Restore a database from a sql dump
Download the treesdb_v01.sql.gz file in the github repo
go to: https://github.com/SkatAI/epitadb/tree/master/data
click right on the filename and save link as
You can also clone the repo if you have git installed
git clone [email protected]:SkatAI/epitadb.git
or just get the link to the file (click right on the filename and copy link) and use curl or wget to download the file
wget https://github.com/SkatAI/epitadb/blob/master/data/treesdb_v01.sql.gz
Once you have the file on your local you can restore it.
Create the database first
But first you must create the database
either in pgAdmin (click right on serrver name and create
bash database; check the encoding is UTF8) or with the query
CREATE DATABASE treesdb_v01
WITH
OWNER = alexis
ENCODING = 'UTF8'
LOCALE_PROVIDER = 'libc'
CONNECTION LIMIT = -1
IS_TEMPLATE = False;
replace the owner name (alexis) with your username
Restore the database
Then restore the database with
In the terminal
pg_restore --username "your_username" \
--no-password \
--dbname "treesdb_v01" \
--section=pre-data \
--section=data \
--section=post-data \
--verbose "your path to/treesdb_v01.sql.gz"
in pgAdmin
In the restore dialog:
- Set “Format” to “Custom or tar”
- Browse and select your dump file (treesdb_v01.sql.gz).
- In the “Sections” tab, make sure “Pre-data”, “Data”, and “Post-data” are all checked. (not sure that’s even required)
Check the data
You should have a single table called trees with the columns we saw last week.
treesdb_v01=# \d trees
Table "public.trees"
Column | Type | Collation | Nullable | Default
----------------+-------------------+-----------+----------+---------
idbase | integer | | |
location_type | character varying | | |
domain | character varying | | |
arrondissement | character varying | | |
suppl_address | character varying | | |
number | character varying | | |
address | character varying | | |
id_location | character varying | | |
name | character varying | | |
genre | character varying | | |
species | character varying | | |
variety | character varying | | |
circumference | integer | | |
height | integer | | |
stage | character varying | | |
remarkable | character varying | | |
geo_point_2d | character varying | | |
Accents and the Encoding
We need the database to be UTF8 encoded for the Paris trees data.
if you notice that the accent in some columns are not properly encoded for instance é is displayed as é, à as à …
UPDATE trees SET column_name = convert_from(convert_to(column_name, 'LATIN1'), 'UTF8')
do that for the columns : name, genre, species, variety, address …
you can also check that server, client and table are UTF8 encoded with
SHOW server_encoding;
SHOW client_encoding;
SELECT pg_encoding_to_char(encoding) FROM pg_database WHERE datname = 'treesdb';
This is a version of the database with the proper encoding.
create the new database
- create a new database called treesdb_02
- set the user to your usename (should appear in the dropdown)
- set the encoding to UTF8
The SQL tab should show
CREATE DATABASE treesdb_02
WITH
OWNER = alexis
ENCODING = 'UTF8'
LOCALE_PROVIDER = 'libc'
CONNECTION LIMIT = -1
IS_TEMPLATE = False;
restore the database
Then click right on the treesdb_02 database and click on restore
- select the filename treesdb_v02.sql.gz,
- select format custom or tar
- click restore
The command line equivalent is
pg_restore --host "localhost" \
--port "5432" \
--username "alexis" \
--no-password \
--dbname "treesdb_02" \
