Normalization and advanced querying
In this worksheet you will:
- load a SQL backup of the worldhits database
- normalize the database
- use CTEs and window functions to query the database
- store the results of the queries into tables
- export your database as a SQL backup
- upload your final database backup as a sql file in a google form
The google form is available at this address: https://forms.gle/dqBZiRGjH8rn24dg7.
Make sure to
- fill in your name and Epita email address
- answer the question(s)
- at the end, pg_dumpupload your database sql file
- if you have not finished the worksheet, backup your file and submit it as is
you must provide a SQL file backup, not a binary file. If you are not sure how to do that, ask me.
Important rules
- you have online access: google, postgres documentation etc
- do not use a chatgpt or any other AI tool to answer the questions. I will know. It’s easy to spot.
I. Data
The data is the worldhits dataset from spotify
This dataset is a curated collection of world music, featuring 326 tracks from 66 diverse artists spanning six decades, from 1958 to 2019. It offers a rich tapestry of global sounds, from traditional rhythms to contemporary fusions. Each track is meticulously tagged with Spotify audio features, providing insights into tempo, key, energy, and more. This dataset is ideal for exploring the evolution of world music, analyzing trends across different cultures, or even training machine learning models to recognize unique musical patterns. Whether you’re a researcher, data scientist, or music enthusiast, this dataset offers a fascinating glimpse into the world’s rich musical heritage.
You can read the data reference : Spotify 300 world music tracks
It is a very clean dataset. There are no NULL values, no outliers, no crazy stuff.
Load the data
Download the SQL backup from https://skatai.com/assets/db/worldhits_backup.sql
You can restore the database
- from the terminal
psql -d postgres -f <path to your file>/worldhits_backup.sql
- in a psql session
\i <path to your file>/worldhits_backup.sql
This will create a new database : worldhitsdb
Once the database is restored, connect to the newly created database with
\c worldhitsdb
The database
The database is just one table : tracks with the following columns
select * from tracks limit 5;
\d tracks
Table "public.tracks"
Column | Type | Collation | Nullable | Default
------------------+------------------------+-----------+----------+------------------------------------
id | integer | | not null | nextval('tracks_id_seq'::regclass)
track | character varying(255) | | |
artist | character varying(255) | | |
album | character varying(255) | | |
year | integer | | |
duration | integer | | |
time_signature | integer | | |
danceability | double precision | | |
energy | double precision | | |
key | integer | | |
loudness | double precision | | |
mode | integer | | |
speechiness | double precision | | |
acousticness | double precision | | |
instrumentalness | double precision | | |
liveness | double precision | | |
valence | double precision | | |
tempo | double precision | | |
popularity | integer | | |
Indexes:
"tracks_pkey" PRIMARY KEY, btree (id)
The table has 326 rows.
II. Anomalies
Anomalies and the artist column
Run the following query to understand the artist column. How many tracks per artist.
select count(*) as n , artist
from tracks
group by artist
order by n DESC limit 10;
Change the order to ASC to see the least frequent artists.
Spot the update, delete and insert anomalies with respect to the artist column.
Explain in the google form how the artist column can suffer from each type of anomaly.
III. Normalization
In this section you will normalize the artist column of the database
Follow the process:
- create a
artiststable withid(primary key) andnamecolumn - insert the
UNIQUEartists names from the originaltrackstable - add a artist_id foreign key in the
trackstable- first add a INTEGER artist_id column
- then ADD CONSTRAINT to make it a foreign key
- reconcile the
tracks.artist_idwith theartist.id.- hint use the
artist.name = tracks.artistcondition in the UPDATE statement
- hint use the
- double check that the artists table
- has 66 rows
- the artist names are unique
- the list of tracks for
Deepak DevisMazha PaadumandNilakudame
- Once you are sure that the data has been imported, delete the original
artistcolumn from the tracks table.
