Postgresql windows functions and CTEs
Intermediate databases - Epita Fall 2025 - Windows functions
Window function
Load the movies db data
we work on the normilized version of the movies db
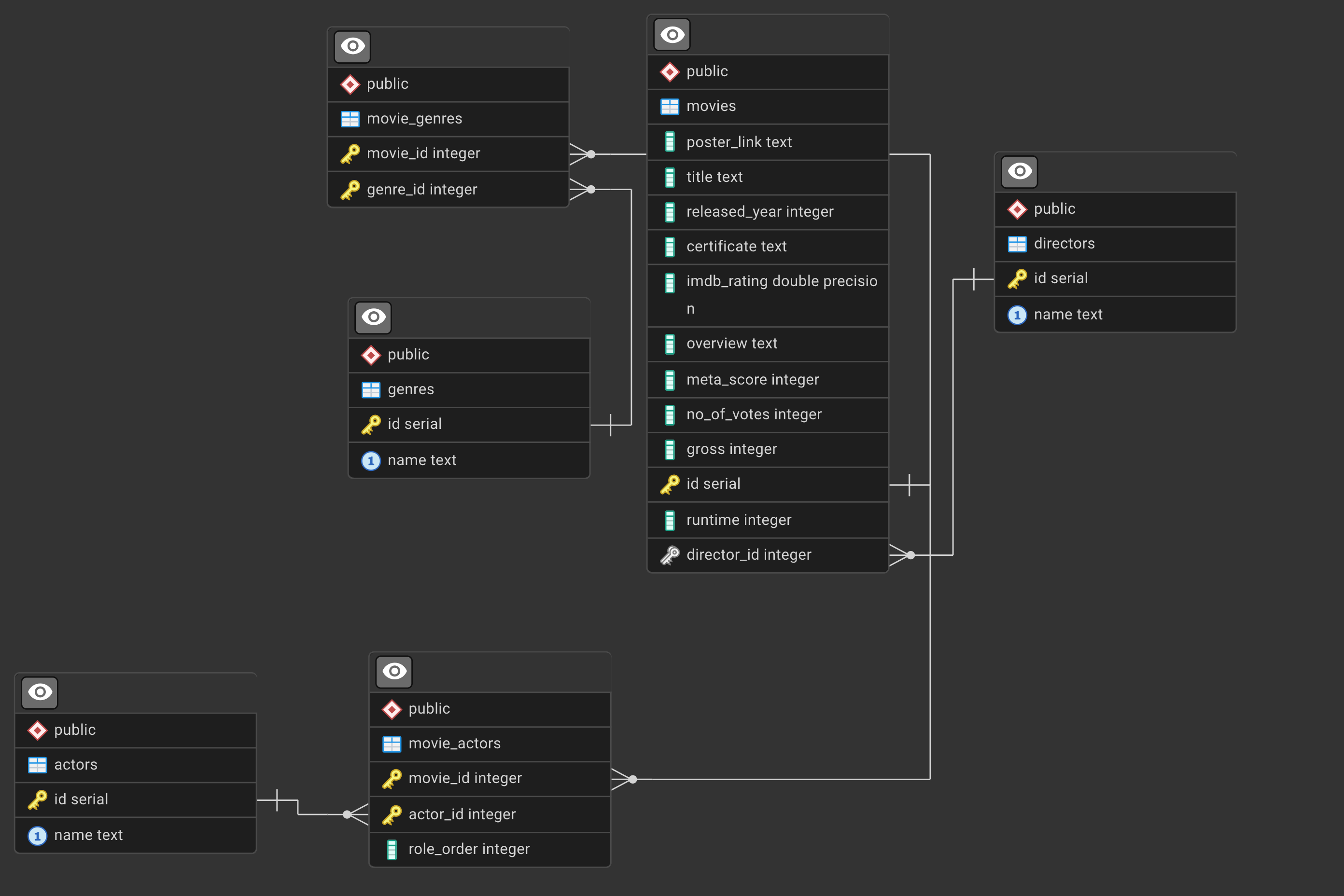
Download the sql file from https://skatai.com/assets/db/moviesdb_normalized.sql
Then load the sql dump with psql
psql -d postgres -f assets/db/moviesdb_normalized.sql
You should see a new database called moviesdb_normalized in the list of databases.