"/Users/alexis/work/epitadb/data/treesdb_02.sql.gz"
while the db is restored, look at the process
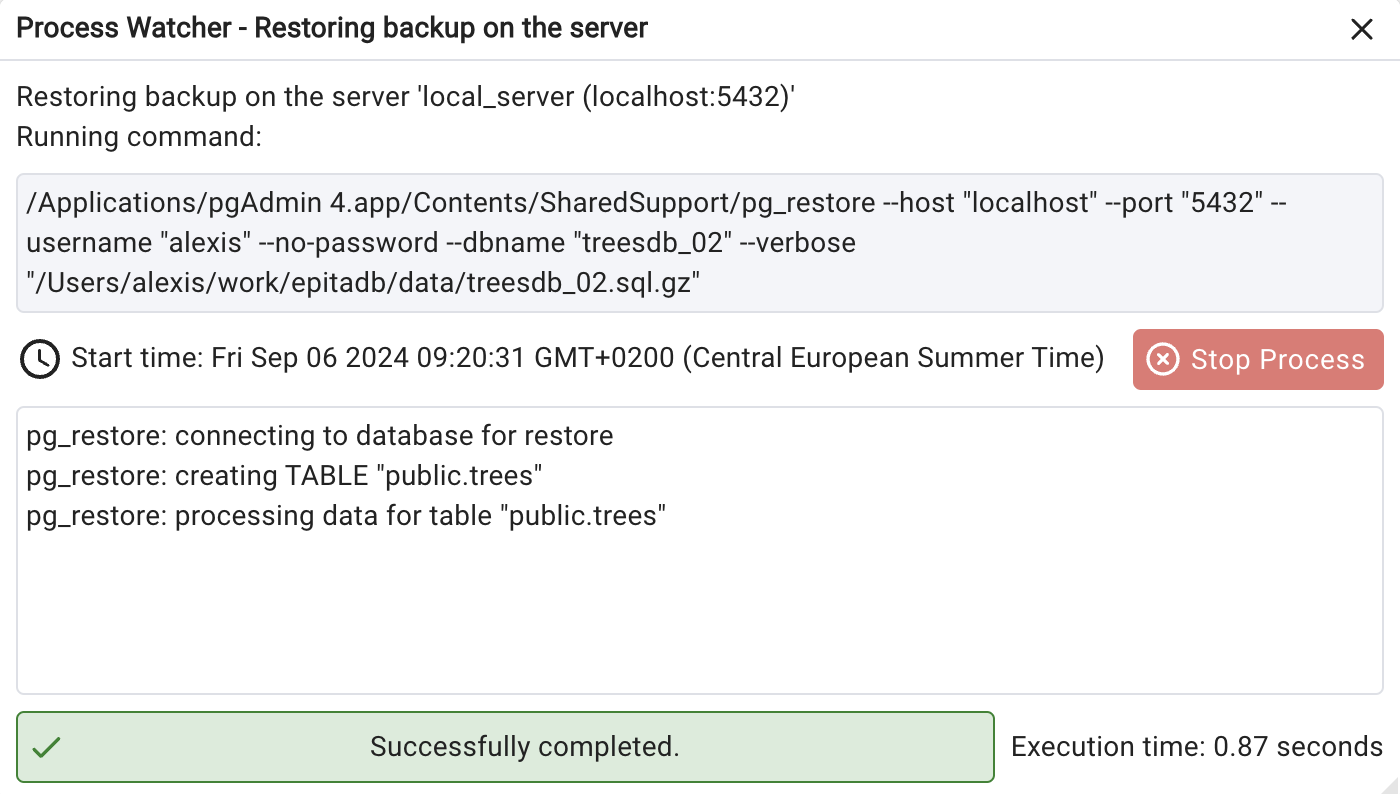
Then check that the tree table has been created in the public schema of the treesdb_02 database
- select random rows
- \d trees
Practice 1 - load data from csv
Your mission: to load data from a csv file into a local postgresql database table using psql
The Paris open data portal has many datasets.
My favorite is the one with all the trees of Paris. But there are many others for instance the locations of film shootings.
In this exercise we will work with the trees of paris with over 210.000 trees. https://opendata.paris.fr/explore/dataset/les-arbres/
The raw csv file is available here. But we will work with this one instead since the header of the csv file is not compatible with postgres column naming conventions! https://raw.githubusercontent.com/SkatAI/epitadb/master/data/les_arbres_upload.csv
Steps
- download the dataset
- create a new database called treesdb
- using createdb createdb -U postgres treesdb
- or psql’ing into the postgres db and CREATE DATABASE treesdb;
- connect to your database with psql
- psql treesdb
- in psql create the table and specify the table_name and the columns CREATE TABLE table_name ( column1 DATA_TYPE, column2 DATA_TYPE, column3 DATA_TYPE -- Add more columns as needed );
- Then import the csv data with
\COPY trees FROM ‘/path/to/your/file.csv’ WITH CSV HEADER DELIMITER ‘;’;
- warning, in France the delimiter is often a semicolon ‘;’ instead of a comma ‘,’
- query your table
You may have to deal with 2 issues
- line returns
- accents and encoding
PostgresQL Column naming conventions
- Column names can be up to 63 bytes long.
- Names must start with a letter (a-z) or an underscore (_).
- Subsequent characters can be letters, underscores, digits (0-9), or dollar signs ($).
- PostgreSQL treats column names as case-insensitive by default.
- Use snake_case: lowercase with underscores between words : (e.g., first_name, date_of_birth).
The header of the tree dataset is not compatible with postgres column naming conventions! use this dataset instead
Create the table
Note you can use chatGPT to generate the table creation query. Just give an example of the header line plus a couple of lines from the csv file and ask to create a table definition. But do check that the types and column names are correct.
CREATE TABLE trees ( idbase INTEGER, location_type VARCHAR, domain VARCHAR, arrondissement VARCHAR, suppl_address VARCHAR, number VARCHAR, address VARCHAR, id_location VARCHAR, name VARCHAR, genre VARCHAR, species VARCHAR, variety VARCHAR, circumference INTEGER, height INTEGER, stage VARCHAR, remarquable VARCHAR, geo_point_2d VARCHAR );
- upload the data with \COPY trees FROM ‘les_arbres_upload.csv’ WITH CSV HEADER DELIMITER ‘;’;
Unix vs Windows: line returns and encoding
You may see the following error : ERROR: unquoted carriage return found in data In that case you need to convert windows style line returns to unix ones as you load the data \COPY trees FROM PROGRAM ‘iconv -f ISO-8859-1 -t UTF-8 les_arbres_upload_utf8.csv | dos2unix’ WITH CSV HEADER DELIMITER ‘;’ QUOTE ‘”’;
Note on mac if dos2unix is not installed, you can install it with brew install dos2unix
![][image1]
And to verify that you have uploaded all the rows: ![][image2]
Accents
Depending on your local settings, the accents may or may not have been correctly encoded.
- How can you deal with encoding so that the accents are properly preserved ?