IV. First backup
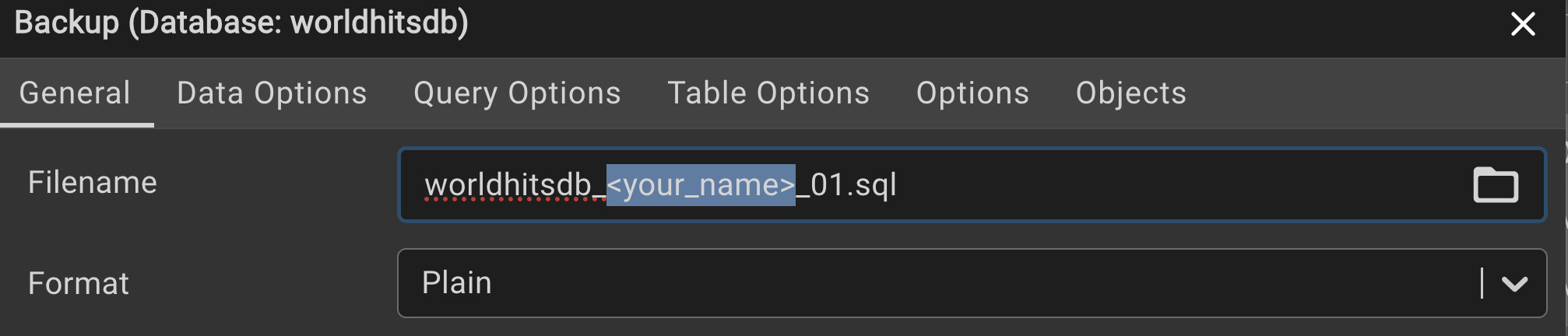
Once you have normalized the artist column, backup your database as plain sql file
- the filename should be: **worldhitsdb_
_01.sql**. - no spaces in the filename.
If you are using the terminal, run the following command to backup the database. replace the filename placeholder with your filename
pg_dump --file "worldhitsdb_<your_name>_01.sql" --format=p "worldhitsdb"
in a psql session just add \! before the command
\! pg_dump --file "worldhitsdb_<your_name>_01.sql" --format=p "worldhitsdb"
on windows you can use
\! "C:\Program Files\PostgreSQL\<version>\bin\pg_dump.exe" --file "worldhitsdb_<your_name>_01.sql" --format=p "worldhitsdb"
or you can use pgadmin.
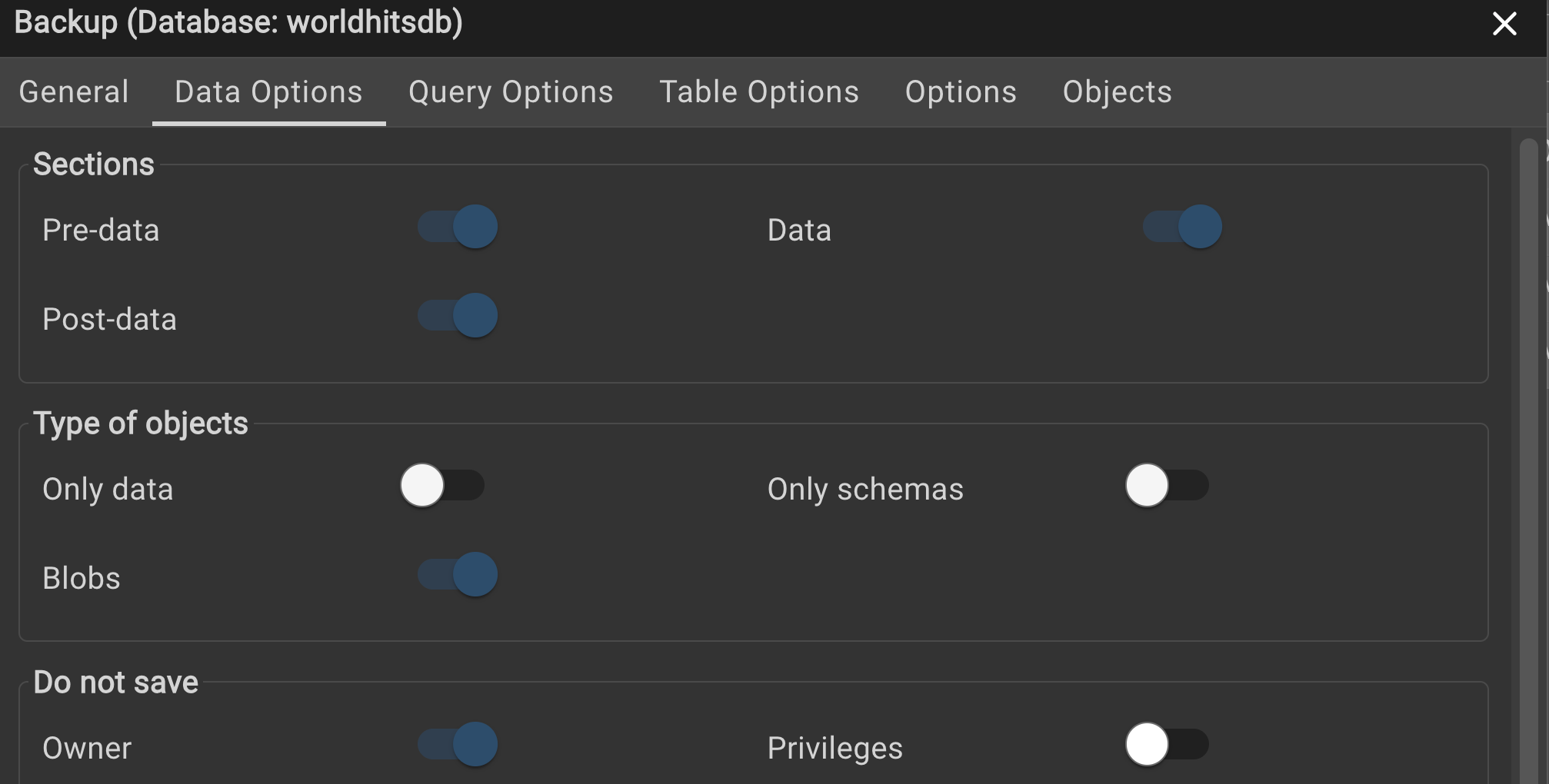
Make sure
- to select the plain format
- and in the data tab, check “no owner”
Once the you have the first SQL backup of the database, upload it using the google form
Saving the query results into tables
You can store the output of any query into its own table with
CREATE TABLE tracks_analysis_results AS
<your query>
For instance, this query will create a table called artist_track_count with the number of tracks per artist and the artist name.
CREATE TABLE artist_track_count AS
select count(*) as track_count, a.name
from tracks t
join artists a on t.artist_id = a.id
group by a.name
order by a.name desc;
Run that query and check that the table has been created.
In the following questions you are asked to write queries and store the results into tables. The table name will be given.
V. Window functions
You can refer to the window functions postgres documentationor course slides (window functions).
V.1. Compare Artists popularity
Write a query that compares each track’s popularity to the average popularity of their artist.
store the query result into a table called
artist_popularity.