Refresher on group by
GROUP BY is a SQL clause that combines rows with the same values in specified columns into summary rows.
It collapses multiple rows into single rows based on common values, allowing you to calculate aggregate statistics (like COUNT, SUM, AVG) for each group.
Simple analogy: sorting a deck of cards into piles by suit. GROUP BY creates the piles (groups), and aggregate functions tell you something about each pile (how many cards, average value, etc.).
Example in plain English:
SELECT genre, COUNT(*)
FROM movies
GROUP BY genre
This says: “For each unique genre, count how many movies belong to it.”
Examples
- BASIC GROUP BY: Count movies per release year The fundamental GROUP BY pattern
SELECT
COUNT(*) as movie_count, released_year
FROM movies
WHERE released_year IS NOT NULL
GROUP BY released_year
ORDER BY released_year DESC
LIMIT 50;
- GROUP BY with JOIN: Movies per genre GROUP BY after joining tables
SELECT
g.name as genre,
COUNT(DISTINCT mg.movie_id) as movie_count
FROM genres g
LEFT JOIN movie_genres mg ON g.id = mg.genre_id
GROUP BY g.name
ORDER BY movie_count DESC;
#What are Window functions ?
Window Functions perform calculations across a set of rows that are related to the current row, but unlike GROUP BY, they don’t collapse the rows into a single output row. Each row keeps its identity while gaining additional calculated information.
Imagine a spreadsheet where you can see your row’s data AND compare it to other rows (like “what’s the average?”). The window is the set of rows you’re looking at for each calculation.
Let’s say we run a SUM() of some column on a whole table and then run a select query on the database.
The goal is not only to calculate the SUM() …
SELECT SUM(some_column ) from some_table;
# 12
… but to have the result as an extra column collated to the rows returned by the query.
| col 1 | col 2 | … | result of SUM() |
|---|---|---|---|
| abc | cde | … | 12 |
| wer | sdf | … | 12 |
| … | … | … | … |
| zyh | yup | … | 12 |
Aggregate functions as window functions
Aggregate functions like MAX(), MIN(), AVG(), SUM(), COUNT() etc can also be used as window functions. And then functions such as ROW NUMBER(), RANK(), DENSE RANK(), LEAD(), LAG() are specific to window functions.
These functions are commonly used across most of the popular RDBMS such as Oracle, MySQL, PostgreSQL, Microsoft SQL Server etc.
Windows function use 2 clauses:
OVER()Partition Byto specify the column based on which different windows needs to be created.
The OVER() clause
Say, we want to find the maximum gross revenue across all movies.
select max(gross) as max_gross from movies
Now we want to add that max_gross value as a column when returning all the rows.
We can use a subquery
select title,
released_year,
(select max(gross) from movies) as max_gross
from movies;
Adding subqueries for extra columns is fine but makes queries hard to understand and is not very efficient
We can have the exact same result by using the OVER() clause in the previous query
select title,
released_year,
max(gross) OVER() as max_gross
from movies ;
Here the OVER() clause just creates a window OVER the whole table and applies the MAX() function OVER that window.
Max gross by released_year
Now we want to find the max gross for each released_year.
Instead of just returning a 2 column results with max(gross) and released year that we get with a GROUP BY
select max(gross) as max_gross, released_year from movies group by released_year
| max_gross | released_year |
|---|---|
| 36 | 1999 |
| 46 | 2000 |
| 53 | 2001 |
we want to return more information per row in the db and add the extra max_gross column calculated for each released_year.
We want to have:
| id | title | released_year | … | max_gross |
|---|---|---|---|---|
| 301 | Salif Keita | Sina | … | 32 |
| 302 | Salif Keita | Tekere | … | 32 |
| 302 | Salif Keita | something else | … | 32 |
| 203 | Jónsi | Tornado | … | 30 |
| 201 | Jónsi | Kolniður | … | 30 |
Partition BY
This is where partition by comes in:
partition by <column name>specifies the window, the subset of rows, over which to apply themax()function.
