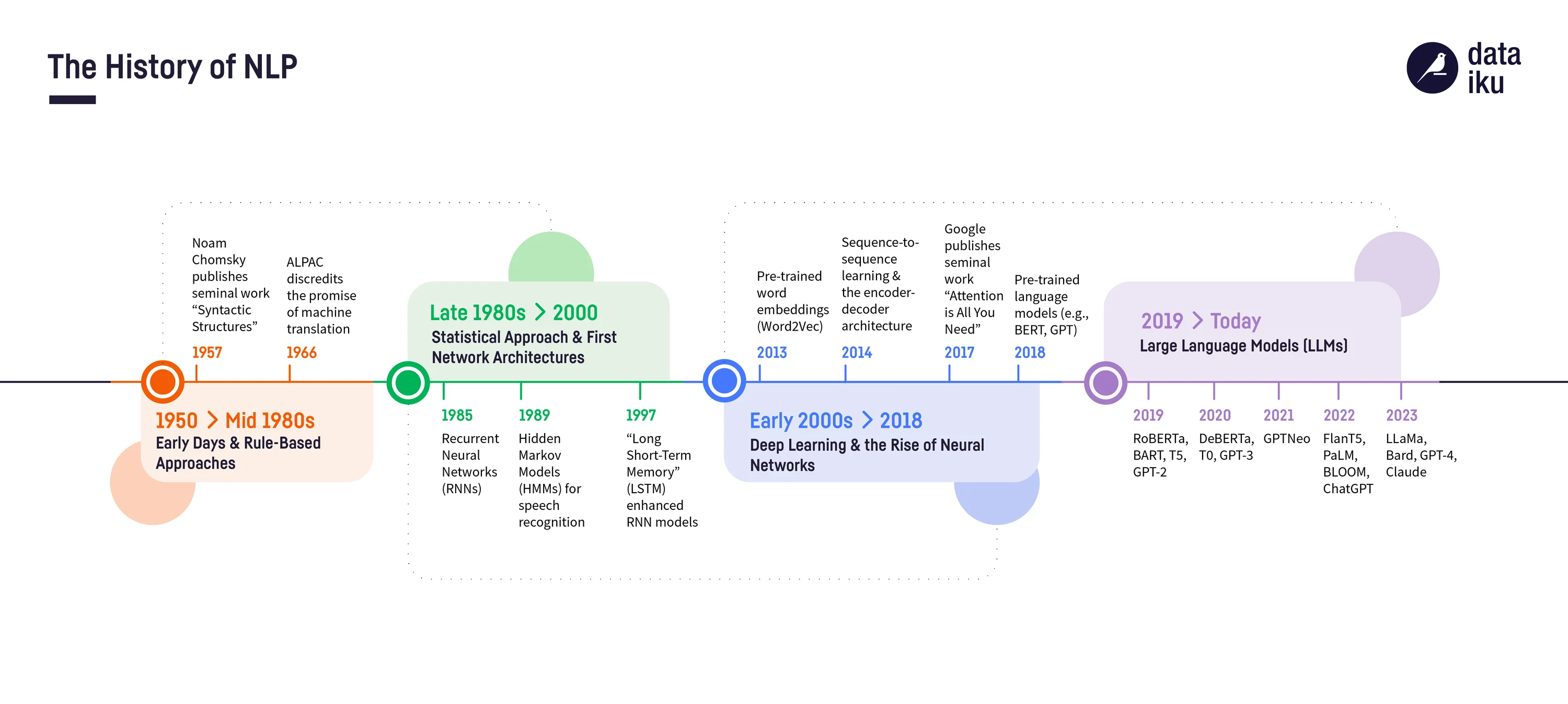
De la linguistique au NLP
Ferdinand de Saussure 1916

- La linguistique est l’étude scientifique du langage humain—comment il est structuré, comment il fonctionne, comment il évolue, et comment les gens l’utilisent pour communiquer.
- Le NLP (Natural Language Processing) est un domaine de l’informatique et de l’IA qui vise à enseigner aux ordinateurs à comprendre, interpréter et générer le langage humain.
Le NLP applique les connaissances de la linguistique pour construire des technologies du langage. La linguistique fournit la compréhension théorique du fonctionnement du langage, tandis que le NLP utilise ces connaissances (ainsi que les statistiques et le machine learning) pour créer des applications pratiques comme les outils de traduction, les chatbots et les assistants vocaux.
En bref : la linguistique étudie le langage, le NLP fait travailler les ordinateurs avec le langage.
Autres références classiques
1957 Benveniste : Problèmes de linguistique générale

1957 Chomsky : syntactic structures
voir wikipedia Chomsky
La base de la théorie linguistique de Chomsky réside dans la biolinguistique, l’école linguistique qui soutient que les principes sous-tendant la structure du langage sont biologiquement prédéfinis dans l’esprit humain et donc génétiquement hérités. Il soutient que tous les humains partagent la même structure linguistique sous-jacente, indépendamment des différences socioculturelles.

