Word2vec 2013
Thomas Mikolov @Google Efficient Estimation of Word Representations in Vector Space
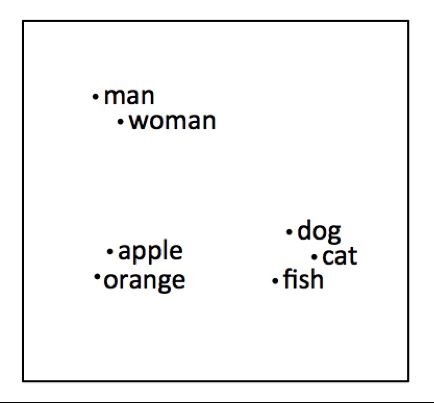
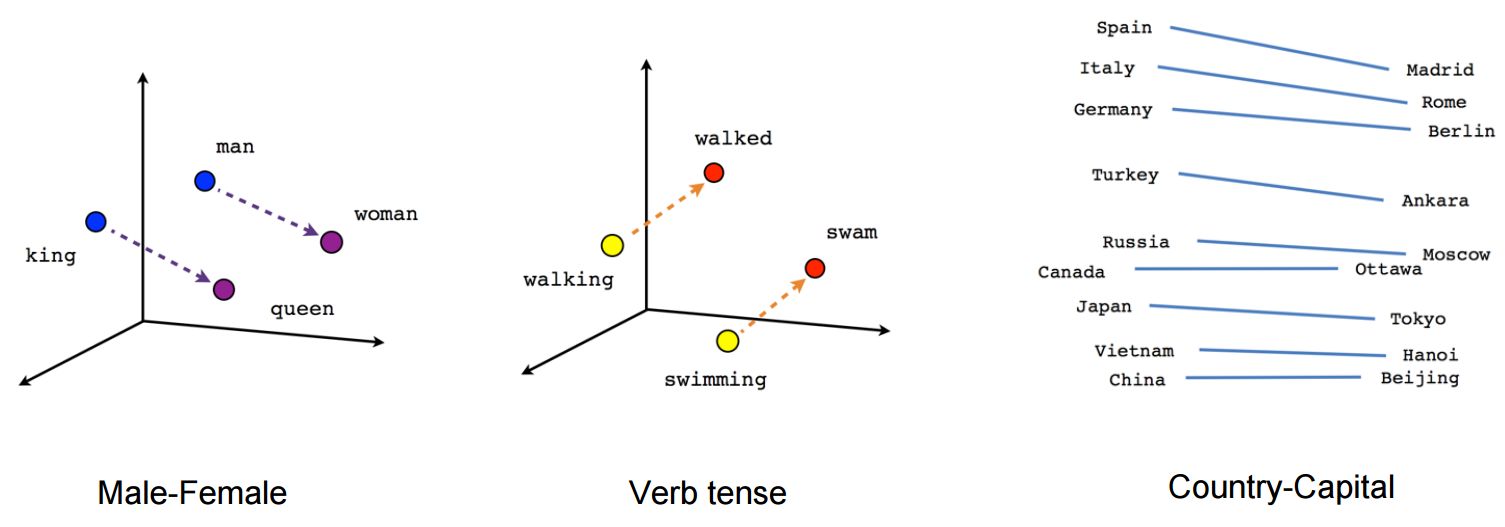
Distance sémantique de mots similaires
Queen - Woman = King - Man
France + capital = Paris
Germany + capital = Berlin
mais toujours pas de désambiguïsation contextuelle : les vers de terre = je vais vers la table.
