RAG : Retrieval Augmented Generation
context
- chatbot d’entreprise : support clients,
- moteur de recherche interne
donc comment utiliser l’IA pour converser avec une base documentaire en évitant les hallucinations et autres bourdes.
Differentes approches
- On met toute la base documentaire dans le prompt! (1M de tokens = 1,6 fois Guerre et Paix)
- Agents : base de données + MCP + LLM agentic (memoire, outils, evaluations, conducteur vs executant)
- RAG : Retrieval Augmented Generation
Comment résoudre:
- cut off date des LLMs
- contexte window limité
- hallucinations
- les erreurs
Idée:
Ajouter la bonne info dans le prompt
Principe:
- trouver l’extrait de texte avec la bonne info : Retrieval
- l’ajouter dans le prompt : Generation
<Question>
prends en compte le texte ci-dessous pour répondre
<Information, retrieved>
Version plus élaborée du prompt
Agissant en tant que
{insérer un rôle spécifique : enseignant, analyste, geek, auteur, …}
Utilise les informations suivantes :
{insérer les chunks de texte résultants}
Pour répondre à cette question :
{insérer la question initiale}
Donc super simple.
La difficulté n’est pas dans le prompt utilisateur mais dans la partie retrieval
Comment identifier les documents relatifs à la question / query ?
- combien de documents prendre en compte
- est-ce que l’info est complete
- y a t il des contradictions entre divers documents
- comment gerer les versions des documents
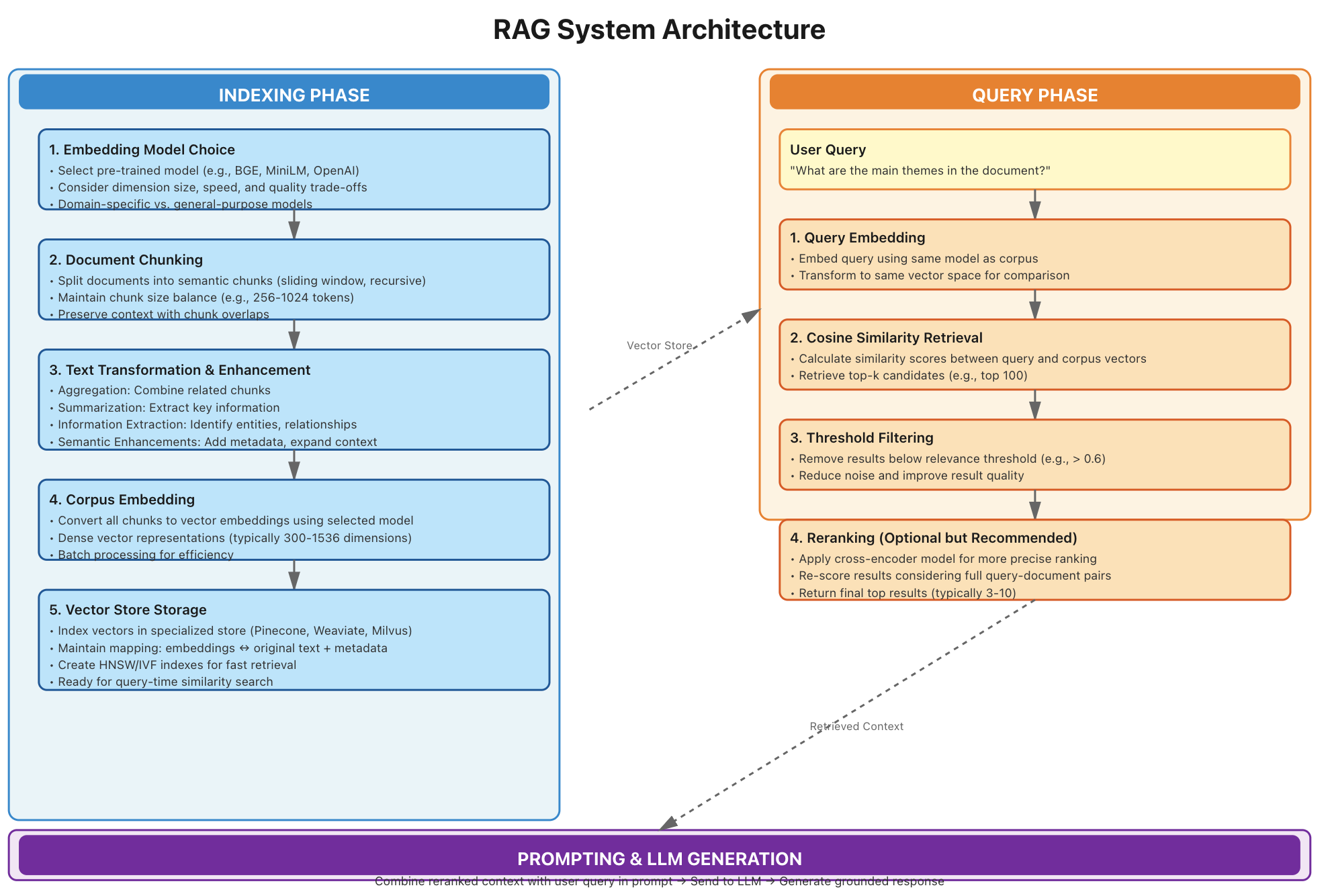
L’approche RAG
On vectorise un corpus de document
- chunk : scinder les documents en extraits qui font sens : phrases, paragraphe(s), sections, etc
- embedding : vectoriser les documents à l’aide d’un modèle approprié
- storage : stocker le tout dans une base de donnée vectorielle comme weaviate, pinecone, …
L’utilisateur pose sa question : la query
- vectoriser la query avec le meme modele
- trouver les N documents dont les vecteurs sont proches du vecteur de la question
distance entre deux textes vectorisés : cosine similarity
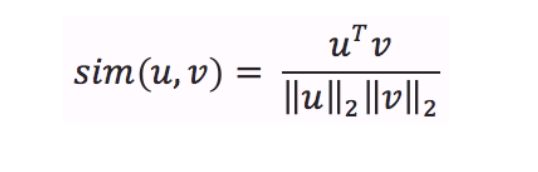
A ce stade on a 2 questions non résolues
- comme chunker le texte original ?