Speech and Language Processing

Speech and Language Processing (3rd ed. draft) Dan Jurafsky and James H. Martin
Dernière version : 24 août 2025 !!

NER : reconnaissance d’entités nommées
Tous types d’entités prédéfinies : lieu, groupes, personnes, entreprises, argent, etc.
Le NER utilise
- Pattern matching : Recherche de majuscules, titres (M., Dr.), listes d’entités connues
- Indices contextuels : Des mots comme “travaille chez” suggèrent qu’une organisation suit
- Modèles statistiques : Entraînés sur des données étiquetées pour reconnaître les motifs d’entités
Les modèles et règles NER sont spécifiques à chaque langue

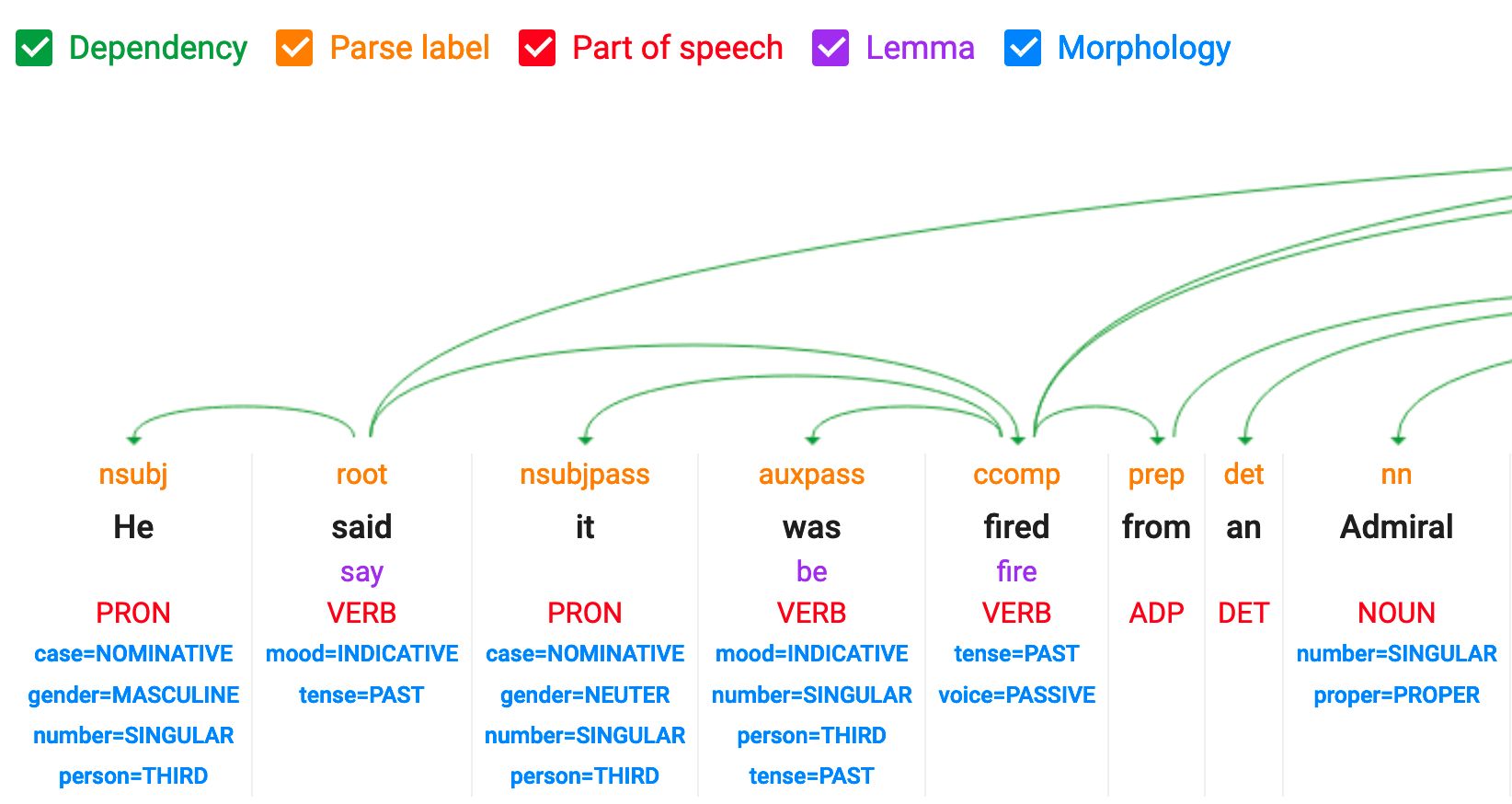
POS : étiquetage des parties du discours
Identifier la fonction grammaticale de chaque mot : ADJ, NOUN, VERBs, etc.
Le POS utilise :
- Terminaisons de mots : “-ment” souvent = adverbe, “-tion” souvent = nom
- Règles de position : Les déterminants (“le”) viennent avant les noms
- Contexte : Le même mot peut être nom ou verbe (“cours” vs “je cours”)
Les modèles et règles POS sont également spécifiques à chaque langue

