Course outline
- Lecture 1: Introduction, types of DBMS, modeling methods, normalization
- Tutorial 1: Case study: Modeling
- Lecture 2: Relational databases and SQL language
- Tutorial 2: Case study: SQL query / Relational algebra
- Lab 1–2: Case study: Modeling / Implementation
- Synthesis project (written exam): Complete case study – from modeling to querying
Why a database ?
to organize complex structured data
Spotify example
- users, subscriptions
- devices
- songs
- artists, albums
- playlists
- plays
- etc …
Social Network example
- users, subscriptions
- followers
- engagement
- posts
- media
- etc …
Why learn database ?
SQL in high demand: In 2025 job data, SQL appears in ~26% of software engineer listings and ~80% of data engineering roles — nearly on par with Python.
Core integration skill: SQL is a core integration skill, powering pipelines, ETL, and database queries across backend, analytics, and engineering—not just data engineering.
Database in aerospace
Design & Modeling: Tools like ModelCenter (used by NASA, Airbus) and DLR’s RCE orchestrate CAD, simulation, and optimization workflows, backed by relational/SQL data handling.
Digital Engineering & Integration: Aerospace is adopting digital twins, predictive maintenance, and model-based systems engineering (MBSE), where SQL supports structured data management, cross-tool integration, and traceability.
Maintenance & Operations (MRO): SQL is key for querying structured aircraft maintenance data;
in short:
Big software is SQL based
Digital Twins
A digital twin is a virtual model of a physical object, system, or process that is continuously updated with real-world data.
It’s not just a simulation — it’s a living, data-driven model that mirrors the current state, behavior, and performance of its real-world counterpart.
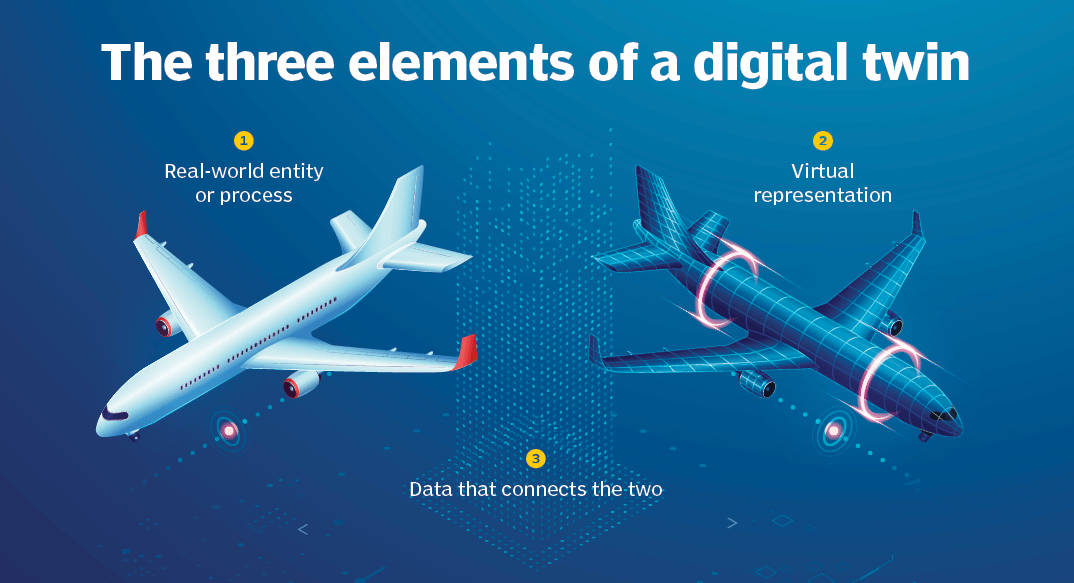
🔗 SQL - Digital Twins
-
Data Ingestion & Storage
- Sensors on engines, satellites, or assembly lines generate telemetry (temperatures, pressures, vibrations, etc.).
- This data flows into relational databases for structured storage.
-
Querying Real-Time States
- Engineers query SQL databases to pull the latest system health data or compare against historical performance.
-
Integration with Simulation & Modeling Tools
- Tools like ModelCenter or RCE (DLR) integrate multiple models. Under the hood, structured data handling (SQL/relational schemas) makes models interoperable.
- SQL ensures different teams (design, manufacturing, maintenance) access a single source of truth.
-
Predictive Analytics Pipelines
- Data engineers use SQL to prepare datasets for ML models that run “what-if” scenarios on the digital twin.
- Example: training a model to predict turbine wear based on SQL queries extracting historical stress data.
-
Lifecycle & Traceability
- Aerospace demands full traceability — every design tweak, test, and maintenance log is stored.
- SQL-backed systems allow auditable histories of the twin and its physical counterpart. This is crucial for safety and certification.
✈️ Aerospace Examples
- Rolls-Royce: Uses digital twins of engines with SQL-based telemetry repositories to optimize flight operations and predict maintenance.
- Airbus: Connects design (CAD), simulation, and IoT sensor data into SQL-backed databases for lifecycle digital twins of aircraft systems.
- ESA: Spacecraft twins rely on SQL schemas to integrate satellite telemetry with orbital simulations for real-time monitoring.
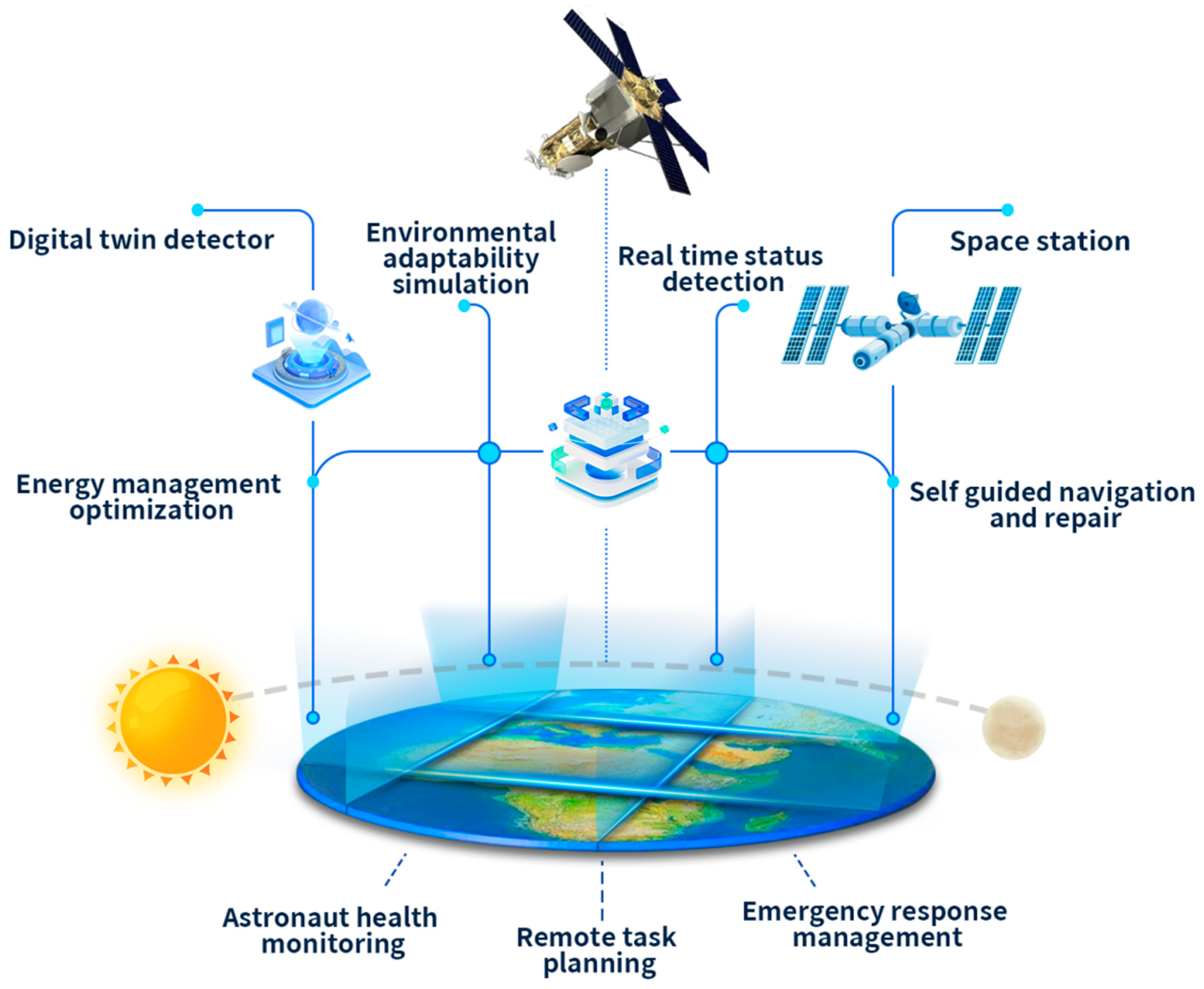
Bottom line:
✅ SQL is the backbone of structured data management for digital twins.