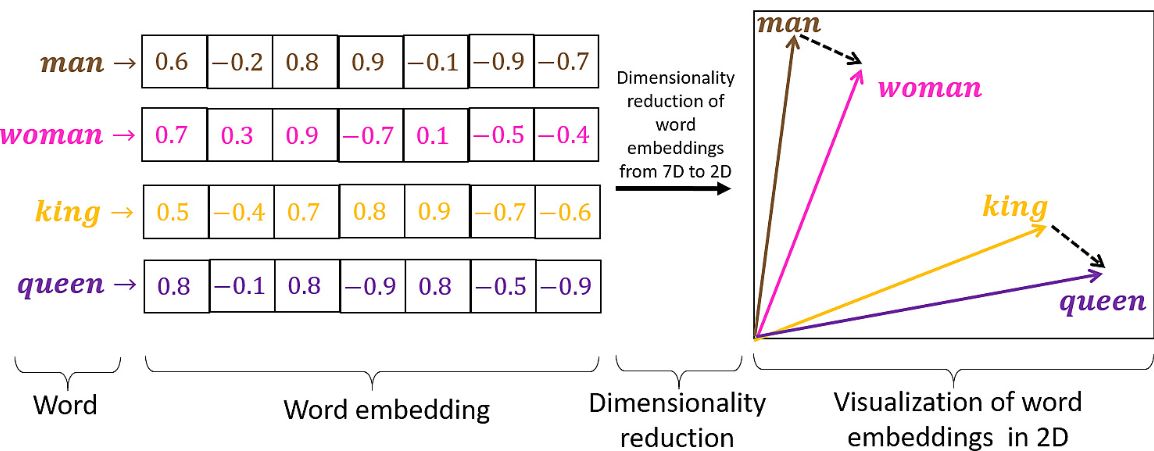
word2vec 2013
Chaque mot est un vecteur de grande dimension
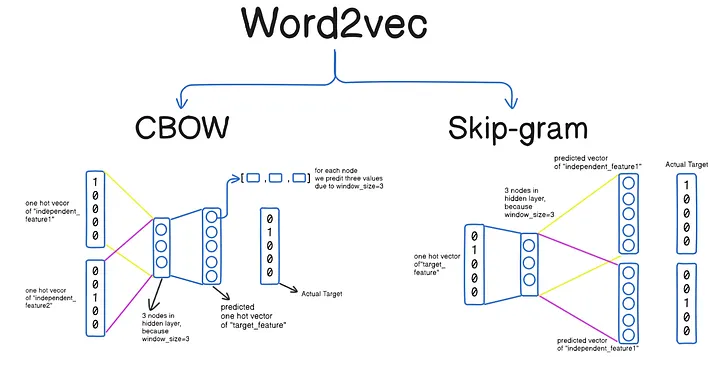
CBOW vs skip-gram
- CBOW (Continuous Bag-of-Words): Predict the target word (center word) from the surrounding context words.
- skip-gram: Predict the context words from the target word (center word).
Cosine similarity
Une fois que vous avez les embeddings (vecteurs, séries de nombres) de 2 textes (phrases, mots, tokens, …), leur distance est donnée par la similarité cosinus de leurs embeddings
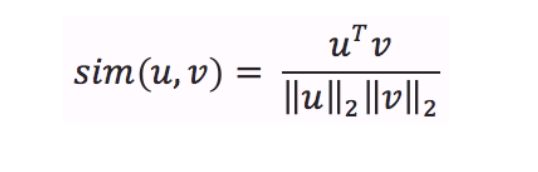

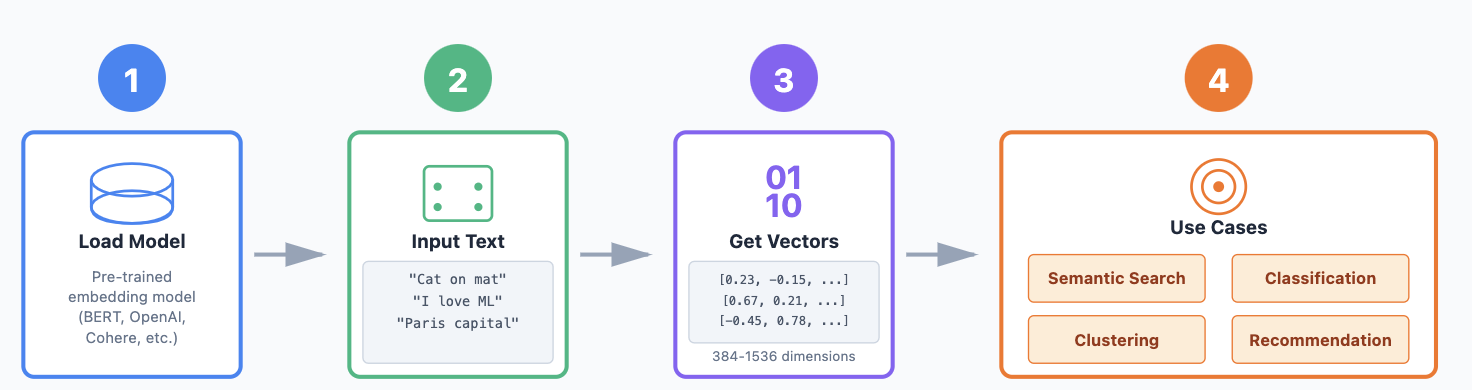
Exemple de workflow :
- Charger un modèle d’embedding pré-entraîné.
- Passer les phrases dans le modèle.
- Obtenir un vecteur de dimension N (embedding) pour chaque phrase.
- Utiliser ces embeddings pour la tâche en aval.
RAG : retrieval augmented generation
