Investigating
with AI
DHUM 25A43
Fall 2025

Who am I?
Alexis Perrier
- PhD TelecomParis 95’
- Developper, data scientist, author, teacher
- cycling, staying fit, scifi, …
- grateful nerd
What do you do with all that data?
Data enrichment: semantic analysis, topic modeling, named entity recognition, etc. combining datasets, …
Qualitative and Quantitative Analysis: stats, segmentation, insights, leveraging domain knowledge,etc.
Data visualization: What’s the story, what’s the narrative?

Session flow
- waking up, news review, coffee, questions (15mn)
- lecture, concepts, why and how (20mn)
- demo (30mn)
- nerdy cultural intermission (10mn)
- hands on practice / project work
- exit ticket: your feedback is muy importante
and questions, questions, and more questions
Office hours, support: discord! ![]()
Getting to know you
I’d like to know a bit more about you
All questions are optional (except your email)
Please fill out this form

New AI models every week
Chatbot Arena: LLMs vs LLMs
Where LLMs compete LMArena.ai Leaderboard
Total models: 229. Total votes: 4M
- text
- webdev
- vision
- text-to-images
- search
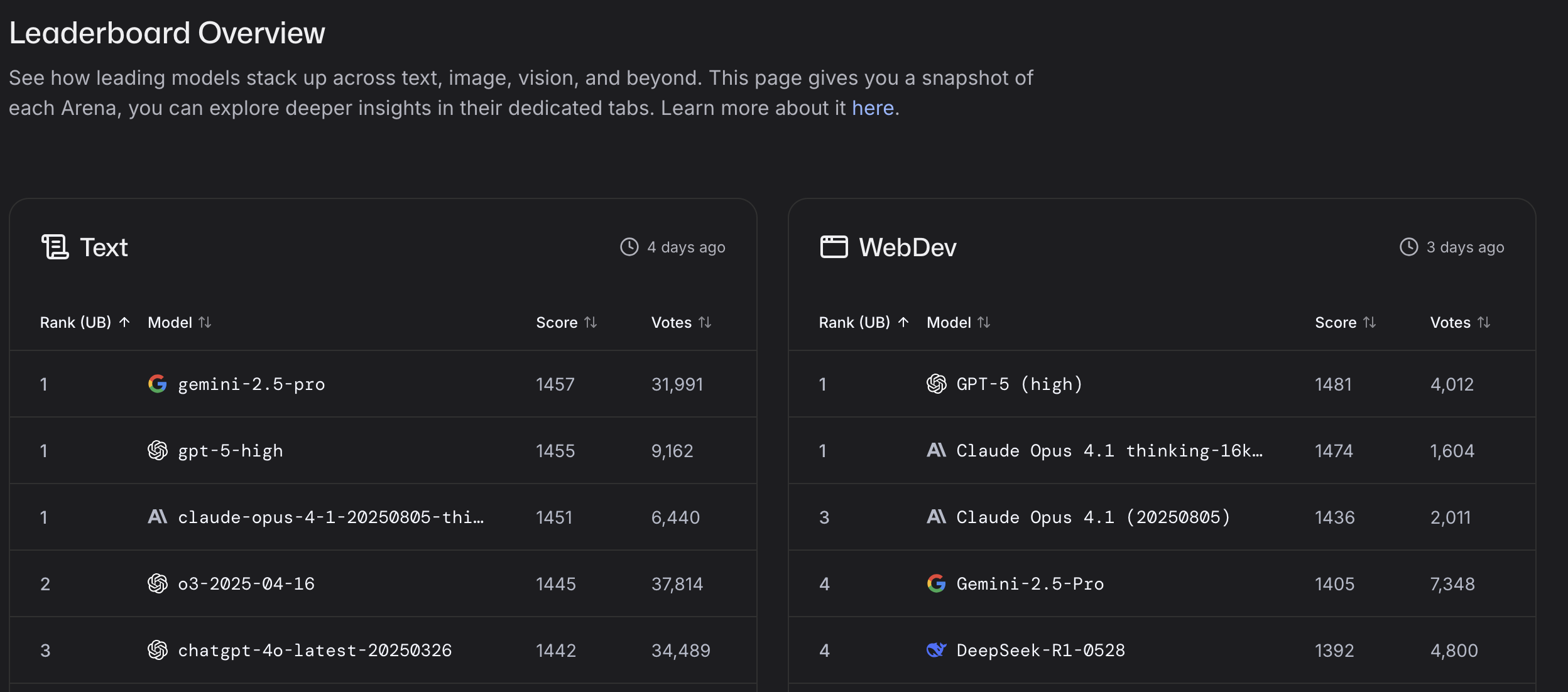
Artificial Analysis Intellligence Index
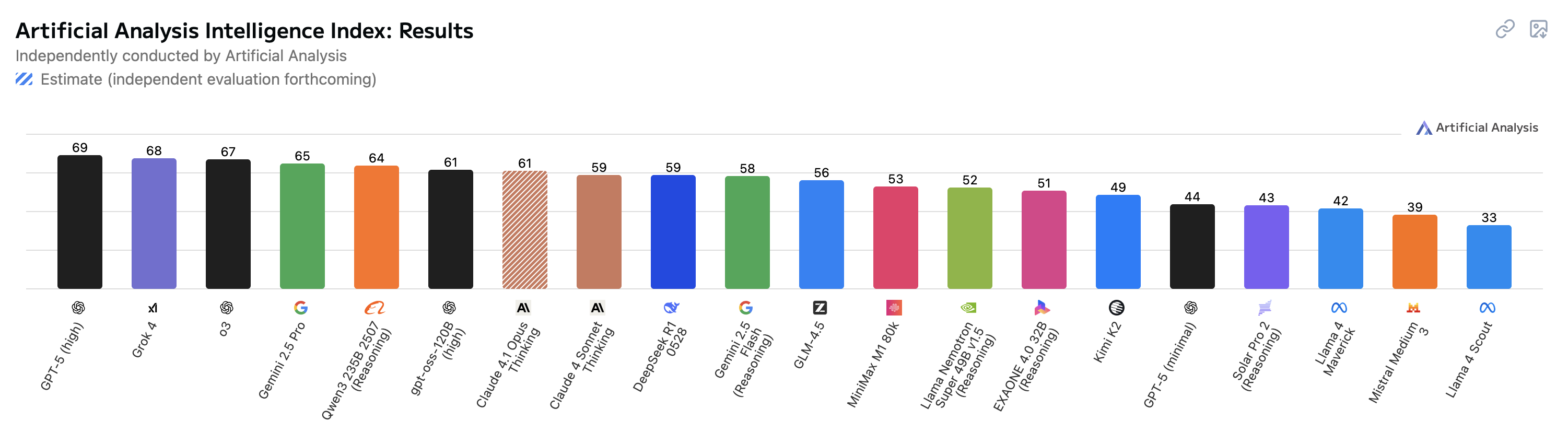
Artificial Analysis Intelligence Index combines performance across seven evaluations: MMLU-Pro, GPQA Diamond, Humanity’s Last Exam, LiveCodeBench, SciCode, AIME 2025, and IFBench.