The output should look like (this is only the first row)
| track | artist_name | popularity | artist_avg_popularity |
|---|---|---|---|
| When You’re Falling | Afro Celt Sound System | 36 | 29.00 |
- hint : use
AVG ... OVER (PARTITION BY ...)for the avg popularity - alias artist.name as artist_name
- make sure to
ROUNDthe avg popularity to 2 decimal places.
V.2. Rank tracks by energy
Rank all tracks by energy for each artist
Store the query result into a table called
artist_energy_rank
- use
RANK() OVER()for energy_rank - in the
OVERclause, usePARTITION BYandORDER BY
The output should be similar to
track | artist_name | energy | energy_rank
---------------------------------+------------------------+--------+-------------
To the End of the World | Pat Metheny Group | 0.54 | 1
Last Train Home | Pat Metheny Group | 0.488 | 2
The Way Up: Opening & Part One | Pat Metheny Group | 0.41 | 3
Phase Dance | Pat Metheny Group | 0.399 | 4
VI. CTE with clause
In the following section, you will write CTE queries.
- first write the main query
- then name the CTE and select from it
VI.1. Compare popularity with tempo for each artist
Write a query that calculates each artist average popularity and tempo, and ranks them on both metrics.
store the final query result into a table called
artist_popularity_tempo_rank
The 1st query will calculate each artist avg_popularity and avg_tempo by grouping by artist name.
The 1st query results will look like that
id | artist_name | track_count | avg_popularity | avg_tempo
----+--------------------+-------------+---------------------+--------------------
54 | Ofra Haza | 7 | 13.0000000000000000 | 125.89957142857143
29 | Enya | 7 | 54.4285714285714286 | 92.07600000000001
4 | Ali Mohammed Birra | 5 | 19.0000000000000000 | 143.159
Now, name that query (for instance artist_stats) and select from it.