It enables the ingestion, storage, querying, and integration of massive telemetry streams with design and simulation models.
Without SQL (or SQL-like systems), digital twins would struggle to scale or maintain traceability.
By the way, this applies to Finance, Health, Energy, etc…
database vs excel file ?
Why use a database instead of just a spreadsheet or files like json or csv ?
What is a database?

Sometimes we hear the word database used to describe an Excel file. How can we put something as simple as a CSV or Excel file on the same level as these engineering marvels that are PostgreSQL, Weaviate, MongoDB, Neo4j, Redis, MySQL, etc…
A definition
So I asked my friend GPT-5 to give me a definition of a database:
In simple terms: “A database is like a smart notebook or filing system that helps you keep track of lots of information and find exactly what you need in no time.”
which definitely includes CSV files, Excel files, JSON files, XML files, and many other simple file-based formats.
Another definition
From the Encyclopedia Britannica, we get:
database, any collection of data or information specifically organized for rapid search by computer. Databases are structured to facilitate storage, retrieval, modification, and deletion of data.
See also the Database article on Wikipedia.
Not only a filing system
No longer just talking about quickly finding information (the search part) but also about:
- storage
- modification
- deletion
- Administration.
This is where a simple spreadsheet file no longer meets the objective.
Essential functionalities of a DBMS 1/2
| Feature | Description | Excel | DBMS |
|---|---|---|---|
| Data Storage and Retrieval | Stores data in an organized manner and retrieves it as needed. | ✅ | ✅ |
| Data Manipulation | Allows adding, modifying, or deleting data. | ✅ | ✅ |
| Data Querying | Allows asking complex questions (queries) about the data. | ✔️ | ✅ |
Essential functionalities of a DBMS 2/2
| Data Organization | Structures data in formats such as tables, documents, or graphs to facilitate management. | ✅ | ✅ |
| Data Sharing | Allows multiple users or applications to use the database simultaneously. | ✅ | ✅ |
| Data Security | Protects data against unauthorized access or corruption. | ✔️ | ✅ |
| Concurrency Control | Manages multiple users modifying data at the same time without conflicts. | ✅ | |
| Backup and Recovery | Ensures that data is not lost and can be restored in case of failure. | ✔️ | ✅ |
Essential functionalities of a DBMS 3/2
| Data Integrity | Ensures that data remains accurate, consistent, and reliable. | X | ✅ |
| Performance Optimization | Provides tools to optimize the speed and efficiency of data retrievals and updates. | X | ✅ |
| Support for Transactions | Ensures that a group of operations (transactions) is completed entirely or not at all. ACID compliance |
X | ✅ |
ACID compliance
A key feature of a real DBMS is ACID compliance.
- Atomicity: Atomicity guarantees that each transaction is treated as a single “unit”
- Consistency: ensures that a transaction can only bring the database from one consistent state to another
- Isolation: ensures that concurrent execution of transactions leaves the database in the same state that would have been obtained if the transactions were executed sequentially. Isolation is the main goal of concurrency control
- Durability: Durability ensures that once a transaction is committed, it cannot be undone, even in the event of a system failure.
A Brief History of Databases

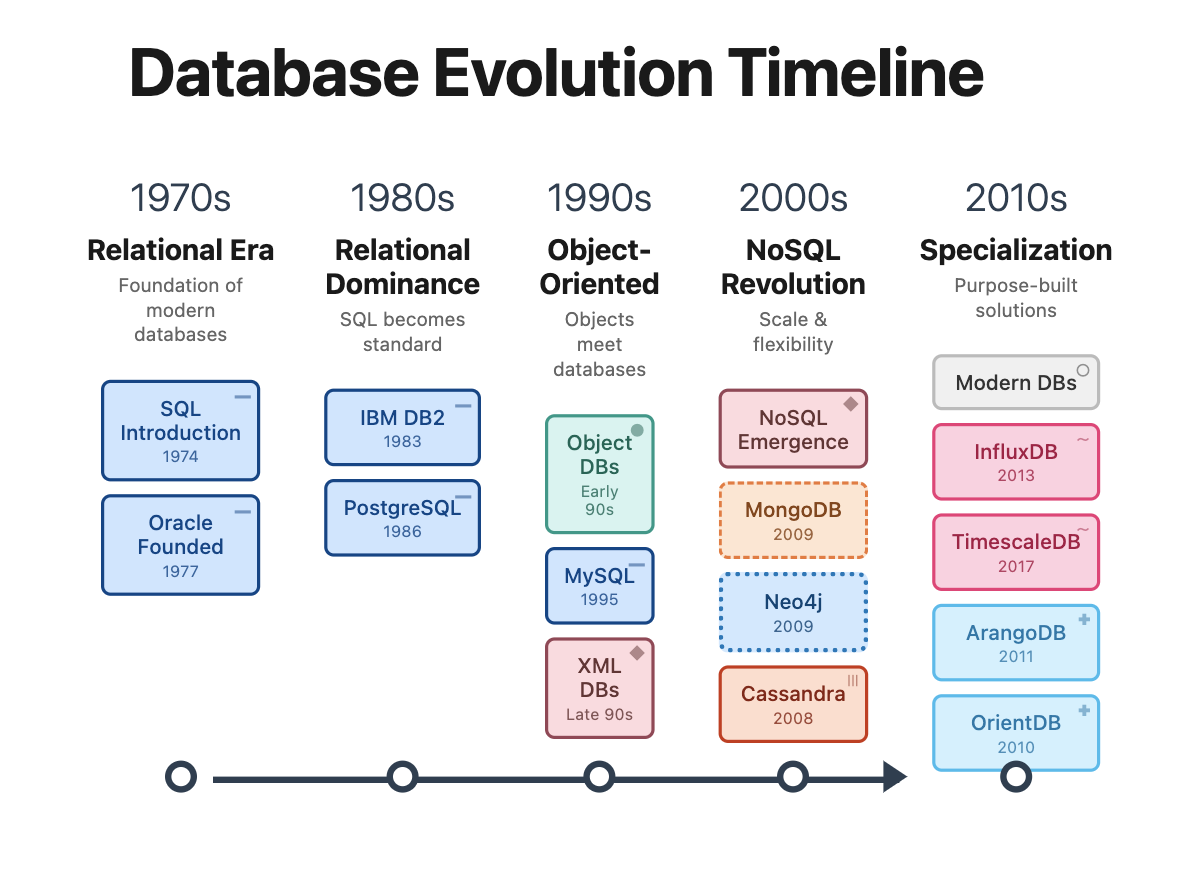
1970s - The Beginning of the Relational Era
- 1970: Edgar Codd publishes “A Relational Model of Data for Large Shared Data Banks”
- 1974: IBM develops System R, the first SQL DBMS prototype
- 1979: Oracle launches the first commercial SQL implementation
1980s - Domination of Relational
- 1989: Beginning of POSTGRES development at UC Berkeley (now PostgreSQL)
- 🎖️🎖️🎖️ the reference SQL database.