- combien de documents prendre en compte ?
Chunk
On peut jouer sur
- la taille des extraits
- overlaper entre les extraits
[ p1 + p2 + p3, p2 + p3 + p4, p3 + p4 + p5, ... ] - transformer les extraits pour mettre en avant l’information importante
- ajouter des meta données : titre section ou chapitre, categorie, version etc
Vectorisation
Il y a de nombreux modeles de vectorisation disponibles
voici la strategie de choix selon Mistral
Les points 1, 2, 3 et 7 me semblent importants
Stratégie pour choisir un modèle d’embeddings en RAG
1. Langues
- Anglais : Modèles optimisés (
text-embedding-3-large,bge-large-en-v1.5). - Français : Modèles multilingues (
multilingual-e5-large) ou spécifiques (camembert-base).
2. Taille des chunks
- Courts (phrases) : Modèles légers (
all-MiniLM-L6-v2). - Longs (paragraphes) : Modèles avec grande fenêtre contextuelle (
text-embedding-ada-002,bge-large-en-v1.5). - Chevauchement : 10-20% pour éviter la perte de contexte.
3. Open-source vs Propriétaire
- Open-source : Contrôle total, personnalisation possible (
bge-large-en-v1.5,e5-mistral-7b-instruct). - Propriétaire : Performances optimisées, déploiement simplifié (
text-embedding-3-large).
4. Installation locale vs API
- Locale : Idéal pour confidentialité ou hors ligne (
sentence-transformers,FlagEmbedding). - API : Pratique pour un déploiement rapide et scalable (OpenAI, Cohere).
5. Performances
- Précision : Vérifier les benchmarks (MTEB) pour la langue/le domaine.
- Vitesse : Modèles légers pour le temps réel (
all-MiniLM-L6-v2). - Modèles récents :
text-embedding-3-large,bge-large-en-v1.5,multilingual-e5-large.
6. Adaptation au domaine
- Fine-tuning sur des données spécifiques (ex :
camembert-basepour le juridique en français).
7. Outils d’évaluation
À retenir :
- choisir un modele d’embedding MTEB
- Pour l’anglais,
text-embedding-3-largeoubge-large-en-v1.5. - Pour le français,
multilingual-e5-largeou un modèle fine-tuné. - Pour des documents longs, modèles avec une grande fenêtre contextuelle.
Merci Mistral :)
Sur la méthode de chunking, j’ai du mal à croire qu’un split basé juste sur la longueur de l’extrait donne de bons resultats, meme avec chevauchement / fenetre coulissante.
Garbage in => Garbage out
Voir XKCD
- C’est ton système d’apprentissage automatique ?
- Oui ! Tu verses les données dans ce gros tas d’algèbre linéaire, puis tu récupères les réponses de l’autre côté.
- Et si les réponses sont fausses ?
- Il suffit de remuer le tas jusqu’à ce qu’elles aient l’air justes.
Reste la question
Combien de documents inclure dans le prompt ?
