MLOps DPE - Chapitre 3: du notebook au scripts sur github
Dans ce chapitre, vous allez transformer le notebook du chapitre précédent en une repository structurée de script python et inclure les premiers fichiers utiles à sa compréhension et à son utilisation que sont le README et un .gitignore. Vous publierez ensuite votre programme sur github après avoir créé une clé ssh d'authentification.
Plan du chapitre
Ressources
Démarrer avec :
git fetch chapitre_03
git checkout chapitre_03
Comment améliorer son code ?
Comme nous l’avons vu au chapitre précédent, le notebook Jupyter n’est pas adapté à un environnement de production. Il nous faut transformer ce notebook en une collection de scripts python plus structurée. L’objectif est d’avoir un code qui soit versionné, sans bug, facile à faire évoluer et compréhensible par d’autres personnes que vous. Pour cela nous allons suivre certains principes qui permettent d’améliorer la qualité du code.
Écrire un code de qualité, c’est vraiment pas compliqué ! Il suffit simplement d’appliquer les principes suivants : KISS, YAGNI, DRY, GRASP et SOLID ! En voilà des acronymes sympa !
Bon, évidemment si écrire du code lisible et efficace était si facile nous n’aurions pas besoin de tous ces concepts. Mais à quoi reconnait-on du bon code ? Simplement, à du code compréhensible, facilement modifiable, maintenable et bien sur sans bug.
Pour ma part j’ai retenu les quelques idées simples que voici :
SRP ou le principe de responsabilité unique
Chaque élément de code doit être dédié à une seule chose, un but unique. Cela s’applique à tous les niveaux : classes, fonctions, script, ligne, cellule de notebook, etc. On évite ainsi les fonctions qui font des centaines de lignes, les classes trop abstraites ou polymorphes et les lignes de code trop futées et inextricablement illisibles.
Illustrations :
- Vous chargez les données et les modifiez dans la même fonction. Il vaut mieux séparer le chargement à proprement parler des données et de leur modification en 2 fonctions:
- Vous filtrez une dataframe avec une condition. Par exemple
df = df[(df.chauffage == 'bois') & (df.code_postal == '61550') & (df.age_du_capitaine > 50)]Séparer la définition de la condition du filtrage facilite la lecture et les modifications ultérieures.
condition = (df.chauffage == 'bois') & (df.code_postal == '61550') & (df.age_du_capitaine > 50) df = df[condition]
En d’autres termes, le principe de responsabilité unique (SRP) signifie qu’une classe, fonction ou ligne de code ne doit avoir qu’une seule tâche, afin d’avoir un code clair, modulaire et facile à maintenir.
DRY ou “Don’t Repeat Yourself”
En français : “éviter les répétitions”.
Chaque fonctionnalité ou bloc de code ne doit être écrit qu’une seule fois. Éviter de dupliquer le code permet de centraliser les modifications. Cela réduit le risque d’en oublier une partie et rends le code plus lisible et maintenable.
YAGNI ou “You ain’t gonna need it”
En français on peut traduire YAGNI par “laisse tomber, t’en auras pas besoin”.
YAGNI ça sonne bien. YAGNI c’est cool. YAGNI !
YAGNI stipule de n’écrire que du code réellement nécessaire sans anticiper sur les fonctionnalités ou les optimisations qui pourrais survenir et dont nous imaginons l’utilité à tort ou à raison. En réalité, ce bout de code prévisionnel ne sera probablement jamais utilisé, car le design du code, le besoin du produit ou le contexte du projet changera avant. Ajouter du code qui sera potentiellement utile, rajoute du bruit et de la complexité.
KISS ou “keep it simple stupid !”
Le principe de base de tout bon code : fais simple !
On rencontre souvent du code inutilement savant, du code pédant. Une ratatouille de classes, une bouillabaisse de fonctions, une paella d’astuces pour ce qui pourrait être écrit en quelques lignes de code. Faite simple ! Privilégiez la lisibilité sur la complexité et n’utilisez les abstractions orienté objet que si celles-ci apportent vraiment quelque chose.
Bien nommer et bien tester
A ces principes de base, je rajouterai 2 points
-
Veillez à bien nommer les éléments du code (variables, méthodes, fonctions, classes, etc). L’abréviation qui vous semble évidente aujourd’hui vous sera totalement cryptique dans quelques mois.