- now can handle no-sql & vector,
- numerous extensions (http, postgis, …).
- exceptional performance.
- and OPEN SOURCE (free, efficient, and secure).
1990s - The Object-Oriented Wave
- 1991: Object-Oriented databases gain attention.
Most OODBs from the 90s are no longer used. But they influenced the evolution of both SQL and NoSQL databases.
More inportantly:
- 1995: MySQL is released as open source
2000s - The Beginning of the NoSQL Revolution
- 2 important papers that laid the foundations for NoSQL systems: BigTable paper (Google, 2004) and Dynamo paper (Amazon, 2007)
And in 2009, 2 new NoSQL databases are launched: 🥭 MongoDB 🥭 and 🎉 Neo4j 🎉

![]()
Why at this moment?
The rise of the world wide web (myspace - 2003 😍, youtube - 2005) and the massive increase in application scale by several orders of magnitude.
Suddenly, we have millions of people simultaneously trying to access and modify Terabytes of data in milliseconds.
Relational databases cannot keep up with the scale of applications, the chaotic nature of unstructured data, and the speed requirements.
The promise of NoSQL is volume and speed.
2010s - NoSQL Matures & Specialization - Big Data and Specialized Databases
- Big Data Databases: Systems like Apache Hadoop (2006) and Apache Spark (2009) enabled very large-scale data processing.
- Graph Databases gain popularity with use cases like fraud detection, knowledge graphs, and supply chain management. Neo4j and Amazon Neptune become key players.
- Time-Series Databases (e.g., InfluxDB, TimescaleDB): designed for monitoring systems: IoT, logs, …
- Cloud Databases: managed services like Amazon RDS, Google BigQuery, or Snowflake
and meanwhile, in 2013, Docker containers revolutionize database deployment
2020s: AI, Vector Databases, and Real-Time Needs
- Vector Databases 🌶️🌶️🌶️ (e.g., Pinecone, Weaviate, Qdrant, Milvus, Faiss, …):
- Handle high-dimensional vector embeddings used in AI/ML applications
- and also:
- Graph + AI: knowledge graphs and LLMs (a tech in search of a problem ?).
- Multi-Model Databases that support multiple data models (document, graph, key-value) in a single system.
- Real-Time Analytics: optimized for real-time data streaming and analytics.
- Serverless Databases
Current Trends (2025)
Vector search is booming and most existing DBMS, including PostgreSQL, MongoDB, and Neo4j are integrating vector search capabilities.
In Brief
- 1989: Launch of PostgreSQL
- 2009: Launch of MongoDB and Neo4j
- 2024: vector databases are in vogue while older databases integrate vector search, NoSQL paradigm
What is a relational database
A relational database stores information in tables made up of rows and columns.
- Each
rowis a record - Each
columnis a field - Tables can be linked together using
keys, so you can relate data across them
That’s why it’s called relational, the power comes from defining and using these relationships.
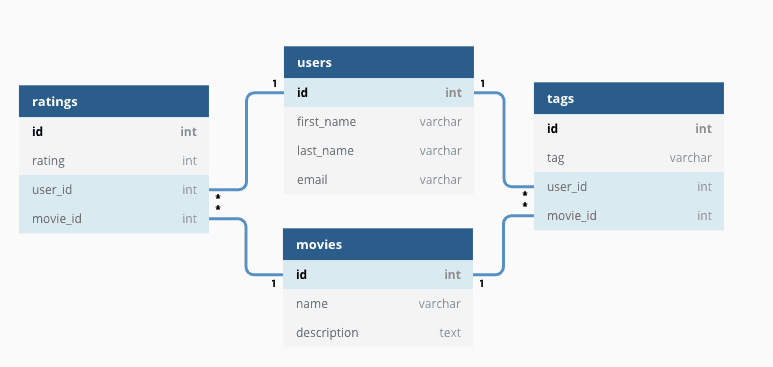
Main Categories of Databases Today
We have many databases to choose from. It all depends on scale, application nature, budget, etc.
| Database Type | Purpose | Examples | Application |
|---|---|---|---|
| Relational - SQL | Fixed schema | PostgreSQL, MySQL, Oracle | Transactions, normalization |
| Document Stores | Flexible schema, JSON-like documents | MongoDB, CouchDB | Web applications, content management |
| Graph Databases | Relationship-centered data | Neo4j, ArangoDB | Social networks, recommendation engines |
| Key-Value Stores | Simple and fast lookups | Redis, DynamoDB | Caching, session management |
| Vector Databases | Similarity search, AI embeddings | Pinecone, Weaviate | AI applications, semantic search |
| Column-Family Stores | Wide-column data, high scalability | Cassandra, HBase | Time-series, big data applications |
| Time-Series Databases | Time-ordered data | InfluxDB, TimescaleDB | IoT, monitoring systems |
Fuzzy separation
- Many databases now include vector types, and search
- postgres can do vector search, document based (json) etc
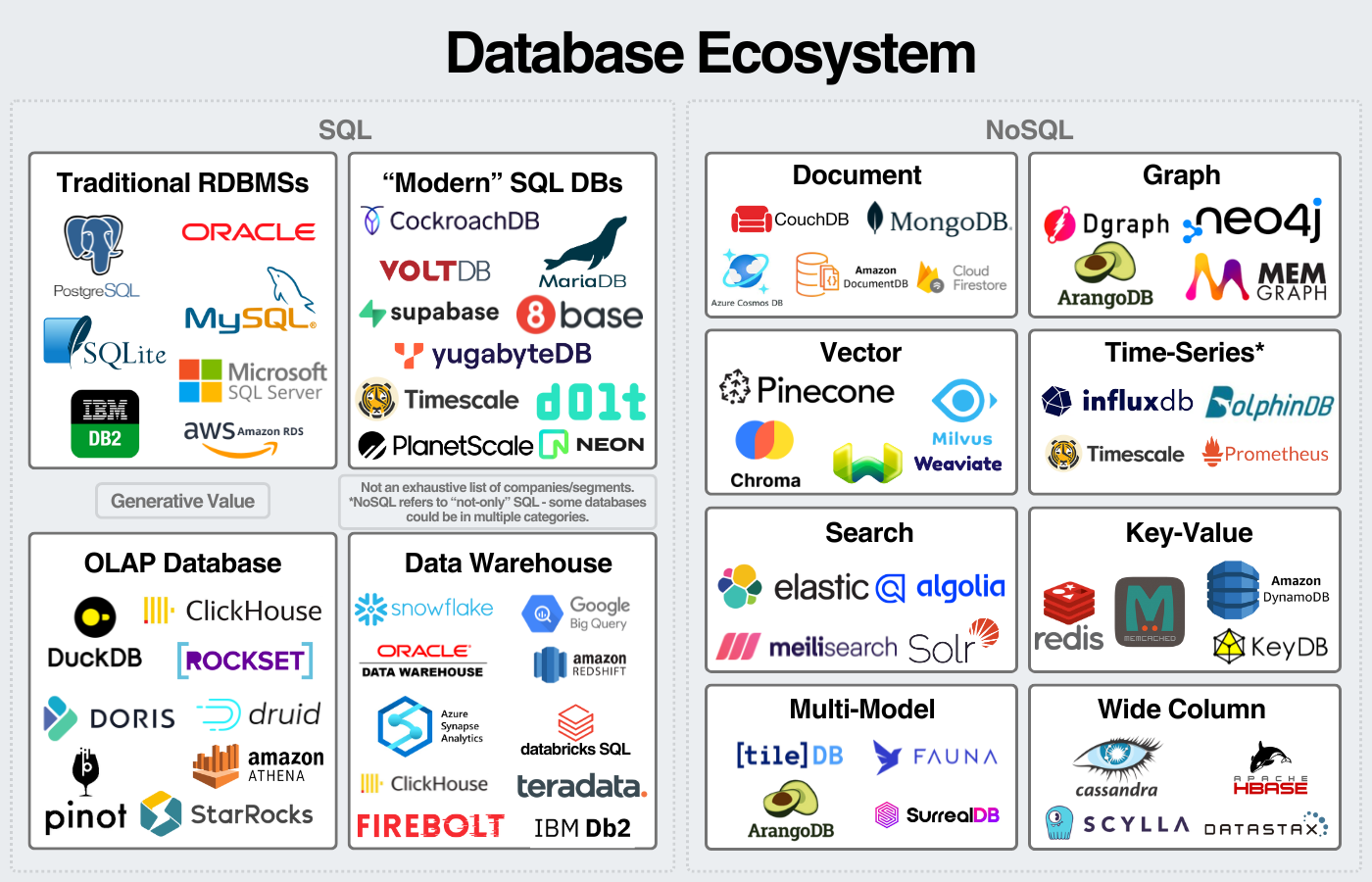
Ecosystem
Check the ranking of all databases at https://db-engines.com/en/ranking
Trends: https://db-engines.com/en/ranking_trend
Multitude of players:
source: https://www.generativevalue.com/p/a-primer-on-databases
Also see this interactive map that lists all players in 2023.