This query add max_gross by released_year column to the list of movies.
select title, released_year,
max(gross) over(partition by released_year) as max_gross
from movies
LIMIT 50;
or more usefull
SELECT title, released_year, gross,
AVG(gross) OVER(PARTITION BY released_year)::INT as avg_gross,
COUNT(*) OVER(PARTITION BY released_year) as movie_count
FROM movies
WHERE gross IS NOT NULL
ORDER BY released_year DESC
LIMIT 50;
In short, the OVER() clause specifies to SQL that you need to create a a subset of records
- without specifying a column in the OVER clause, SQL creates one window function over all the records
- the
partition byclause indicates what column you want to group the subsets on
In the above query,
OVER(PARTITION BY artist)creates one window for all tracks (rows) for each given artist- and calculate the
MAX(popularity)in each window
General case
The general query is :
SELECT <list of columns>,
SOME_FCT(<main_column_name>) OVER(PARTITION BY <other_column_name> ) AS some_alias
FROM <table> ;
This works with other aggregate functions such as: max(), min(), avg(), count(), sum()
Stats
So we can combine them to get some stats for each movie.
SELECT
certificate,
title,
imdb_rating,
ROUND(AVG(imdb_rating) OVER(PARTITION BY certificate)::numeric, 2) AS avg_rating_by_cert,
MIN(imdb_rating) OVER(PARTITION BY certificate) AS min_rating_by_cert,
MAX(imdb_rating) OVER(PARTITION BY certificate) AS max_rating_by_cert,
COUNT(*) OVER(PARTITION BY certificate) AS movies_in_cert
FROM movies
WHERE certificate IS NOT NULL
AND certificate != ''
AND imdb_rating IS NOT NULL
ORDER BY certificate, imdb_rating DESC;
functions specific to window functions
There are 5 functions that are specific to window functions unlike functions that can be used within or outside of windows functions.
These 5 functions are used to
- number the in-window rows sequentially :
ROW_NUMBER(), RANK, DENSE RANK() - get a column value from a previous or next row:
LAG(), LEAD()
ROW_NUMBER()
ROW_NUMBER() assigns a unique value to each records in each window
Without specifying a partition, we get an index over all the records
select id, title,
row_number() over() as rn
from movies
order by title
limit 10;
Note that, you could use row_number to generate a new sequential primary key.
More interestingly if we want to restart the row number per released_year, we add PARTITION BY released_year in the OVER clause:
select id, title, released_year,
row_number() over(partition by released_year) as rn
from movies
where released_year is not null
order by released_year asc, title asc
limit 20;
The rn is reset to 1 for each released_year.
When is that useful ?
When ordering the rows by some column, you can fetch the top or bottom movies.
For instance, let’s fetch
the top 2 movies with the highest gross from each released_year
by:
- adding an
order on grossin theOVERclause - putting these results in a subquery
- and adding a filter on
rn
- add order by gross desc in the OVER() clause
select id, title, released_year, gross,
row_number() OVER(partition by released_year order by gross desc) as rn
from movies
where released_year is not null
and released_year > 1938
and gross is not null
order by released_year asc, rn asc
limit 20;
- then use that as a subquery (called subset) and filter
to get the top 3 movies with most revenue per year
select * from (
select id, title, released_year, gross,
row_number() OVER(partition by released_year order by gross desc) as rn
from movies
where released_year is not null
and released_year > 1938
and gross is not null
order by released_year asc, rn asc
) subset
where subset.rn < 4
limit 20;
Deleting duplicates
ROW_NUMBER() is also useful to find and delete duplicates in a table.
A general duplicates deletion query would look like this (fast forwarding into CTEs)
Using a a named subquery (WITH duplicates AS) or CTE and partitioning by the columns that are representative of duplicated rows and then deleting from the results of that subquery where the row number indicates a duplicate (i.e. rn > 1).
