Le dataset DPE tertiaire de l'ADEME
Le jeu de données DPE tertiaire de l'ADEME est un dataset de terrain tel que l'on peut en rencontrer dans un contexte professionnel, loin des datasets d'apprentissage trop simples tels que le Titanic, Iris ou le Boston Housing. Le DPE tertiaire est complexe, parfois redondant, souvent confus mais relativement volumineux avec plus de 270,000 échantillons. Dans ce chapitre, vous allez vous familiariser avec ce dataset en en faisant une exploration rapide.
👉
git clone https://github.com/SkatAI/MLOps-DPE
👈
Connaîssez-vous L’ADEME ?
L’ADEME est l’Agence de l’environnement et de la maîtrise de l’énergie, rebaptisée récemment Agence de la transition écologique comme indiqué sur le site ademe.fr. Dans le cadre de sa mission de protection de l’environnement et de maîtrise de l’énergie, l’ADEME met à disposition de nombreux jeux de données sur leur portail dédié : data.ademe.fr. Un véritable trésor pour le data scientist. Parmi ces jeux de données, nous allons nous intéresser à ceux ayant trait au bilan énergétique des bâtiments (DPE).
DPE est l’abréviation de Diagnostic de Performance Énergétique. Depuis 2013, un score de performance énergétique doit être associé à tout bâtiment ou logement du territoire français. Ce score s’exprime sous forme d’étiquette allant de A (meilleur) à G (mauvais).
L’ADEME définit le DPE de la façon suivante :
Le Diagnostic de Performance Énergétique (DPE) renseigne sur la performance énergétique et environnementale d’un logement ou d’un bâtiment, en évaluant sa consommation d’énergie et son impact en matière d’émissions de gaz à effet de serre … Le DPE contient des informations sur les caractéristiques du bâtiment ou du logement (surface, orientation, murs, fenêtres, matériaux, etc.) ainsi que sur ses équipements (de chauffage, de production d’eau chaude sanitaire, de ventilation, etc.)
Il existe 3 datasets DPE sur le site data de l’ADEME : logements neufs, logements existant et tertiaire.
C’est à ce dernier que nous allons nous intéresser, car il est un peu plus simple que les 2 autres, mais contient quand même plus de 270.000 échantillons.
Selon l’Insee, le secteur tertiaire recouvre :
un vaste champ d’activités qui s’étendent du commerce à l’administration, en passant par les transports, les activités financières et immobilières, les services aux entreprises et services aux particuliers, l’éducation, la santé et l’action sociale.
Le jeu de données DPE tertiaire couvre donc les entreprises, administrations, magasins, écoles, hôpitaux … mais pas les usines.
En quoi consiste les données DPE Tertiaire ?
Sur la page du DPE tertiaire, les icônes situées à droite donnent accès à de la documentation sur les données et sur l’API ainsi qu’à un fichier de 10.000 échantillons que l’on obtient en cliquant
sur l’icône .
.

C’est ce jeu de données réduit et static qui va nous servir de base de travail dans les premiers chapitres du projet. Dans un second temps, nous utiliserons l’API pour obtenir tous les autres enregistrements.
A vous :
Rendez-vous sur la page https://data.ademe.fr/datasets/dpe-v2-tertiaire-2, explorez les infos et téléchargez le fichier dpe-v2-tertiaire-2.csv.
Débroussailler le dataset
Le dataset comprend un mélange de valeurs de différents types. On trouve des variables
- catégorielles (
Secteur_activité,Type_énergie_n°1), - de date (
Date_visite_diagnostiqueur,Date_fin_validité_DPE), - numériques (
Conso_kWhep/m²/an,Surface_utile,Conso_é_primaire_énergie_n°1,Coordonnée_cartographique_X_(BAN)), - ou de texte semi-libre (
Nom__rue_(BAN),Date_fin_validité_DPE).
On distingue aussi les variables liées :
- à la localisation du bâtiment : Nom de rue, commune, code postal, étage et Coordonnée cartographique …
- aux types de sources d’énergie et à leurs usages : électricité, bois, chauffage, …
- aux volumes consommés ou émis :
Conso_é_finale_énergie_n°1,Conso_kWhep/m²/an,Emission_GES_kgCO2/m²/an - au diagnostics : type de DPE, date du diagnostic, Modèle_DPE, …
- et à divers informations: invariant fiscal, Nombre d’occupants
Un dataset riche, volumineux avec une variable cible bien identifiée
fait le bonheur du data scientist.
Quelques précisions sur les données
- BAN : les colonnes liées à la localisation sont souvent suivies des lettres BAN qui signifie Base Adresse Nationale, c’est la base de données officielle du gouvernement français.
- La catégorie ERP correspond à la classification officielle des établissements recevant du public. Le niveau de catégorie ERP (variant de 1 à 5) dépend du nombre de personnes reçues dans l’établissement.