Open source vs proprietary Databases
Open source Databases
Advantages
✅ Free to use
✅ Transparent (view + audit code)
✅ Customizable
✅ Strong community support
✅ No vendor lock-in
Disadvantages
❌ May need more setup & tuning
❌ Support = community or paid 3rd party
❌ Fewer enterprise features (sometimes)
Proprietary Databases
Advantages
✅ Enterprise-grade support
✅ Robust tooling & integrations
✅ Optimized performance at scale
✅ Security/compliance features
Disadvantages
❌ Expensive licensing
❌ Closed codebase
❌ Vendor lock-in risk
❌ Limited customization
Database modelisation
Database modelisation
A database is a representation of a complex reality (ex: a company, an aircraft fleet, a maintenance service).
Modeling makes it possible to:
- Understand the real system
- Identify important data
- Define the links between them
👉 Before creating data tables, the problem must be analyzed and structured.
Method MERISE
Disclaimer
MERISE is a modelisation framework that extends beyond databases to processes and project management
MERISE is rarely used today and if so only in France.
There are many more up to date modelisation methods
Nonetheless the concepts are similar
and this is part of the final exam.
also chatGPT knows everything about MERISE
Modern alternatives
| Name | Main Concept | Advantages |
|---|---|---|
| UML (Unified Modeling Language) | Object-oriented diagrams for data + behavior | Matches modern software design, flexible, widely adopted |
| Anchor Modeling | Agile data modeling with anchors, attributes, ties | Handles evolving schemas, temporal data, automation-ready |
| Data Vault | Hubs, links, satellites for enterprise data warehouses | Scalable, auditable, integrates diverse sources |
| Evolutionary Database Design | Iterative schema changes, migrations, CI/CD | Fits Agile workflows, supports continuous delivery |
| Modern Tools (PowerDesigner, ER/Studio, dbdiagram.io…) | Collaborative modeling platforms | Automation, documentation, real-time teamwork |
Software development
Merise (like Waterfall):
- Sequential, with strict phases (conceptual → logical → physical).
- Heavy upfront design, less flexible once the system evolves.
- Works best in stable environments with well-known requirements.
Modern alternatives: UML, Anchor Modeling, Evolutionary DB Design, Data Vault, etc.
- Iterative and incremental, adapting to change as requirements evolve.
- Emphasize continuous feedback, small steps, and flexibility.
Better suited for today’s fast-changing, data-driven projects.
(a bit more Agile’ish):
Merise is to Waterfall what modern modeling techniques are to Agile — the first focuses on heavy planning and rigid steps, while the second focuses on adaptability and iterative improvement.
Merise
Merise : (Méthode d’Étude et de Réalisation Informatique par les Sous-Ensembles ou pour les Systèmes d’Entreprises).
aka : Méthode Éprouvée pour Retarder Indéfiniment la Sortie des Études (source wikipedia)
Overview
The overall approach to building an Information System (IS):
- Preliminary study: understand needs, derive scope, assess costs and timelines => 3 pillars of project management : functional specs
- Detailed study: describe functions, flows, data, technical specs
- Implementation and operation: data structures, integration, testing, and deployment
Levels of concern
Three levels of concern
- Functional / Business: Understand business rules
- Organizational: Impact on the company
- Technical: Tools and technologies used
Each stakeholder has a different perspective: (examples: sales, marketing, billing)
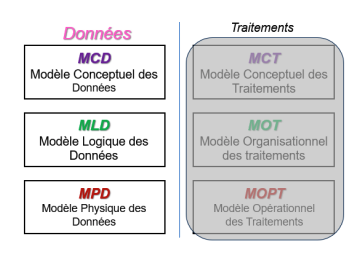
6 models
Merise aims to provide representations suited to each level with:
2 families of models
- Data
- Processing
3 levels of Information System (IS) description
- Conceptual: Management concerns ⇒ define Why?
- Logical / Organizational: Organizational concerns ⇒ define Who and where?
- Physical / Operational: Technical concerns ⇒ define How, with which tools?
6 models
Conceptual Data Model (CDM)
A graphical and structured representation of an IS’s information.
Based on two notions: entities and associations, also called an Entity/Association diagram.
Steps to build it:
- Define business rules
- Build the data dictionary
- Identify functional dependencies
- Create the CDM: entities → associations → cardinalities
The CDM provides an interactive graphical representation that helps you understand the interrelations of different elements using coded diagrams.
At the start of database design, the CDM then leads to the PDM and LDM
- Each rectangle represents an object = Entities
- Properties (the list of data associated with the entity)
- Associations: descriptions of how entities are linked (ovals and their connecting lines)
- The numbers above the “lines” are called cardinalities
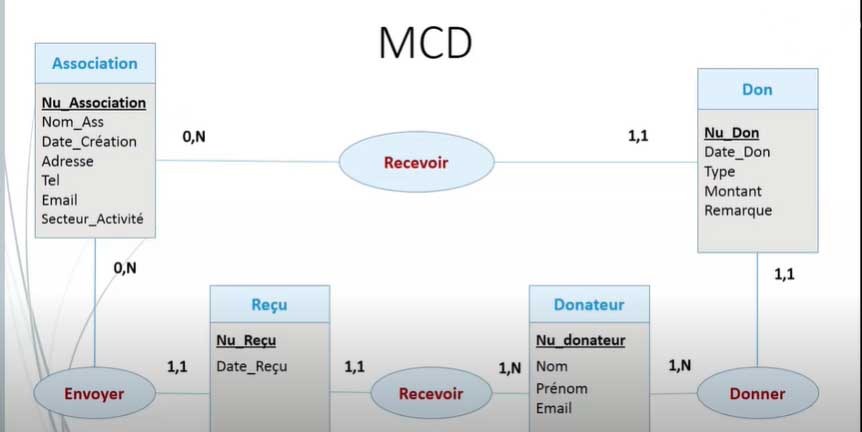
from : MCD
Exercice CDM
Data Dictionary
The Data Dictionary is a document that lists and describes all the data of an information system. Serves as a common reference between analysts, developers, and users.
For each data item, specify:
- Mnemonic code: short name (ex. title_b)
- Designation: clear description (ex. book title)
-
Type:
- A → Alphabetic (letters)
- N → Numeric (integers/reals)
- AN → Alphanumeric (letters + numbers)
- Date → format YYYY-MM-DD
- Boolean → True/False
- Size: number of characters or digits (ex. a date = 10 characters)
Data Dictionary Example
| Code | Designation | Type | Size | Constraints / Rules |
|---|---|---|---|---|
| id_client | Client ID | INT | - | Primary key, unique, not null |
| nom | Client name | VARCHAR | 50 | Mandatory |
| date_naissance | Birth date | DATE | - | >= 1900-01-01 and <= current date |
Example — Data Dictionary (CLIENT)
📌 In modern DBMS, SQL types like CHAR/VARCHAR are used instead of A, or INT/DECIMAL instead of N.