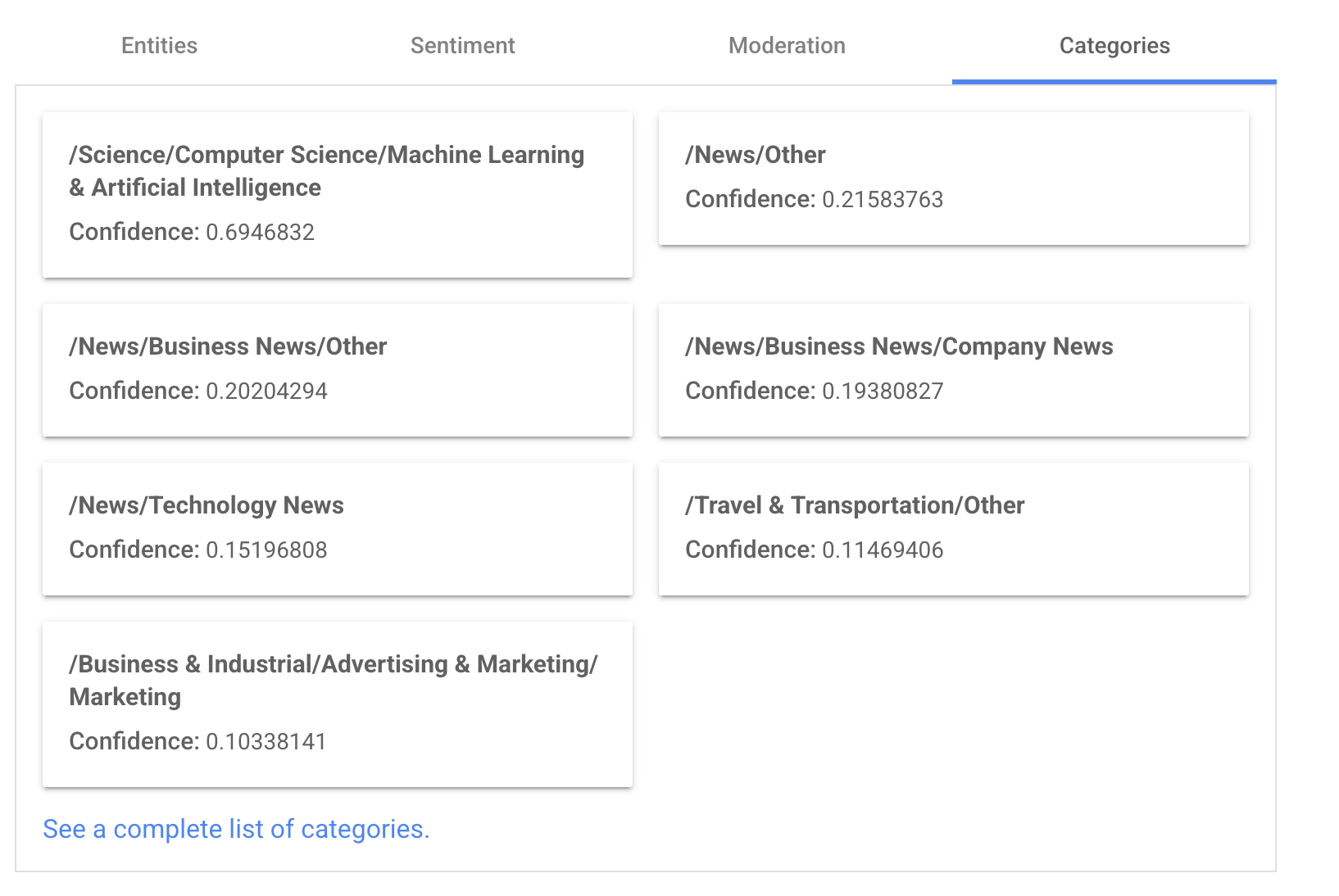
NER

Classification
- scoring de sentiment
- catégories
- Modération
POS : part of speech et dependency tagging
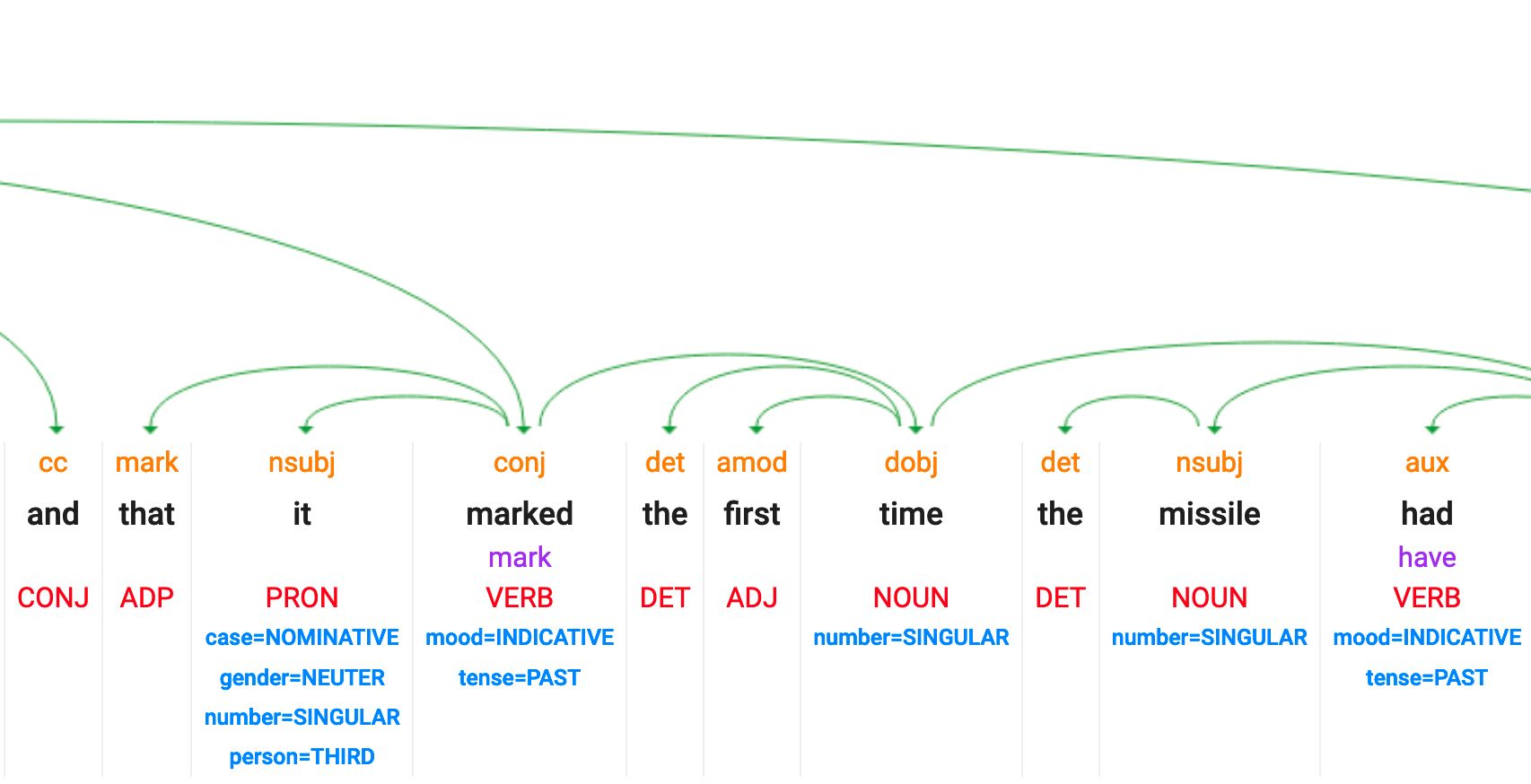
Malheureusement, cette fonctionnalité n’est plus disponible dans la démo NLP de Google.

API NYT
Offre un accès gratuit : developer.nytimes.com/apis
suivez les instructions sur developer.nytimes.com/get-started
- ouvrez un compte sur le site développeur du NYT
- créez une application
- obtenez une clé API