- La surface SHON (surface hors œuvre nette) est une mesure de surface officiellement abandonnée depuis 2012, mais qui est toujours utilisé dans certains cas. Le calcul de la surface d’un bâtiment ou d’un logement est un domaine étonnamment compliqué avec des mesures SHON, SHOB, SUBL ou SHAB voir de la surface Carrez et surface de plancher. Que du Fun!
En explorant la page du DPE tertiaire, on trouve d’autres éléments d’informations sur ce dataset. Entre autres :
- le schéma des données
- Une note technique de 12 pages
- Une repo de notebooks sur gitlab
- un dictionnaire de données commun aux trois dataset DPE
Le site https://observatoire-dpe-audit.ademe.fr/statistiques/outil offre la possibilité de visualiser facilement les données DPE.
Par exemple la répartition des étiquettes DPE sur tous les datasets DPE
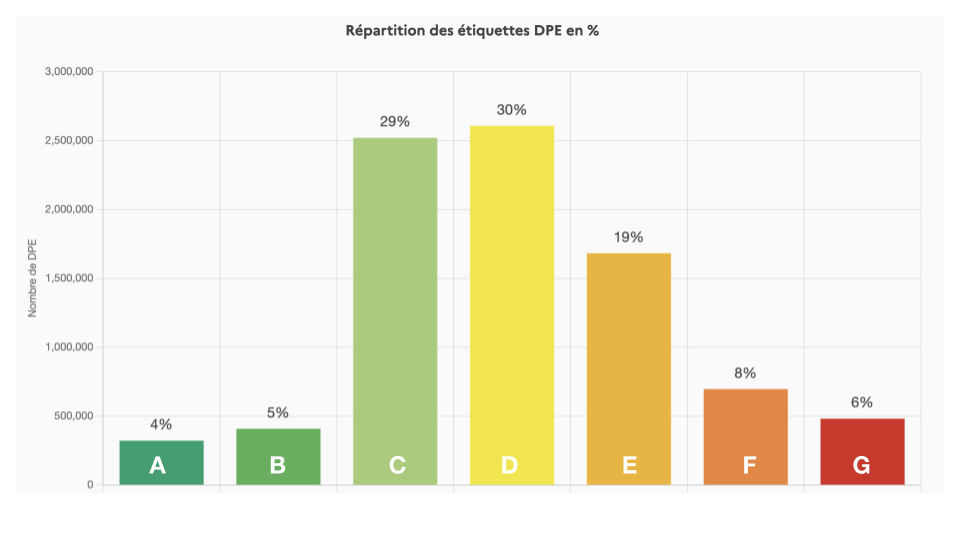
On observe que les classes C et D, aspirent la plupart des étiquettes DPE. Les catégories sont fortement déséquilibrées.
Que prédire, étiquettes DPE ou GES ?
Le dataset offre 2 variables cibles possibles : l’étiquette DPE et l’étiquette GES. Toutes 2 prennent des valeurs entre A, B, C, D, E, F et G. Prédire l’une de ces variables correspond donc à un problème de classification multiclasse.
Avant juillet 2021, le DPE d’un logement était représenté par deux étiquettes
- énergie (consommation en énergie primaire)
- et climat (émissions de gaz à effet de serre, GES).
Ces deux étiquettes ont ensuite été combinées en une seule étiquette de performance énergétique : l’étiquette DPE. Cependant, l’étiquette GES (climat) est toujours présente pour informer sur l’empreinte carbone des logements.
