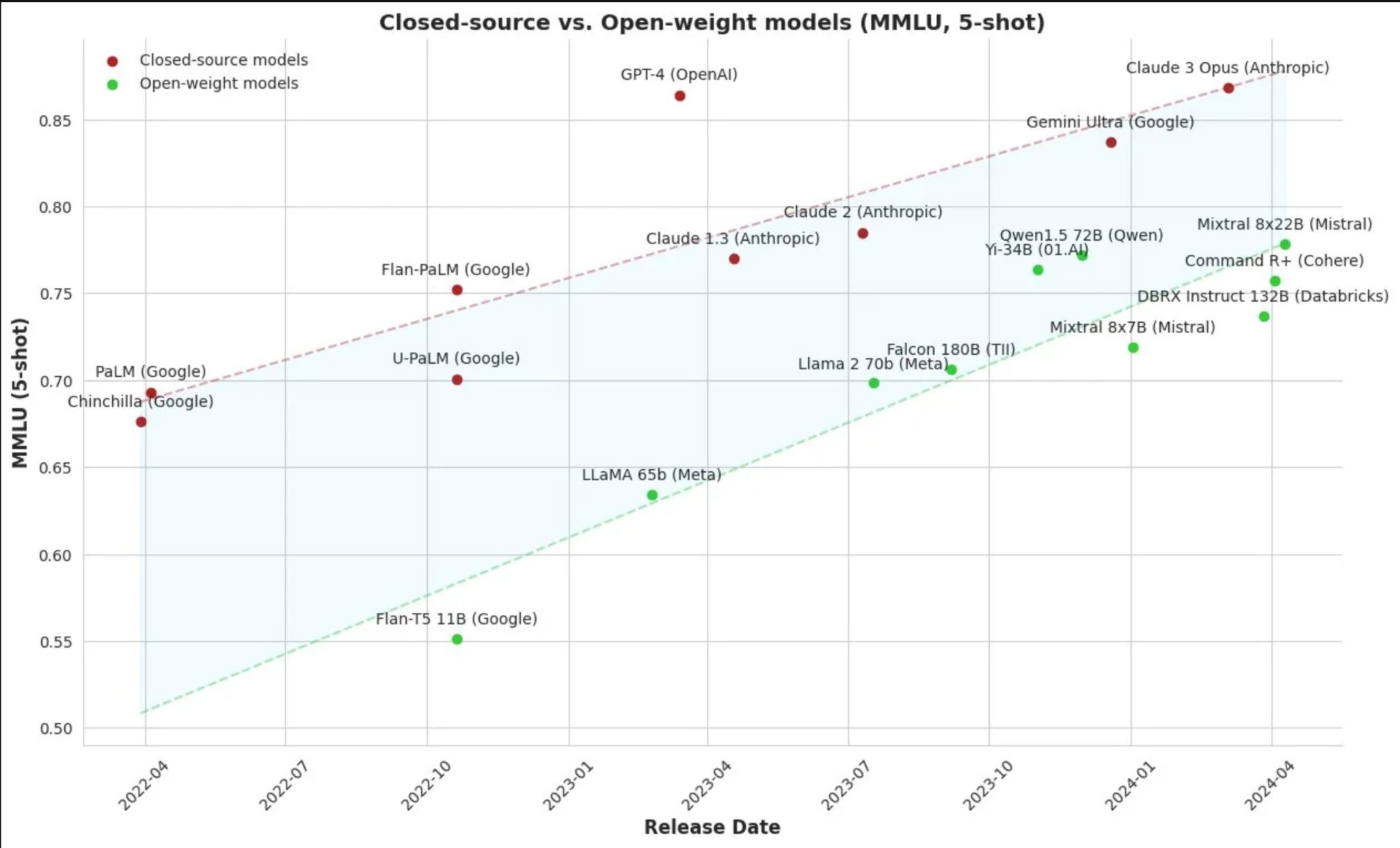
Open source models are catching up with closed source models
Q: What does this mean ?