MCD – Basic Concepts
-
Entity Object (concrete or abstract) through which the organization (company, administration, etc.) recognizes an independent existence. (ex: supplier, client, order, airplane, etc.)
-
Property Characteristics of the entity (ex: name, price, date)
-
Identifier Special property that distinguishes each occurrence (ex: supplier No. 234, employee X456, etc.)
Example: Entity Book
| Entity: Book | name of the entity |
|---|---|
| Book_id | Identifier |
| Title | Property |
| Genre | Property |
| Author_id (Property) | Property |
MCD – Basic Concepts (continued)
-
Relation Links between two (or more) entities (ex: Client places Order)
-
Cardinality Number of times (minimum, maximum) an entity is involved in a relation.
- 0,1: optional, at most once
- 1,1: mandatory and unique participation
- 0,N: optional participation with multiple possible occurrences
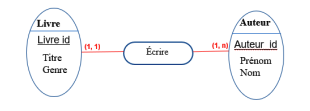
Constraints and business rules
- Syntactic constraints: Define the form of the data (Date: dd/mm/YY)
-
Value constraints:
- Static: birth year ≥ 1958 and ≤ 2007
- Dynamic: engine operating hours can never be decremented
-
Business rules: Define how the system works:
- a vehicle registration applies to one person only
- no order > €60,000 without automatic invoicing
MCD – Constraints (functional dependencies)