-
Prenez le temps d’écrire des tests. L’écriture de test n’est pas dans le scope du projet MLOps-DPE c’est pourquoi je n’en parlerai pas ici. Mais l’écriture de tests unitaire ou fonctionnel est une composante primordiale du code en production. Pour démarrer, rajoutez un simple
assertau fil du code pour valider par exemple que les variables ont la bonne valeur, que le fichier existe ou que les data sont valides. Une fois confortable avec ces verifications vous pourrez plus facilement passer a l’ecriture de tests ave pytest.
Ceci dit, la bande à GPT (Copilot, Claude, chatGPT 40 etc) fait un excellent boulot pour écrire les tests d’une classe donnée.
Pour qui code-t-on ?
En fait, l’idée principale derrière tous ces beaux principes, est que vous ne codez plus pour vous, mais bien pour celle ou celui qui viendra après vous et qui devra comprendre ce que vous faites. Non seulement ce que le code fait, mais aussi sa logique, ses patterns, etc. Facilitez donc la vie de votre alter ego en écrivant un code simple, modulaire, explicite.
Vous pourriez m’objecter que vous serez le ou la seul(e) à travailler sur le projet MLOps-DPE en question. Certes ! Mais comme l’a dit le génial DHH, créateur de Ruby on Rails lors d’une conférence, (je paraphrase) : as soon as it is written your code becomes legacy. Soit “Votre code devient hérité / vieux dès qu’il est écrit”. Même lorsque vous en êtes l’unique héritier. Celui ou celle qui devra se plonger dans vos écritures dans quelques mois, c’est vous. Alors autant faciliter le travail à votre futur self et tout bien organiser dès maintenant.

Pour conclure ce paragraphe, il me semble que la difficulté qu’il y a à écrire du bon code est cette recherche constante d’un juste équilibre entre clarté et concision. D’une part, la lisibilité du code demande plus de code et du code moins dense ; une ligne ou une fonction par opération. D’autre part, moins il y a de code moins il y a de bug ; donc pas besoin d’une soupe de classes pour ouvrir un fichier.
A vous : Avant de regarder le code du chapitre (branche chapitre 3 du github), prenez votre notebook et transformez-le en code structuré avec un fichier contenant une classe pour la transformation des données et un autre pour entraîner le modèle.
Quelle structure pour le projet ?
Commençons donc par la structure du projet. Comment organiser les fichiers ?
Il n’y a pas de recette surprise ni de standard universel. L’important est de pouvoir séparer les éléments logiquement de façon à pouvoir vous y retrouver rapidement et à pouvoir facilement importer les classes entre les fichiers.
Un autre principe est de séparer les rôles de chaque fichier. Quelqu’un doit pouvoir voir l’arborescence de votre projet et comprendre d’un coup d’œil ou sont les choses.
Importer les classes de fichiers en fichier n’est pas toujours si facile en python surtout si les fichiers sont dans des répertoires différents. Cela peut rapidement devenir un casse-tête. Voir ce fil sur Stackoverflow : Importing files from differemt folder.
Voici donc un exemple d’architecture de code avec 2 répertoires:
- /src : pour les scripts python
- features.py : charger, nettoyer, simplifier et transformer les données
- train.py: entrainer une random forest sur ces données
- /data : pour les données
et il en viendra d’autres au fil du projet :
- test,
- shell,
- sql
Scinder le notebook en plusieurs fichiers python
Le plus simple est de scinder le notebook en 2 fichiers principaux, features.py et train.py responsables respectivement de 1) la préparation des données et 2) de l’entraînement du modèle.
On rajoutera si besoin un fichier de fonctions utiles que l’on nommera ‘utils.py’ et qui sera importé.
Car il faut aussi pouvoir lire les données brutes, les écrire une fois numérisées et charger cette dernière version pour entraîner le modèle.
On pourra ensuite exécuter ces scripts en ligne de commande avec
> python src/features.py
> python src/train.py
Chaque script contient une classe et une fonction main() pour exécuter le processus voulu une fois la classe instanciée.
En ce qui concerne le code des features.py et train.py, Il n’y a rien de spécial dans ces classes qui ne soit pas évident en regardant le code disponible dans la repo github. L’important est que nous ayons bien séparé les rôles de chaque classe et chaque script. Un pour les données et un pour le modèle.