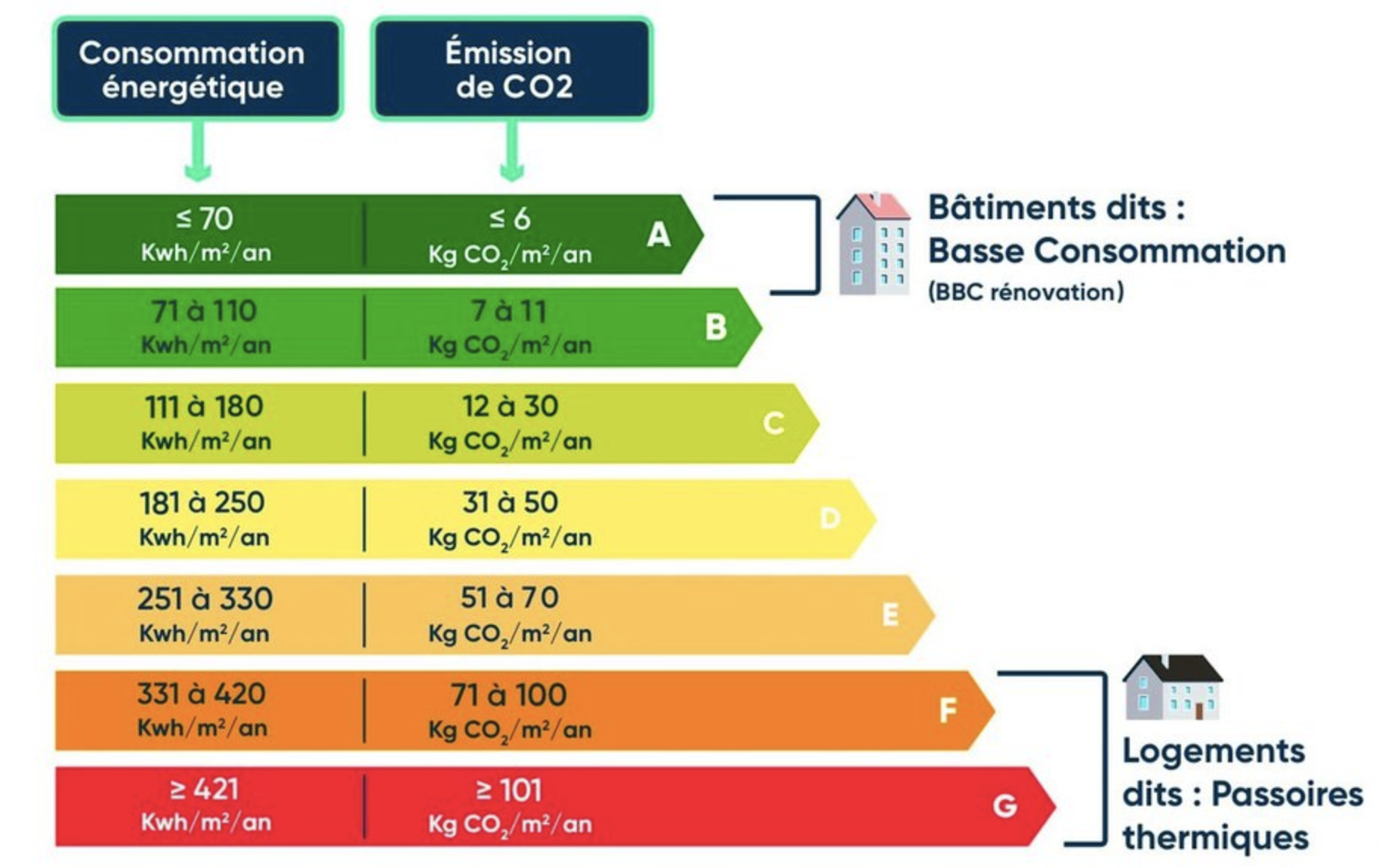
Pour obtenir une étiquette DPE donnée, un logement doit respecter un seuil minimal en consommation d’énergie primaire et en émissions de GES, exprimées respectivement en kWhEP/m²/an et kgCO2eq/m²/an.
Ce graphique indique les seuils limites d’émission et de consommation pour chaque étiquette DPE
Explorez les données
Pour télécharger le jeu de données, vous pouvez le faire à partir du site ou télécharger le dataset directement depuis cette url.
Dans les deux cas, Le fichier obtenu est dpe-v2-tertiaire-2.csv.
Chargez ce fichier ensuite ce fichier dans un dataframe pandas avec :
import pandas as pd
data = pd.read_csv("dpe-v2-tertiaire-2.csv")
La dataframe a 10.000 échantillons pour 63 variables.
A vous :
Téléchargez le dataset de 10.000 échantillons au format csv, ouvrez un notebook Jupyter et commencez à l’explorer : données manquantes, données aberrantes (outliers), corrélation entre les variables, …
- Combien d'échantillons n'ont pas de d'étiquette ?
- Quels sont les types d'usages (type_usage_energie_n_1, ) et de chauffages ?
- Quel est la part respective des differents mode de chauffage ?
- Quelles sont les valeurs des autres variables de catégories ?
- Y a t il des valeurs aberrantes en terme de consommation ou d'émissions GES ?
- Les émissions GES sont-elles trop corrélées avec les étiquettes GES ou DPE?
- Comment ont évolué les DPE au fil des années ?
Conclusion
Ce premier chapitre nous a permis de nous familiariser avec le dataset DPE tertiaire de l’ADEME en faisant ressortir certains problèmes tant sur la forme que sur le fond. Un bon tiers des variables cibles ne sont pas renseignées, il y a des fuites d’information entre les variables de consommation et les cibles, les colonnes ont des noms compliqués et certaines catégories sont minoritaires (chauffage au bois ou usage de climatisation par exemple).
Dans le prochain chapitre, nous allons constituer une version propre de ce dataset et entraîner un modèle simple de Random Forest dans un notebook Jupyter qui nous servira de base de départ à la mise en production progressive du modèle.