Performance vs Cost - updated august 2025
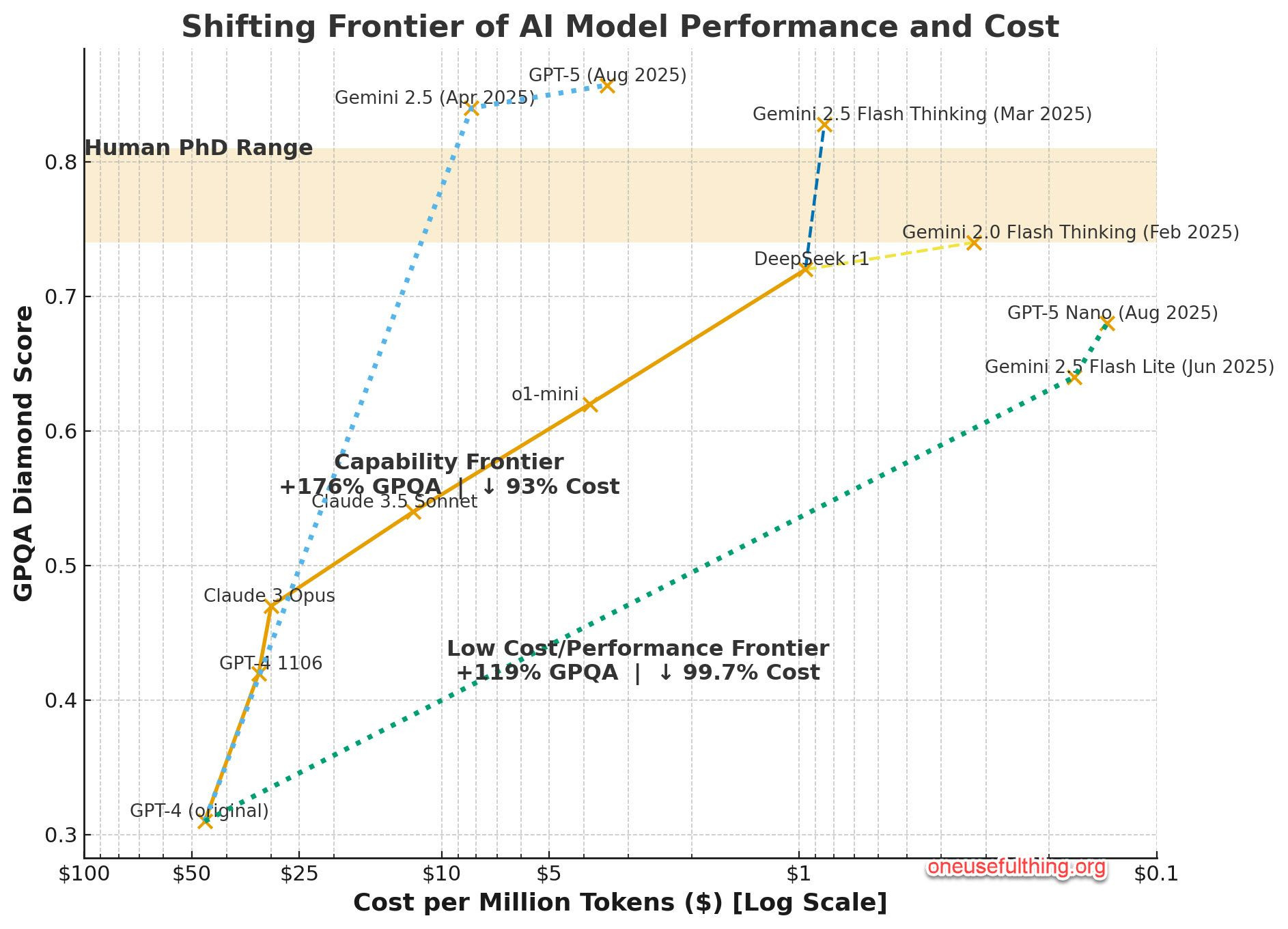
| Term | means Explanation |
|---|---|
| Multilingual | The model understands and can respond in many different languages, not just English. |
| Multimodal | The model can understand inputs like text and images (sometimes also audio/video) rather than just one type. |
| Long context | The model can remember and work with very long passages of text (think chapters or entire books) without forgetting what was at the start. 1M tokens |
| MoE Mixture-of-Experts |
An architecture where different experts models handle different parts of the task—only a few experts activate per input |
| Efficient / Consumer-friendly | Designed to run on regular devices (like a powerful laptop or single GPU) without needing massive data center infrastructure. |
Context window
- 1 token ≈ 0.75 words
- So 1,000,000 tokens ≈ 750,000 words.
- 1 page ≈ 250-300 words
- 1 million tokens ≈ 2,500–3,000 pages of a standard book.