WITH duplicates AS (
SELECT
id,
ROW_NUMBER() OVER (
PARTITION BY <columns that are duplicated>
ORDER BY insert_date DESC
) AS rn
FROM movies
)
DELETE FROM movies
WHERE id IN (
SELECT id FROM duplicates
WHERE rn > 1
);
RANK()
To fetch the most popular movies and number the movies by imdb_rating:
SELECT
title,
imdb_rating,
ROW_NUMBER() OVER(ORDER BY imdb_rating DESC) AS rn
FROM movies
WHERE imdb_rating IS NOT NULL
ORDER BY imdb_rating DESC, title
LIMIT 20;
but some movies have the same imdb rating and yet have different row numbers.
Using rank() we can assign equal row numbers to movies with equal rating scores.
SELECT
title,
imdb_rating,
ROW_NUMBER() OVER(ORDER BY imdb_rating DESC) AS row_rn,
RANK() OVER(ORDER BY imdb_rating DESC) AS rank_rnk
FROM movies
WHERE imdb_rating IS NOT NULL
ORDER BY imdb_rating DESC, title
LIMIT 20;
Equal values will have the same rank
so rank can be 1, 2, 2, 4
so top 2 most popular movies per year
select * from (
SELECT
title,
imdb_rating, released_year,
RANK() OVER(partition by released_year ORDER BY imdb_rating DESC) AS rank_rnk
FROM movies
WHERE imdb_rating IS NOT NULL
-- select t.id, t.artist, t.track, t.year, t.popularity,
-- rank() over(partition by year order by popularity desc) as rnk
-- from tracks t
) pop
where pop.rank_rnk < 2;
dense_rank()
dense_rank() similar to rank but will increment the rank without jumps in numbers
We can compare row_number(), rank() and dense_rank() in the following query
SELECT
title, released_year,
imdb_rating,
ROW_NUMBER() OVER(partition by released_year ORDER BY imdb_rating DESC) AS row_rn,
RANK() OVER(partition by released_year ORDER BY imdb_rating DESC) AS rank_rn,
DENSE_RANK() OVER(partition by released_year ORDER BY imdb_rating DESC) AS dense_rank
FROM movies
WHERE imdb_rating IS NOT NULL
and released_year in (2017, 2018)
ORDER BY released_year desc, imdb_rating DESC, title
LIMIT 20;
LEAD() and LAG()
We want to find the number of movies year on year.
SELECT
released_year,
COUNT(*) AS movie_count,
LAG(COUNT(*)) OVER(ORDER BY released_year) AS prev_year_count,
LEAD(COUNT(*)) OVER(ORDER BY released_year) AS next_year_count,
COUNT(*) - LAG(COUNT(*)) OVER(ORDER BY released_year) AS count_change
FROM movies
WHERE released_year IS NOT NULL
GROUP BY released_year
ORDER BY released_year DESC
LIMIT 20;
LAG() and LEAD() take arguments:
LAG(column, offset, default)
- LAG(column)
- LAG(column, N rows)
- LAG(column, N rows, default value)
so lag(imdb_rating, 2, 0) looks 2 rows before the currrent row and 0 is a default value
comparing to previous year’s average
SELECT
released_year,
ROUND(AVG(imdb_rating)::numeric, 2) AS avg_rating,
LAG(ROUND(AVG(imdb_rating)::numeric, 2), 1, ROUND(AVG(imdb_rating)::numeric, 2))
OVER(ORDER BY released_year) AS prev_year_avg,
ROUND(AVG(imdb_rating)::numeric, 2) -
LAG(ROUND(AVG(imdb_rating)::numeric, 2), 1, ROUND(AVG(imdb_rating)::numeric, 2))
OVER(ORDER BY released_year) AS year_over_year_change
FROM movies
WHERE released_year IS NOT NULL
AND imdb_rating IS NOT NULL
GROUP BY released_year
ORDER BY released_year DESC
LIMIT 20;
LEAD() is the same as LAG() except that it gets the value of the row(s) following the current record.