Functional dependencies (FD)
-
Between properties:
- Value of one depends on another
- Example: INSEE No. ⇒ birth year
- Postal code ⇒ department of the city
-
Between entities:
- Existence of one entity implies the existence of another (cardinality 1–1)
- Example: one person owns one vehicle, one vehicle is owned by one person
👉 Use: check consistency, avoid redundancy, help normalization
MCD – Construction (techniques)
-
Uniqueness of data Each piece of data appears only once. If duplicate → they represent different realities.
-
Simplify relations Replace an n-dimension relation with several smaller relations.
-
Eliminate calculated data Example: birth date + today’s date ⇒ age
MCD – Construction (graphical)
Graphical representation of the CDM Entity – Relation
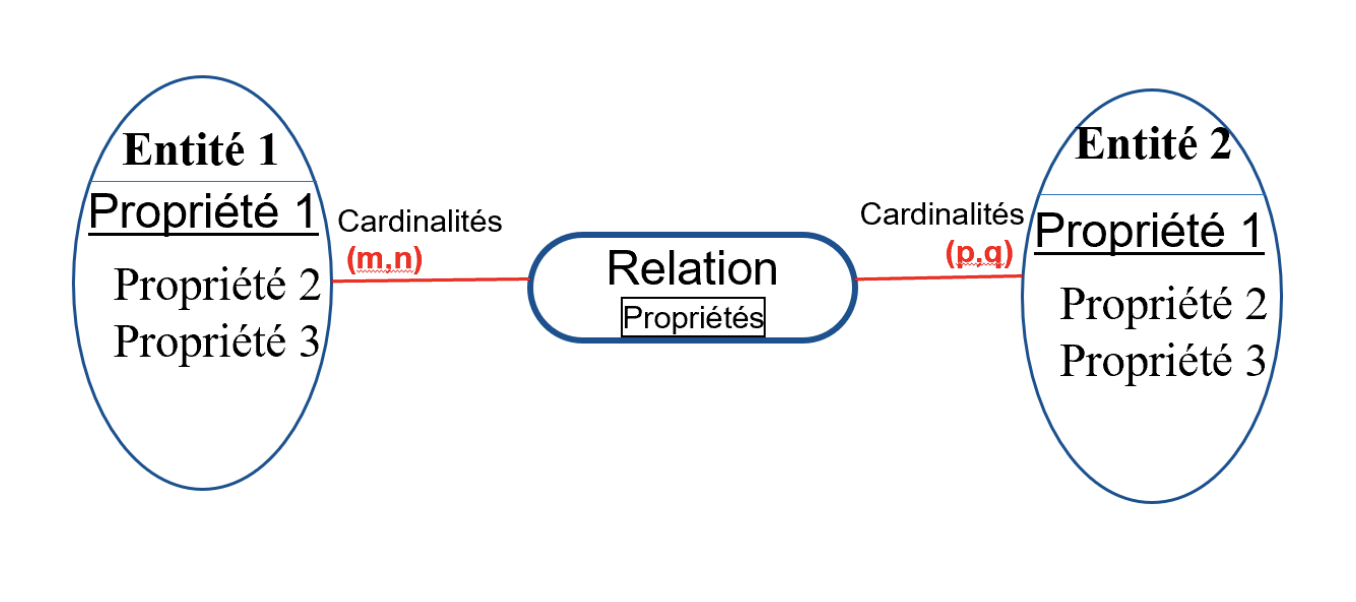
MCD – Construction (graphical)
Types of relations
- Unary relation
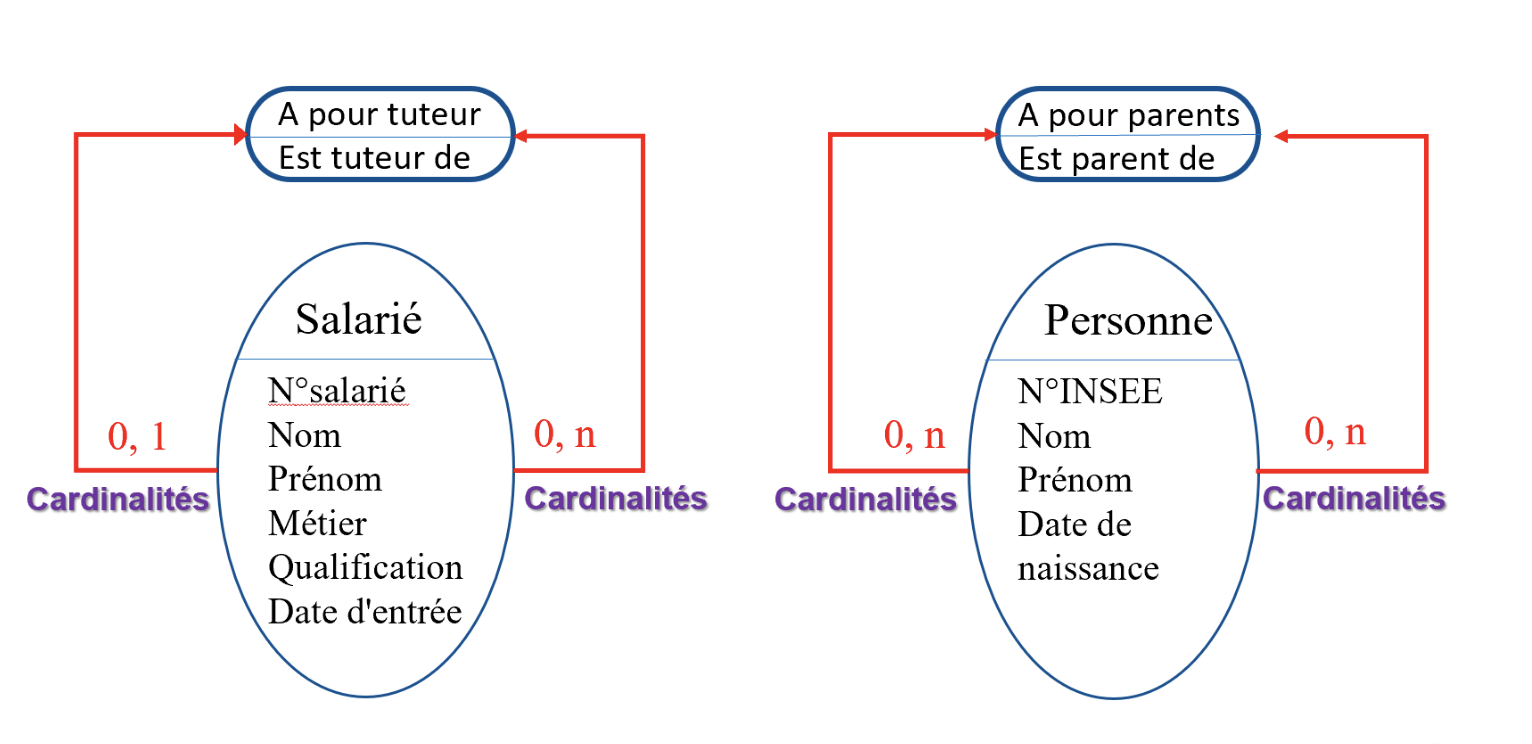
MCD – Construction (graphical)
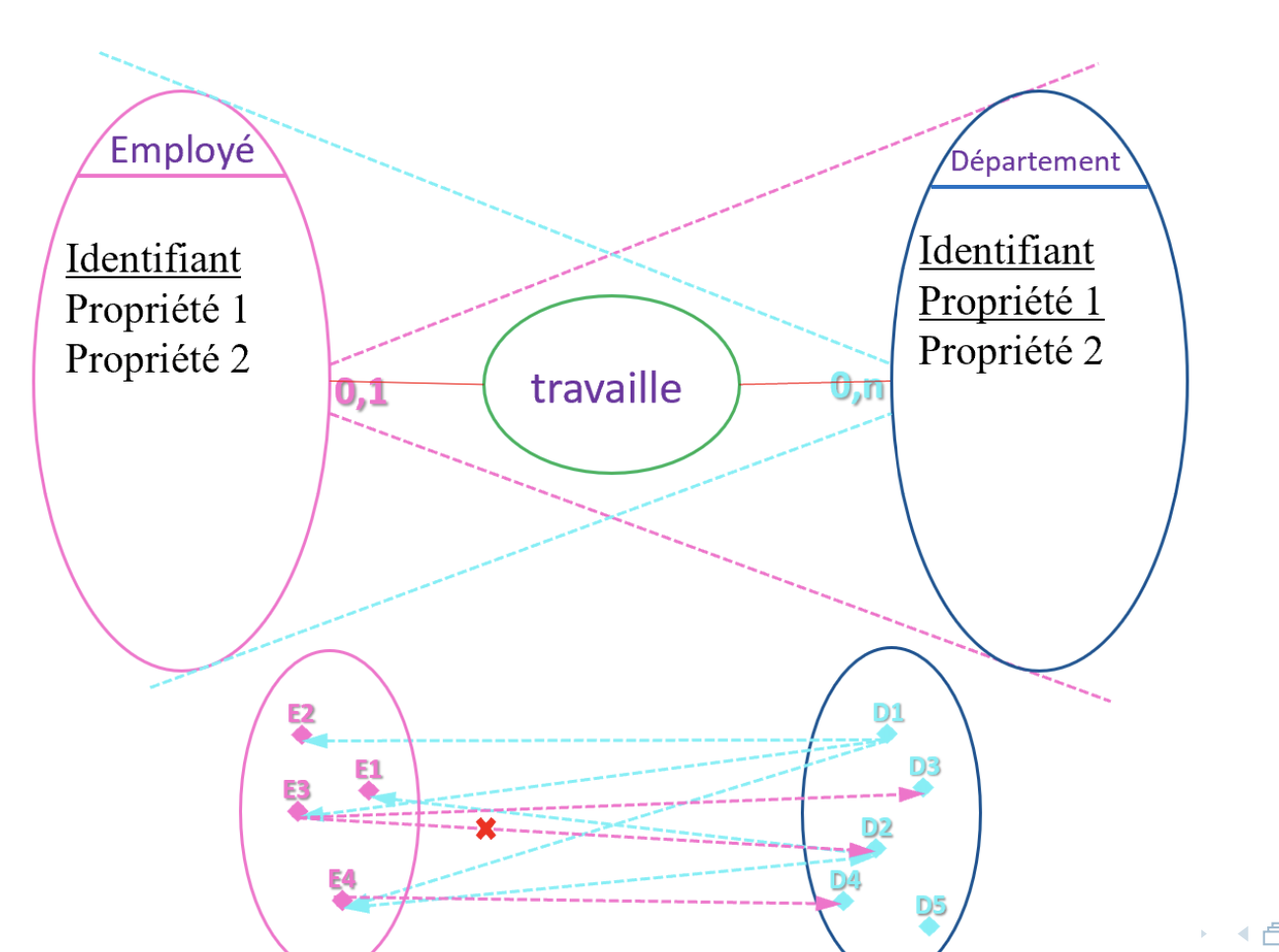
Types of relations
- Binary relation
MCD – Construction (graphical)
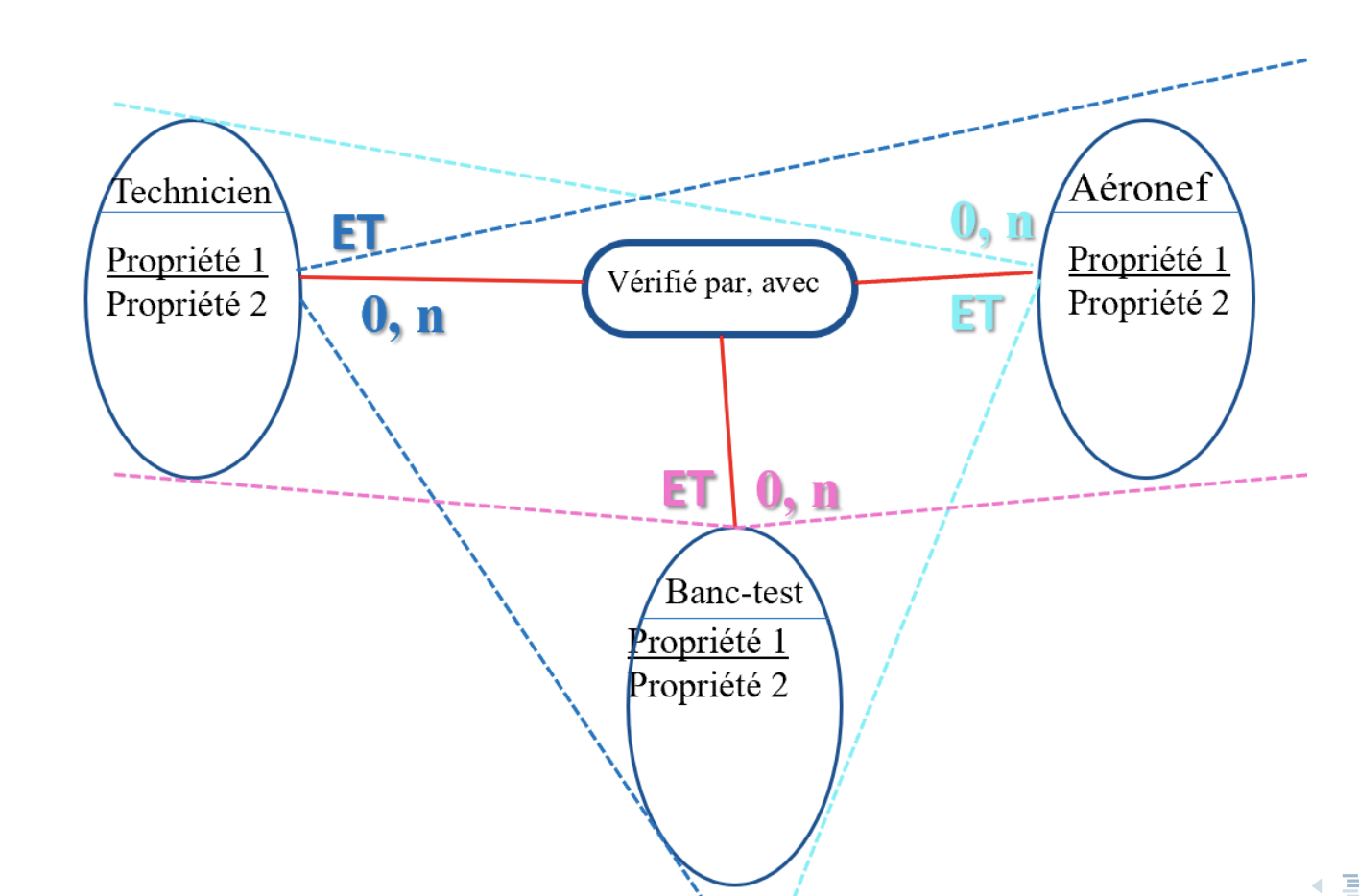
Types of relations
- Ternary relation
MLD
MLD
Purpose: to translate the Conceptual Data Model (CDM/MCD) into a logical form adapted to a database (relational, hierarchical, network, depending on the DBMS).