- ~1.3× War and Peace by word count.
language variations
| Language | Example Sentence | Writing System | Approx. Tokens (LLM tokenizers like GPT-4’s) | Notes |
|---|---|---|---|---|
| English | I am going to the computer store tomorrow. | Alphabetic | ~9–10 | Clear word boundaries, but “computer” may split into subwords depending on tokenizer. |
| French | Je vais demain au magasin d’ordinateur. | Alphabetic | ~9–11 | Similar to English; compounds like d’ordinateur may add extra tokens. |
| Chinese | 我明天去电脑商店。 | Logographic | 7 | Each character is usually one token; very dense information packing. |
| Japanese | 私は明日パソコンの店に行きます。 | Mixed (Kanji + Kana) | ~12–15 | Needs morphological analysis; kanji are tokens, kana sometimes merge into subwords. |
| Korean | 나는 내일 컴퓨터 가게에 간다. | Alphabetic (syllabic blocks) | ~10–12 | Spaces exist, but subword splits can happen (esp. with loanwords like 컴퓨터). |
MoE Mixture of Experts
- Mixture of Experts (MoE) = many small specialists models + a ** router.
The router model picks the proper expert models given the input and combines their outputs.
=> Better quality (specialization) and lower cost (sparse compute).
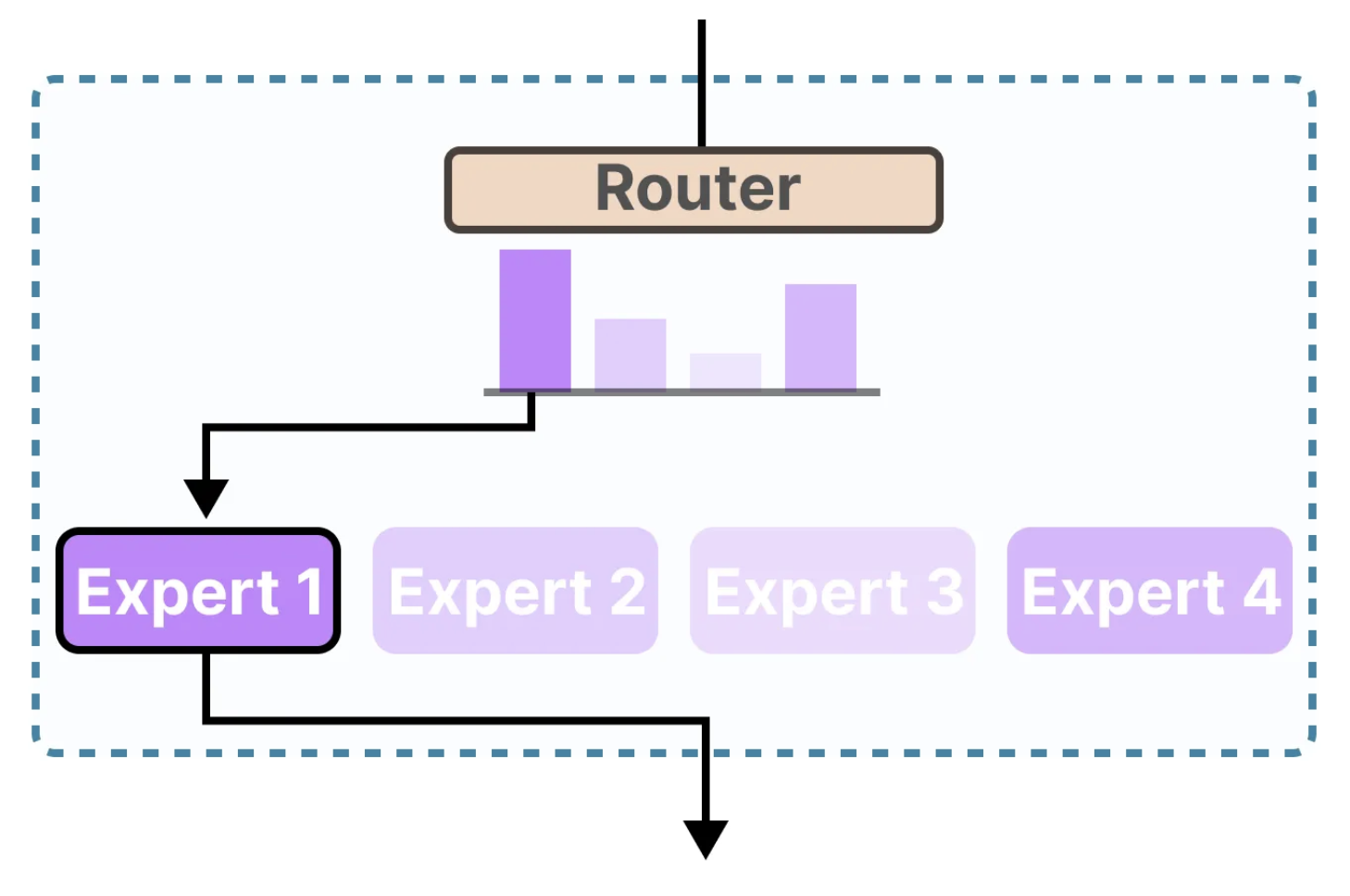
How experts form (training)
-
Model trains end-to-end: router + all experts learn together.