WITH artist_stats as (
<1st query>
)
SELECT ...
from artist_stats
ORDER BY popularity_rank, tempo_rank;
The main query will rank the artists using a DENSE_RANK window function ordered by avg_popularity + avg_tempo
The final results should look like
artist | track_count | artist_avg_popularity | artist_avg_tempo | popularity_rank | tempo_rank
-------------------+-------------+-----------------------+------------------+-----------------+------------
Manu Chao | 9 | 59.78 | 129.90 | 1 | 8
Enya | 7 | 54.43 | 92.08 | 2 | 52
Ilaiyaraaja | 5 | 50.80 | 127.36 | 3 | 13
store the final query result into a table called
artist_popularity_tempo_rank
hints:
- Use GROUP BY with the artist: When calculating averages per artist, group by a.name:
- Apply aggregations for averages: Use
AVG()function on the tracks’ columns popularity and tempo - Don’t forget
ROUND(...::numeric, 2)for clean numbers - you need to cast avg_tempo and avg_popularioty to numeric for the DENSE_RANK() window function to work
- use DENSE_RANK() window functions
- [optional] Filter with HAVING
HAVINGfilters groups AFTER aggregation:HAVING COUNT(*) >= 3
VI.2 Find each artist’s most popular track
store the final query result into a table called
artist_most_popular_track
first query: Using ROW_NUMBER or RANK or DENSE_RANK (your choice) list the tracks per artist ranked by popularity
The result should look like that
artist | track | popularity | rank
-------------------+--------------------------------+------------+------
Youssou N'Dour | 7 Seconds (feat. Neneh Cherry) | 47 | 1
Youssou N'Dour | Set | 25 | 2
Youssou N'Dour | Salimata | 20 | 3
Youssou N'Dour | Birima | 18 | 4
Youssou N'Dour | Mame Bamba | 16 | 5
Now name the CTE artist_tracks_ranked and select from it to get the most popular track per artist
Save the full query in a table named most_popular_track_per_artist
The final result should look like
artist | track | popularity
----------------------------+--------------------------------+------------
Youssou N'Dour | 7 Seconds (feat. Neneh Cherry) | 47
Vieux Farka Touré | Tongo Barra | 52
The Kingston Trio | Tom Dooley | 41
VI.3 Loudness evolution of the years
Store the query result into a table called
loudness_correlation_with_year
Using a CTE you are going to calculate the correlation of loudness with year
- 1st write a query that groups tracks by year and calculates the average loudness for each year.
-
then name that query and select from it to calculate the correlation of year and avg_loudness
- use
CORRfunction:CORR(year, avg_loudness) - round the result to 3 decimal places
The result should be a single number
loudness_correlation_with_year
--------------------------------
0.386
VI.4 Top 3 fastest and slowest songs per artist
Store the query result into a table called
fast_slow_tracks
The 1st query uses RANK to list the tracks per artist ranked by tempo both for fastest and slowest tracks.
The result shoud look like that
artist | track | tempo | fast_rank | slow_rank
------------------------+---------------------------------+-------+-----------+-----------
Afro Celt Sound System | Saor / Free / News from Nowhere | 82.0 | 4 | 1
Afro Celt Sound System | When You're Falling | 99.0 | 3 | 2
Afro Celt Sound System | Release | 100.1 | 2 | 3
The 2nd query uses the CTE to select the top fastest and top slowest tracks per artist.
Each artists song should be tagged as “Fastest” or “Slowest”
The result should look like :
artist | track | tempo | category
------------------------+------------------------------------+-------+----------
Afro Celt Sound System | Whirl-Y-Reel 1 | 132.0 | Fastest
Afro Celt Sound System | Saor / Free / News from Nowhere | 82.0 | Slowest
Al Di Meola | The Wizard | 157.9 | Fastest
Al Di Meola | Race With Devil On Spanish Highway | 88.6 | Slowest
[optional] Finally, we also want to know the number of tracks per artist
Write another named query that groups by artist and counts the number of tracks per artist.
the end result should look like
artist | track_count | track | tempo | category
------------------------+-------------+------------------------------------+-------+----------
Afro Celt Sound System | 4 | Whirl-Y-Reel 1 | 132.0 | Fastest
Afro Celt Sound System | 4 | Saor / Free / News from Nowhere | 82.0 | Slowest
Al Di Meola | 6 | The Wizard | 157.9 | Fastest
Al Di Meola | 6 | Race With Devil On Spanish Highway | 88.6 | Slowest
VII final backup
Create a new SQL backup of your database.
- the filename should be: **worldhitsdb_
_02.sql**. - no spaces in the filename.
Note the _02 postfix in the filename.
If you are using the terminal, run the following command to backup the database. replace the filename placeholder with your filename
pg_dump --file "worldhitsdb_<your_name>_02.sql" --format=p "worldhitsdb"
or you can use pgadmin.
make sure
- to select the plain format
- and in the data tab, check “no owner”
Once the you have the first SQL backup of the database, upload it using the google form