What it contains:
- Transformation of entities into tables.
- Transformation of associations into tables or foreign keys, depending on the cardinalities.
- Definition of primary keys and foreign keys.
- Typing and normalization of attributes (e.g., VARCHAR(50), DATE).
Characteristics:
- Depends on the chosen model (most often relational).
- More technical, closer to the future implementation in the DBMS.
see this article
from CDM to LDM
The CDM (MCD) describes what to store and the relationships, at a conceptual level.
The LDM (MLD) describes how to organize this data for storage in a DBMS (mainly relational).
MLD – Concepts
Concepts at the MLD level:
-
Table (or relation)
Structured set of data organized in a table
- Column: data of the same type/format (ex: date dd/mm/yy, capacity L)
- Row: set of properties linked together, representing a concrete entity
-
Record Set of table properties associated with a key (row of a table, with key)
MLD – Concepts (continued)
-
Key Property (or group of properties) uniquely identifying one entity among others of the same type. (ex: one employee among all employees)
-
View Grouping of properties (columns) from one or more tables corresponding to a specialized perspective of reality.
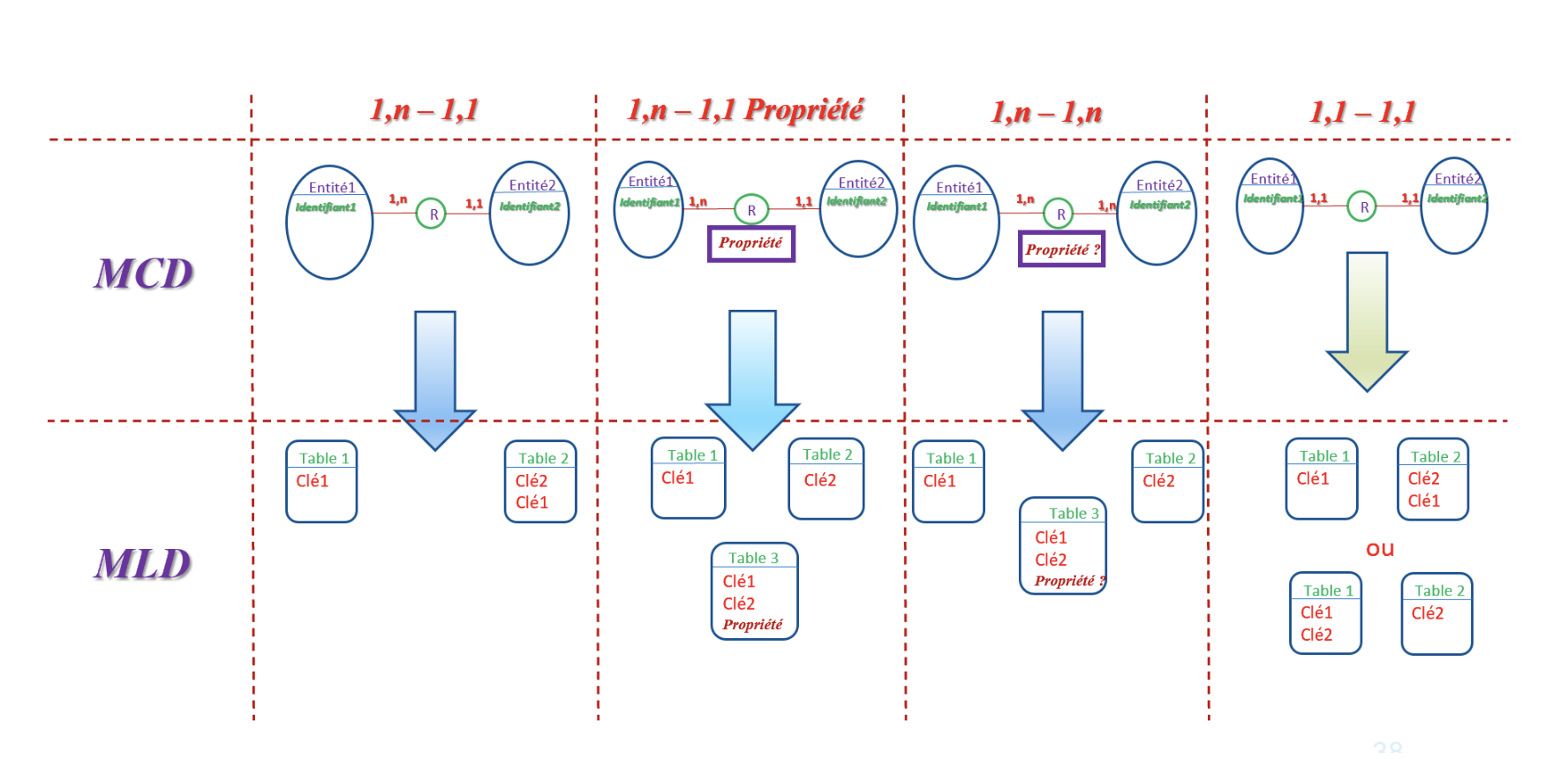
Transition MCD → MLD: Rules
Transformation rules:
-
Each entity becomes a table
- Entity attributes become table columns
- Identifier becomes the primary key (PK)
-
Each relation becomes either:
- A column (foreign key, FK) if relation is (1,n – 1,1), (1,1 – 1,1), (1,1 – 0,1)
- A new table (associative) if relation is (1,n – 1,m)
Cardinality in SQL
{0,1} vs {1,1} : optional vs mandatory <=> add constraints with NULL ok or NOT NULL
CREATE TABLE Person (
person_id INT PRIMARY KEY,
name VARCHAR(50)
);
CREATE TABLE Passport (
passport_id INT PRIMARY KEY,
person_id INT UNIQUE, -- one-to-one
FOREIGN KEY (person_id) REFERENCES Person(person_id),
-- If mandatory:
person_id INT UNIQUE NOT NULL,
-- If optional:
person_id INT UNIQUE NULL
);
Transition MCD → MLD: Rules (graphical representation)
-
Graphical representation of tables
-
⚠️ There are no direct links between tables. Dashed lines may help understanding, but it’s the pairs “primary key – foreign key” that represent the relation from the CDM.
-
Example: key of T1 is property 4 of T2
- Mandatory if cardinality (1,1)
- Optional if cardinality (0,1)
Transition MCD → MLD: Rules
More transformation rules from CDM to LDM.
MLD – Table Description
Tables include:
- Property names (fields) (ex: Serial number, Manufacture date)
- Indication of keys
- Field description (ex: Numeric (15), Date)
- Whether fields are mandatory or optional
Schemas (text representation):
PLANE (
id_plane : integer [primary key, required],
model : text(50) [required],
flight_hours : integer [optional]
)
Tuples:
- (id_plane=1, model=”A320”, flight_hours=24500)
- (id_plane=2, model=”A350”, flight_hours=17800)
Exercise — Car Rental
After analysis, the following rules were identified:
- A person may own 0 to n cars.
- Each car belongs to one person only.
- A person may rent a car for a given time period.
- A person cannot rent several cars simultaneously during the same period.
- A person may rent multiple cars, but in different time periods.
- A car may be rented by only one person at a time, for a given period.
- A car may remain unrented for one or more time periods.
- A rental always links one car and one person.
- A car may be rented by different people, but in distinct time periods.