-
Router learns which experts fit each token/type of text.
-
Experts get practice on what they see most → specialization emerges
-
Load-balancing & capacity limits keep work shared so all experts improve.
Questions:
- so how do you train expert models ?
- is there a taxonomy of all the subjects ?
=> No
Data & sampling weights
-
Train on a big mixed dataset (web, books, code, Q&A, dialogue, languages).
-
We choose sampling weights by goals → start with an initial mix, then test & adjust.
-
Guardrails: min/max quotas, quality filters, de-duplication; optional curriculum (shift weights over time).
-
MoE-specific nudge: up-weight data that wakes underused experts.
=> Net effect: the router + data mix shape who does what, efficiently.
Datasets & datasources
Datasets & datasources
- News and Media: Newspaper archives (NYT, …), Youtube (yt-dlp), websites
- Scholarly and Scientific Articles: Academic journals, PubMed, arXiv, JSTOR.
- Encyclopedic and Knowledge Bases: Wikipedia / Wikidata
- Entertainment and Cultural Datasets: IMDb for film and television data, GoodReads
- Government and Legislative Data: Parliamentary records, government publications, election results
- Consumer Reviews: Amazon Reviews, CellarTracker
- Social networks: Reddit, Instagram, TikTok, Facebook, Twitter, Telegram, …
Kaggle datasets
Obtain and analyze an existing CSV dataset for the project.
- NYT Articles: 2.1M+ (2000-Present) Daily Updated
- NYT Articles: Small Processed 500k Version
- IMDB Dataset: of 50K Movie Reviews
- arXiv Dataset
- GoodReads 100k books
- GoodReads Best Books
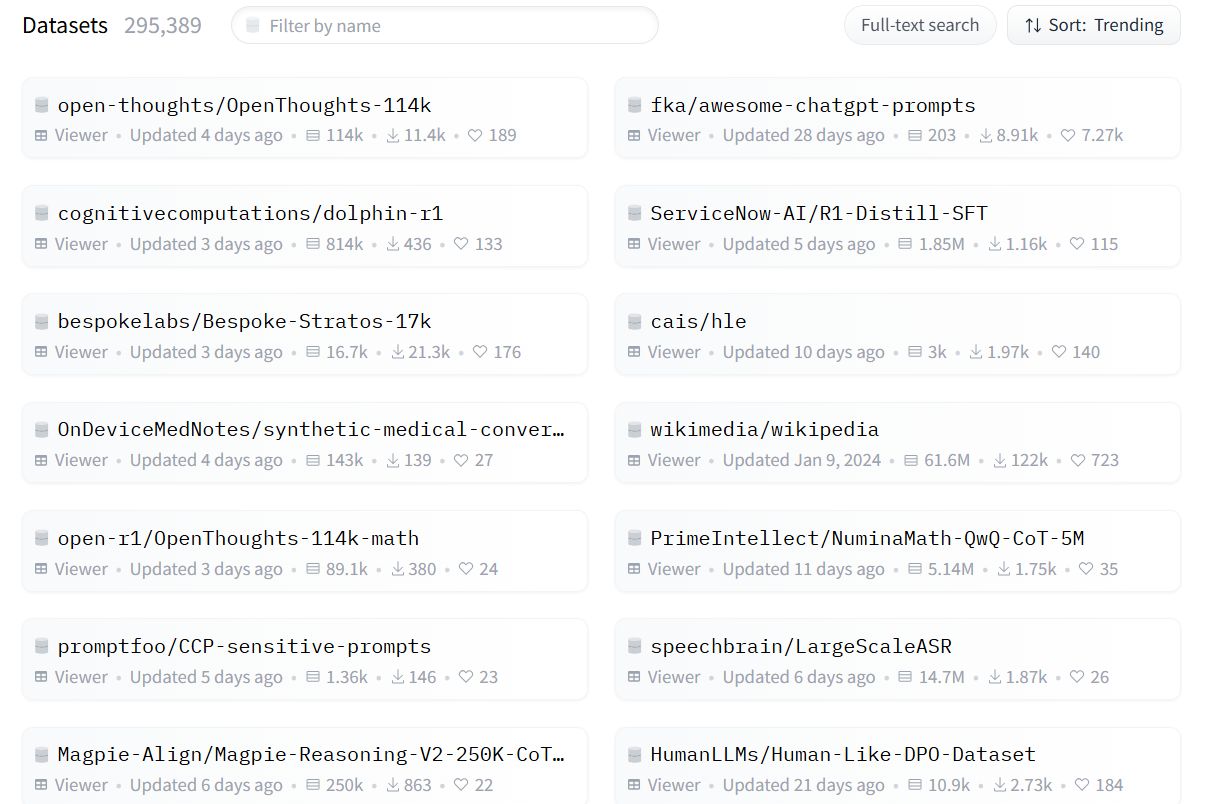
Hugging Face datasets interface with 295,389 datasets and various dataset examples
Google datasets search engine
Data sources
- European data https://data.europa.eu/en
- World bank https://data.worldbank.org/
- France https://www.data.gouv.fr/ and most countries
- Paris https://opendata.paris.fr/pages/home/ and most capitals
- French energy agency https://data.ademe.fr/ and other Gov or non gov agencies
Media
rss feeds
RSS = “Really Simple Syndication.” A standard way for websites to publish updates.