Score vs release date
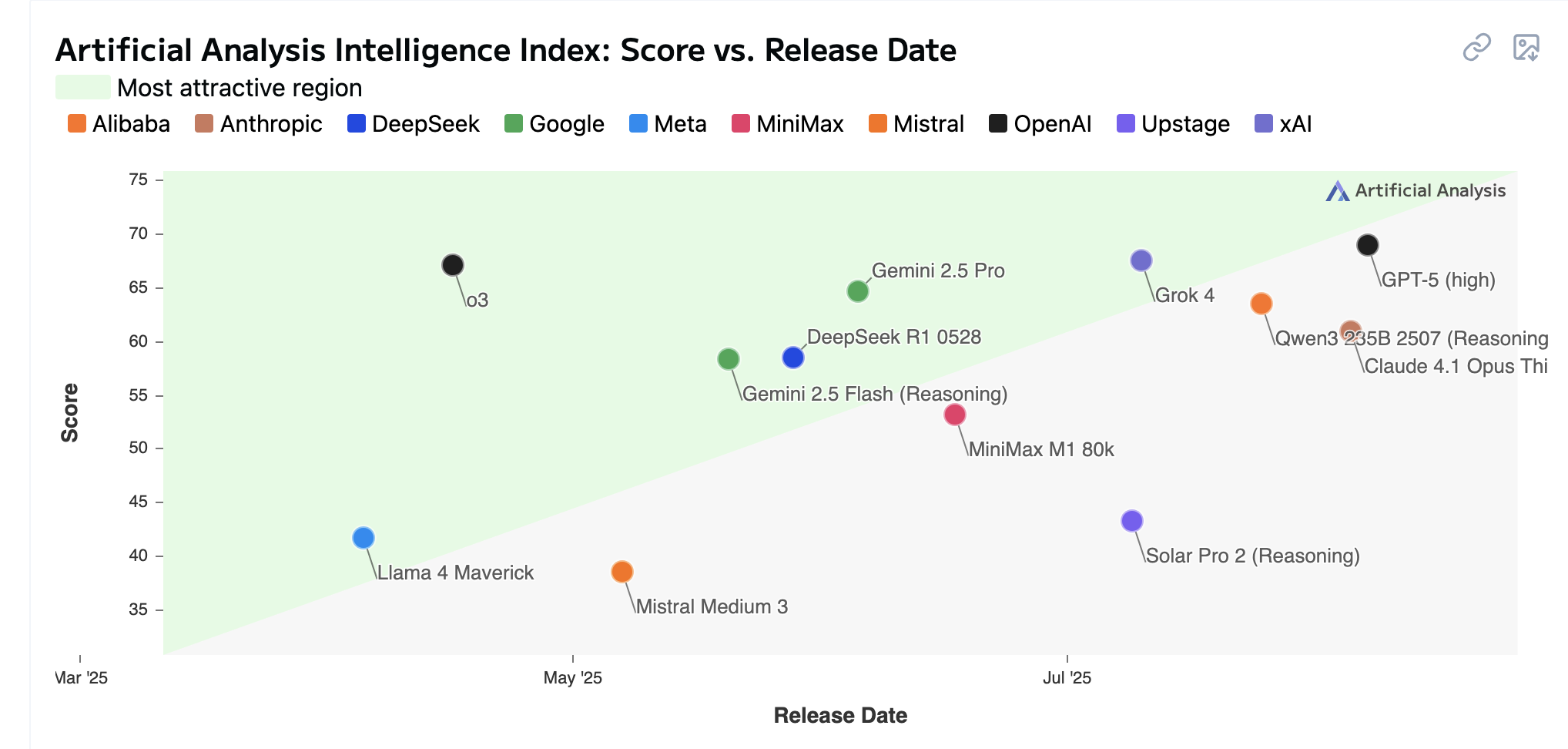
Cost
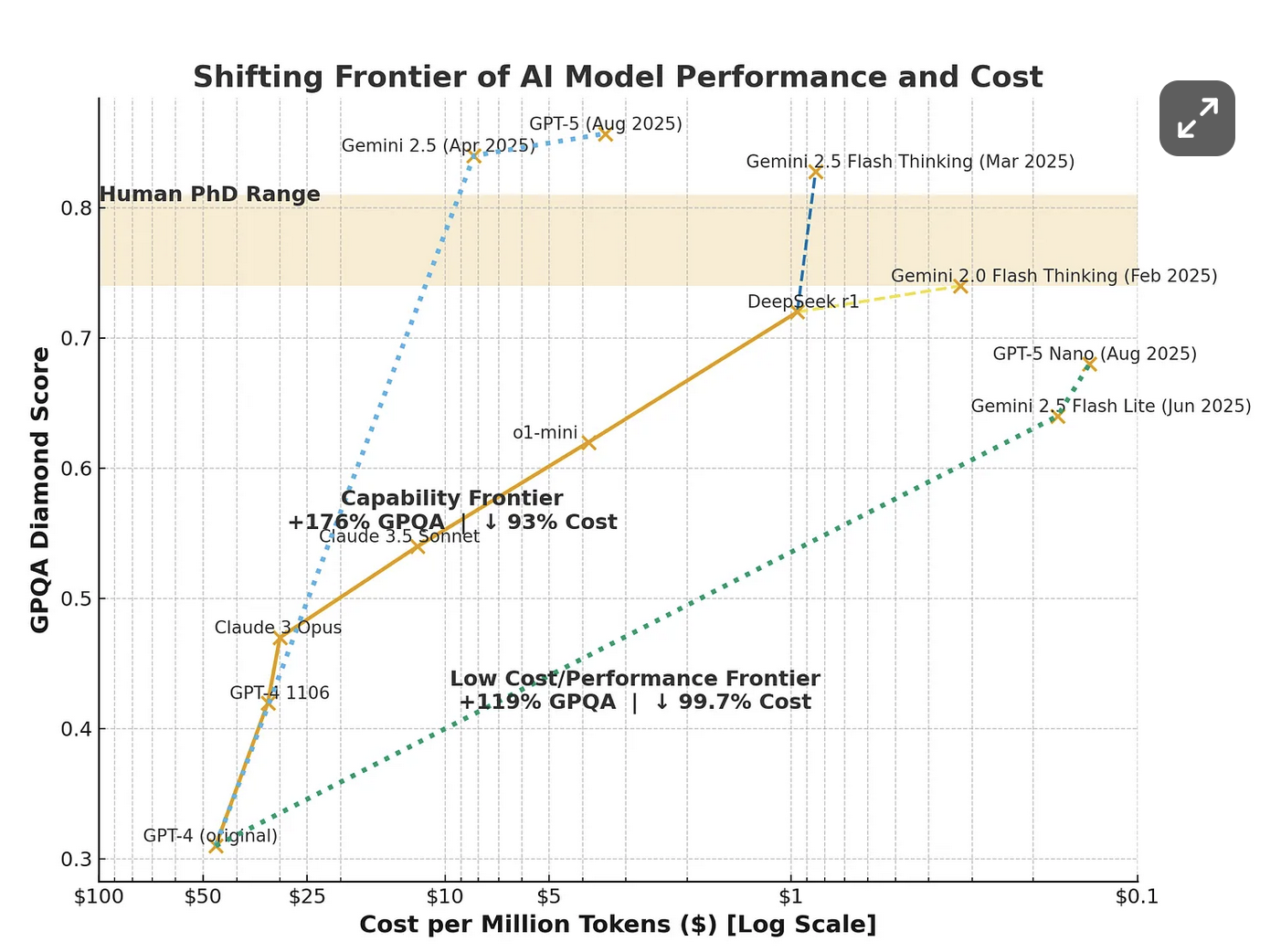
“When GPT-4 came out it was around $50/ Mtokens, now it costs around 0.14$ / Mtokens to use GPT-5 nano. GPT-5 nano is a much more capable model than the original GPT-4.”
Let’s explore some penguins
… with pandas

The dataset
midjourney: a panda is typing on a laptop ; a penguin is looking over the shoulder realistic, natural colors, low sun, the pandas wears a knitted hat and a warm jacket background : polar station, ice, snow
Google colab practice
Simple exercise on google colab with a similar dataset : the Titanic!
The titanic dataset is a classic in machine learning.
- List of 200 passengers
- some features (age, sex, name, ticket price, etc.)
- and a target variable : survival or not. 0 or 1