- The owner of one or more cars may also rent another person’s car.
create the MCD and MLD for this database.
intermission
Normalization
Normalization
To normalize a table means to apply one or more decompositions to eliminate potential internal redundancies.
Based on the notion of keys and functional dependencies.
There are 6 common normal forms (1NF, 2NF, 3NF, 4NF, 5NF, and Boyce-Codd Normal Form).
(in fact there are many more normalization rules see wikipedia normalization)
Why normalization ?
- Normalized database : one piece of data appears only once.
- denormalized : one piece of data appears multiple times. this speeds up queries by reducing the number of tables involved in the query.
But then you have to handle duplicates of the data: inserts, updates, deletes etc
- Normalized : consistency, and less errors. but slower queries
- denormalized : faster queries, but more complex to maintain.
example denormalized
Orders(order_id, order_date, customer_id, customer_name, customer_address) Invoices(invoice_id, order_id, customer_id, customer_name, customer_address, amount)
Both Orders and Invoices store customer_name and customer_address.
The same customer info is duplicated in two tables.
makes sense if you quickly want to see the customer name and address in the orders and invoices in a dashboard.
Normalization
More formally, a database is normalized if:
all column values depend only on the table primary key,
aka
each piece of information lives in just one place
Normalization – 1st Normal Form
Definition: A table is in 1NF if every attribute contains an atomic value. Lists, arrays, or complex structures cannot be attribute values.
attribute = value
actors : ['actor1', 'actor2', 'actor3'] => not in 1NF
actor : 'actor1' => ok
Normalization – 1st Normal Form
Solution 1: Create multiple attributes (horizontal storage).
- Everything remains in the same relation (no join needed)
- Issues: null values, limited storage capacity
actor_01 : 'actor1'
actor_02 : 'actor2'
actor_03 : 'actor3'
This does not scale and is a terrible solution!
- null values when less than 3 actors
- what if we have 4 actors ?
etc
Normalization – 1st Normal Form
Solution 2: Create a new table for the multivalued attribute (vertical storage, cleaner).
- No null values, no storage limits
- But requires joins, heavier with self-joins
Movie table : id, title, duration
Actor table : id, name, movie_id
one movie has many actors
Normalization – 1st Normal Form (exercise)
Table schema:
PERSON (idPerson, name, firstName, address, cars)
- Is it in 1NF?
- Justify
- If not, propose a solution
Normalization – 1st Normal Form (solution)
Decomposition into tables:
PERSON (idPerson, name, firstName, streetNo, streetName, postalCode, city) CAR (idCar, model, brand, owner)
1NF
Note : The 1NF is not compatible with arrays or objects data types. But they exist and are 100% legit.
=> use common sense when applying normal forms
sometimes it’s better to list the values for a given record than to create a new table.
Normalization – 2nd Normal Form
Definition: A relation is in 2NF if and only if:
- It is already in 1NF
- Every
non-key attributedepends on the entire key, not just part of it
👉 Removes redundancy
👉 Only concerns tables with a composite primary key (multiple attributes)
What is a key ?
A key in a database is a column (or a set of columns) that uniquely identifies a row in a table.
Simple (single) key: one column does the job.
Example: student_id in a Students table.
Composite key: two or more columns together make it unique.
Example: (order_id, product_id) in an OrderDetails table.
👉 If you know the key, you can point to exactly one row, no confusion.
Normalization – 2nd Normal Form (exercise)
- A table has a composite key
- an attribute is dependent on only one element of the key : the dependency is partial
This creates redundancy : the same value appears multiple times in the table.
2NF: all non-key attributes depend on the entire key
Attention: 1NF + non composite key => 2NF
Example
ASSIGNMENT (idPerson, idInstitution, name, firstName, institutionName)
- Is it in 2NF?
- Justify
-
If not, propose a solution
ASSIGNMENT (idPerson, idInstitution, name, firstName, institutionName)
Is it in 2NF?
-
if the key is (idPerson, idInstitution) then institutionName only depends on idInstitution, not idPerson so the dependency is partial
-
if the key is just idPerson, then no problem since there is no partial dependency
2 NF on wikipedia
https://en.wikipedia.org/wiki/Second_normal_form
_A relation (or a table, in SQL) is in 2NF if it is in first normal form (1NF) and contains no partial dependencies.
A partial dependency occurs when a non-prime attribute (that is, one not part of any candidate key) is functionally dependent on only a proper subset of the attributes making up a candidate key._
Normalization – 2nd Normal Form (solution)
many to many relations
PERSON (idPerson, name, firstName)
INSTITUTION (idInstitution, institutionName, brand)
ASSIGNMENT (idPerson, idInstitution)
Or with idInstitution as the foreign key : a person blongs to only one institution (one to many)
PERSON (idPerson, name, firstName, idInstitution)
INSTITUTION (idInstitution, institutionName, brand)
Normalization – 3rd Normal Form
Definition: A relation is in 3NF if and only if:
- It is already in 2NF
- There is no transitive dependency (a non-key attribute depends on another non-key attribute)
Formally: For every dependency A → X, either A is a superkey or X is part of a key.
3NF Example: Table Orders
Orders(
order_id INT PRIMARY KEY,
customer_id INT,
customer_name VARCHAR(50),
customer_city VARCHAR(50),
city_zipcode VARCHAR(10)
)
where order_id is the key (not order_id + customer_id). the key is not composite. so it is in 2NF
Why it’s not in 3NF
- It’s in 1NF (atomic values).
- It’s in 2NF (order_id is the primary key, no partial dependency).
-
❌ But not in 3NF:
city_zipcodedepends oncustomer_city, not directly on the primary key (order_id).-
This is a transitive dependency:
order_id → customer_city → city_zipcode
How to Normalize (3NF)
Split into 3 separate tables:
Customers(
customer_id INT PRIMARY KEY,
customer_name VARCHAR(50),
city_id INT,
FOREIGN KEY (city_id) REFERENCES Cities(city_id)
)
Cities(
city_id INT PRIMARY KEY,
city_name VARCHAR(50),
city_zipcode VARCHAR(10)
)
Orders(
order_id INT PRIMARY KEY,
customer_id INT,
FOREIGN KEY (customer_id) REFERENCES Customers(customer_id)
)
👉 Now:
Orders→ linked to CustomersCustomers→ linked to Citiescity_zipcodedepends only oncity_id(the key of Cities), not on a non-key attribute.
So this design is in 3NF.
Normalization – 3rd Normal Form (exercise)
Example table schema:
Tracks(track_id, title, album_id, album_name, artist_id, artist_name)
where track_id is the key
- Is it in 3NF?
- Justify
- If not, propose a solution
Normalization – 3rd Normal Form (solution)
Decompose the relation into 2 tables:
CAR (regNo, type, color)
MODEL (type, brand, power)
Normalization – Exercises
1st Normal Form: For each relation, state if it is in 1NF.
- DELIVERY (supplierNo, cityList)
- CLIENT (clientNo, name, firstNames)
- CLIENT (clientNo, name, firstName1, firstName2)
- CLIENT (clientNo, name, firstName, address)
Normalization – Exercises
2nd Normal Form: For each relation, state if it is in 2NF.
- LOAN (isbnNo, memberNo, date, memberName, memberCity, bookTitle)
- LOAN (isbnNo, memberNo, date)
- LOAN (copyNo, date, memberNo)
Normalization – Exercises
3rd Normal Form: For each relation, state if it is in 3NF.
- SUPPLIER (supplierNo, city, country) — consider whether city names are unique or not
- STAFF (agentNo, name, researchDept, building)
- STAFF (agentNo, name, researchDept, agentStatus)
- FLIGHT (flightNo, airline, time, destination, planeModel, passengerCount)
Key Takeaways
- DBMS: tools to store, organize, and query data
- Modeling: represent reality before creating tables
-
Merise method:
- CDM = entities, relations, cardinalities
- LDM = tables, primary/foreign keys
- Normalization = remove redundancies and inconsistencies (1NF, 2NF, 3NF)
🎯 Goal: go from business problem to a reliable relational database