How it works: Sites expose a feed (an XML file). Your reader/aggregator checks it and shows new posts in one place.
Why it’s nice: Chronological, no algorithms, no ads injected by platforms, and privacy-friendly (you pull info; nobody tracks your clicks by default).
What you can follow: Blogs, news sites, podcasts, newsletters, job boards, YouTube channels, forum threads.
Finding feeds: Look for the RSS icon, “/feed” or “/rss” on the site, or a “Subscribe”/“Follow via RSS” link.
ex: https://oilprice.com
yt-dlp
Super efficient video downloader
Can also be used for transcripts / subtitles to build a corpus
https://github.com/yt-dlp/yt-dlp
https://www.pythoncentral.io/yt-dlp-download-youtube-videos/
yt-dlp --write-subs https://www.youtube.com/watch?v=example
Example, pick a media, get all videos, download subtitles or get videos, extract images, analyse images etc
examine coverage of a topic by a media. commentary, images, etc
EU parliament debates
- show the page (url) to the model as an example
- ask to extract all interventions
- get meta data on speakers
- extract arguments
JSON
Beyond html: JSON
There are multiple API standards and languages
And APIs can return all sorts of content: html, text, xml, pdfs,
APIs often return raw data formatted as JSON
JSON (JavaScript Object Notation) is a lightweight data format.
- easy for humans to read and write.
- easy for machines to parse and generate.
JSON
how machine exchange data
- Universal & simple: Text-based, easy for humans to read and write.
- Language-agnostic: Supported natively in virtually every language (JSON.parse, JSON.stringify).
- Web-native: Plays perfectly with HTTP/REST, GraphQL, Web APIs, and browsers.
- Lightweight & fast: Smaller and quicker to parse than many alternatives (e.g., XML).
- Flexible structure: Handles objects, arrays, numbers, strings—good for nested data.
- Great tooling: Linters, formatters, validators, and JSON Schema for contracts.
- Interoperable storage: Used by NoSQL DBs (e.g., MongoDB), config files, logs, and events.
- Streaming-friendly: Works well for real-time APIs and message queues.