Le processus est séquentiel comme dans le notebook. Mais on peut d’ors et déjà rendre les 2 étapes indépendantes en veillant à sauvegarder leur output avec une version. On a donc:
TODO: insert process avec outputs
De cette façon lorsque l’on modifie quelque chose dans la façon de traiter les données on fait en sorte de versionner le dataset numérisé et d’utiliser cette version pour l’entraînement du modèle. On peut imaginer enregistrer ces setup successifs dans un fichier de config.
Traçabilité
Pour obtenir de la traçabilité et etre capable de reprendre des resultats precedents on peut le faire manuellement en tenant en quelque sorte un jourrnal de bord des experiences. On peut aussi utiliser des plateformes adaptées de type wandb ou MLflow. Nous verrons MLFlow dans un chapitre ultérieure.
On touche là du doigt le besoin d’attribuer une version à chaque version du dataset. Celui initial et brute et des versions en fonction des expériences, des essais que l’on fait.
De même les paramètres du modèle voir le choix modèle lui-même vont varier au fur et à mesure des expériences.
Pour éviter le syndrome du fichier nommé final prématurément, il faudra donner une version spécifique à ces éléments au fil des expériences et modifications.
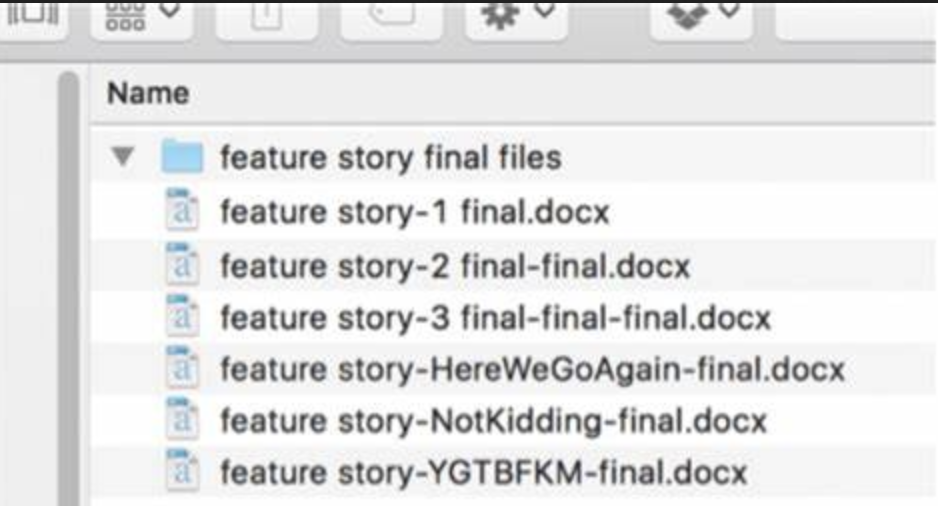
Un exemple du code complet et structuré se trouve sur la branche chapitre 3 du github.
Conclusion
Nous sommes passés d’un notebook Jupyter à un début d’organisation non seulement du code et des données, mais surtout de la structure de votre code qui permet à vous et à d’autres de travailler, utiliser voir contribuer à ce projet. Le point important à retenir au-delà des aspects techniques et que vous écrivez votre code pour quelqu’un d’autre (ou pour vous-mêmes dans quelques mois ce qui revient au même).
Organiser votre code va de pair avec organiser et à versionner les données et les modèles.
Dans le prochain chapitre, nous allons passer a l’etape suivante pour le travail collaboratif en publiant le code dans un dépot github.
Note: en anglais on parle de repository qui a ete malheureusement traduit en français par dépot. Mais comme souvent avec les traductions françaises de termes techniques anglais le sens est perdu. Un depot evoque un sédiment due a une accumulation ou un entrepot donc un truc oublié auquel on ne touche pas ou peu. Donc rien à voir avec l’idée de travail collaboratif autour d’un code en evolution constante. Dans la suite j’utiliserai plutôt le terme anglais de repository ou son abreviation repo.
plus loin dans cette organisation et stabilisation de votre code en travaillant sur le format, la qualité du code et l’environnement d’exécution.