- atteindre la limite de la fenetre de contexte du LLM
- taille des chunks
- seuil de score de similarité
t > 0.75(totallement arbitraire) - evaluation en bout de chaine en fonction du nombre de doc
=> 100% empiririque
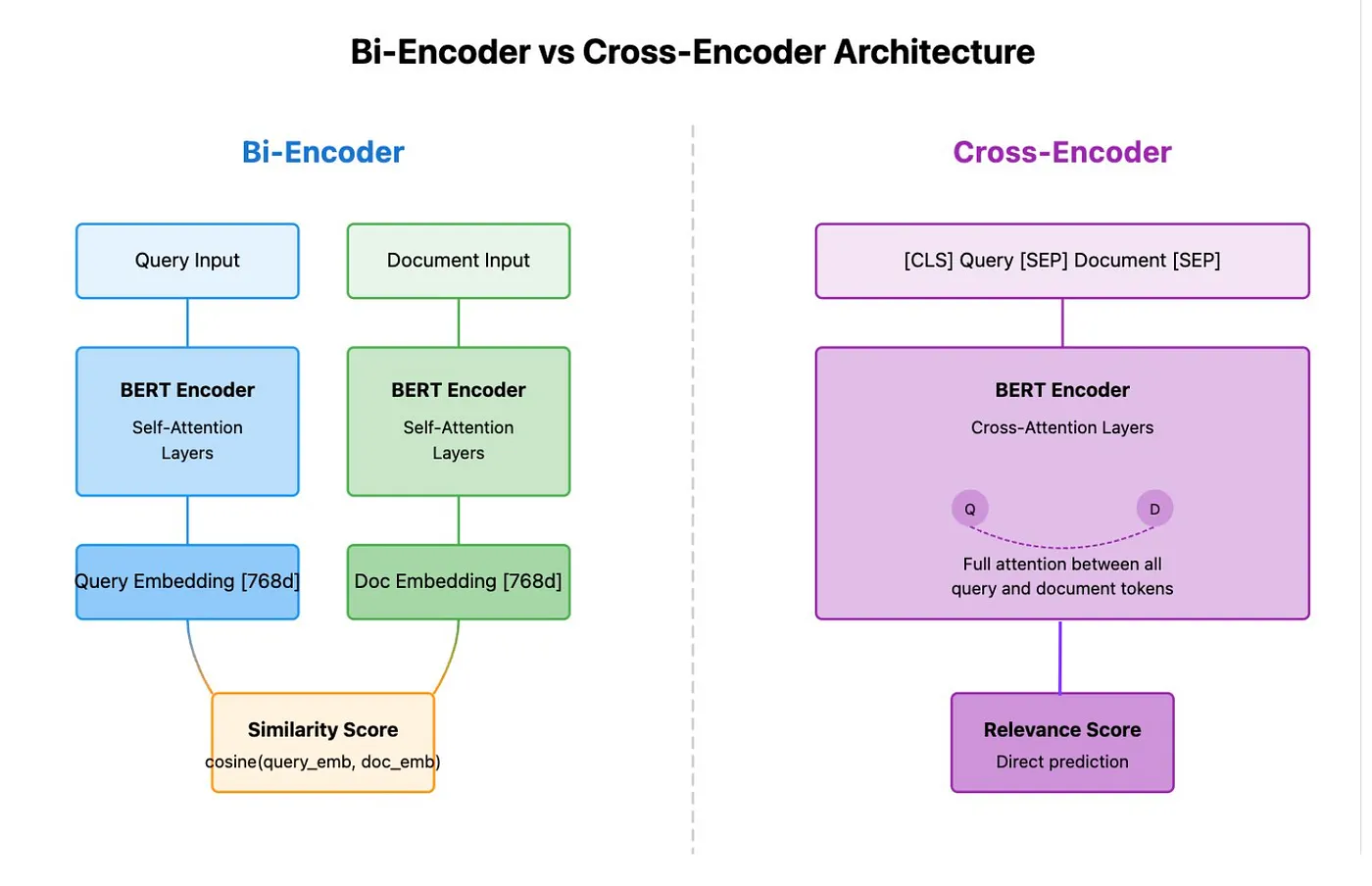
Reranking
Le systeme retourne N documents similaires en rapport à la question de depart à partir d’un modele de vectorisation censé conserver la semantique des documents.
Ces modeles sont generiques et utiles pour vectoriser de grande quantité de docs
Embedding Global
- Génère un vecteur fixe (ex. 768 dim.) capturant le sens global du texte.
- Encodage unique et rapide : chaque texte est transformé une fois, stocké, puis comparé via cosine similarity ou dot product.
- Échelle corpus : indispensable pour créer un espace sémantique commun à toutes les phrases/documents.
Reranking / Cross-Encoder
- Entrée jointe : query + document passés ensemble dans un même Transformer (BERT, RoBERTa…).
- Sortie : score de pertinence direct (régression ou classification binaire).
- Fine-tuning avec MSE ou cross-entropy sur des paires étiquetées.
- Précision supérieure : capte les interactions fines (ordre des mots, négation, co-références).
- Coût CPU/GPU élevé : impossible d’encoder tout le corpus ; utilisé seulement pour reranker les top-k candidats fournis par l’embedding.
recap
Evaluation en bout de chaine avec RAGAS
- multiple metriques
- multiples datasets pour l’evaluation
Vector Store
Comment matcher 2 vecteurs le plus vite possible
- query
- corpus (milliers de documents)
Calculer le cosine sim de la query vs tous les documents => prends trop de temps
Weaviate
- collection
- objects
Plusieurs methode d’insertion
- seulement texte + modele d’embedding (et cle API)
- bring you own embedding : BYOE
Possible de stocker des meta données => categories, numerique etc et donc de filtrer sur ces attributs
Plusieurs methodes de recherche
- vector search : recherche par similarité vectorielle
- keyword search (BM25)
- hybrid search
voir https://academy.weaviate.io/courses/wa050-py/m2/p3
- creer un compte
- creer un cluster
- trouver API_KEY, URL (REST Endpoint)
Ollama
uv tool install llm
Inference rapide
- groq
- openrouteur