[
{
"name": "Châtelet",
"lines": ["1", "4", "7", "11", "14"],
},
{
"name": "Bastille",
"lines": ["1", "5", "8"],
},
{
"name": "Charles de Gaulle–Étoile",
"lines": ["1", "2", "6"],
}
]
[
{
"name": "Charles de Gaulle–Étoile",
"lines": ["1", "2", "6"],
"exits": [
{
"name": "Sortie 1 — Arc de Triomphe",
"address": {
"street": "Place Charles de Gaulle",
"postal_code": "75008",
"city": "Paris",
"country": "France"
}
},
{
"name": "Sortie 2 — Champs-Élysées",
"address": {
"street": "Avenue des Champs-Élysées",
"postal_code": "75008",
"city": "Paris",
"country": "France"
}
}
]
},
{
"name": "Bastille",
"lines": ["1", "5", "8"],
"exits": [
{
"name": "Sortie 1 — Place de la Bastille",
"address": {
"street": "Place de la Bastille",
"postal_code": "75011",
"city": "Paris",
"country": "France"
}
}
]
}
]
[
{
"name": "Billlie",
"origin": "South Korea",
"genre": "K-pop",
"debut_year": 2021,
"members": [
"Moon Sua",
"Suhyeon",
"Haruna",
"Sheon",
"Tsuki",
"Siyoon"
],
"notable_songs": ["Ring X Ring", "GingaMingaYo", "EUNOIA"]
},
{
"name": "Oasis",
"origin": "United Kingdom",
"genre": "Britpop / Rock",
"debut_year": 1991,
"members": [
"Liam Gallagher",
"Noel Gallagher",
"Paul Arthurs",
"Paul McGuigan",
"Tony McCarroll"
],
"notable_songs": ["Wonderwall", "Don't Look Back in Anger", "Champagne Supernova"]
}
]
JSON rules
- Always in key–value pairs as
"key": value -
Keys must be in double quotes
" ". - Allowed value types
- String (in double quotes) →
"Hello" - Number (no quotes) →
42, 3.14 - Boolean →
trueorfalse - Null →
null - Object →
{ "key": "value" } - Array →
[ 1, 2, 3 ]
- String (in double quotes) →
Common Mistakes
- Using single quotes for keys/strings.
- Adding a trailing comma at the end of arrays/objects.
- Having comments
(// ... or /* ... */)→ not allowed in JSON. - Using undefined values like
NaN,Infinity, or functions → invalid.
Common data types
- strings
- numbers: integers or floats
- booleans : true or false, 0 or 1.
torf - 1 dimensional : arrays, lists, sets, … in JSON :
[] - 2 dimensional : matrices, tables, dataframes … in JSON :
{} - 3+ dimensional : tensors
Missing data
- Null
- NaN
- None
- ”” : empty string
How do you edit a JSON file ?
- do not use word or google docs. These are for real human text not data
- use a code editor but it’s overkill for just editing JSON
- notes
spyder,vscode,windsurfsublime,atom,Xcode- github.dev
- An online JSON formatter and editor is a good alternative
- for instance https://jsoneditoronline.org/
csv
csv stands for : comma separated values
in 🇫🇷🇫🇷🇫🇷 France, we use ; as a separator because numbers use , as a decimal separator 🤪
- France:
123.456,78 - Rest of the world:
123,456.78
csv files with a tab separator are sometimes called tsv
A csv file is a spreadsheet.
Do not use Excel to edit your csv file!
Do not use Word to edit your json file!
A Space Odyssey - 1968 - Stanley Kubrick
pandas
THE library to handle data.

Loads a csv file into a dataframe
A dataframe is exactly like a spreadsheet. columns and rows
import pandas as pd
df = pd.read_cv('titanic.csv')
basic manipulations
print(df)
df.head()
df.tail()
df.columns
df.dtypes
df.shape
df.describe()
Missing values = NULL
df.isnull()
Selecting columns
df['column_name']
df[['column_name1', 'column_name2']]
df.loc[:, 'column_name1':'column_name2']
df.iloc[:, 0:2]
Selecting rows
df.loc[]
df.iloc[]
Masking
- create a logical mask, a condition
mask = df.age > 18 - only get the rows for that condition
df[mask] - combine masking and selection
column_names = [list of column names you want to see]
df.loc[mask, column_names]
Pandas Practice
demo
In google colab
- load the titanic dataset into a pandas dataframe
- apply these techniques to explore the dataset
The titanic dataset is available here
Your turn
Load imdb_top_1000.csv either from local or from the url into a pandas dataframe called df
Read the Data dictionnary
Then => Practice sheet
Projects
Projects
Let’s review your projects
fill in the google spreadsheet for projects
- team
- project title
- project description
- data source
Next week
- build your dataset with APIs
- APIs
- NYT API, wikipedia API, Guardian API
new data source:
Ethan Mollick : https://www.oneusefulthing.org
