MLOps DPE - Chapitre 4: Git git git github
Dans ce chapitre, vous publierez ensuite votre programme sur github après avoir créé une clé ssh d'authentification.
Plan du chapitre
Ressources
- github branche chapitre_3
- Colab du notebook
- KISS, YAGNI, DRY et SOLID
- Créez une repo github
- SSH avec authentification par clés
- Principales commandes git
git fetch chapitre_03
git checkout chapitre_03
Comment améliorer son code ?
Comme nous l’avons vu au chapitre précédent, le notebook Jupyter n’est pas adapté à un environnement de production. Il nous faut transformer ce notebook en une collection de scripts python plus structurée. Le but est d’avoir un code qui soit versionné, sans bug, facile à faire évoluer et compréhensible par d’autres personnes que vous. Pour cela nous allons suivre certains principes qui permettent d’améliorer la qualité du code.
Écrire un code de qualité, c’est vraiment pas compliqué ! Il suffit simplement d’appliquer les principes suivants : KISS, YAGNI, DRY, GRASP et SOLID ! En voilà des acronymes sympa !
Bon, évidemment si écrire du code lisible et efficace était si facile nous n’aurions pas besoin de tous ces concepts. Mais à quoi reconnait-on du bon code ? Simplement, à du code compréhensible, facilement modifiable, maintenable et bien sur sans bug.
Pour ma part j’ai retenu les quelques idées simples que voici :
SRP ou le principe de responsabilité unique :
Chaque élément de code doit être dédié à une seule chose, un but unique. Cela s’applique à tous les niveaux : classes, fonctions, script, ligne, cellule de notebook, etc. On évite ainsi les fonctions qui font des centaines de lignes, les classes trop abstraites ou polymorphes et les lignes de code trop futées et inextricablement illisibles.
Illustrations :
- Vous chargez les données et les modifiez dans la même fonction. Il vaut mieux séparer le chargement à proprement parler des données et de leur modification en 2 fonctions:
- Vous filtrez une dataframe avec une condition. Par exemple
df = df[(df.chauffage == 'bois') & (df.code_postal == '61550') & (df.age_du_capitaine > 50)]Séparer la définition de la condition du filtrage facilite la lecture et les modifications ultérieures.
condition = (df.chauffage == 'bois') & (df.code_postal == '61550') & (df.age_du_capitaine > 50) df = df[condition]
En d’autres termes, le principe de responsabilité unique (SRP) signifie qu’une classe, fonction ou ligne de code ne doit avoir qu’une seule tâche, afin d’avoir un code clair, modulaire et facile à maintenir.
DRY ou “Don’t Repeat Yourself”
En français : “éviter les répétitions”.
Chaque fonctionnalité ou bloc de code ne doit être écrit qu’une seule fois. Éviter de dupliquer le code permet de centraliser les modifications. Cela réduit le risque d’en oublier une partie et rends le code plus lisible et maintenable.
YAGNI ou “You ain’t gonna need it”
En français on peut traduire YAGNI par “laisse tomber, t’en auras pas besoin”.
YAGNI ça sonne bien. YAGNI c’est cool. YAGNI !
YAGNI stipule de n’écrire que du code réellement nécessaire sans anticiper sur les fonctionnalités ou les optimisations qui pourrais survenir et dont nous imaginons l’utilité à tort ou à raison. En réalité, ce bout de code prévisionnel ne sera probablement jamais utilisé, car le design du code, le besoin du produit ou le contexte du projet changera avant. Ajouter du code qui sera potentiellement utile, rajoute du bruit et de la complexité.
KISS ou “keep it simple stupid !”
Le principe de base de tout bon code : fais simple !
On rencontre souvent du code inutilement savant, du code pédant. Une ratatouille de classes, une bouillabaisse de fonctions, une paella d’astuces pour ce qui pourrait être écrit en quelques lignes de code. Faite simple ! Privilégiez la lisibilité sur la complexité et n’utilisez les abstractions orienté objet que si celle ci apportent vraiment quelque chose.
A ces principes de base pour guider votre écriture, je rajouterai 2 points
-
Veillez à bien nommer les éléments du code (variables, méthodes, fonctions, classes, etc). L’abréviation qui vous semble évidente aujourd’hui vous sera totalement cryptique dans quelques mois.
-
Prenez le temps d’écrire des tests. L’écriture de test n’est pas dans le scope du projet MLOps-DPE c’est pourquoi je n’en parlerai pas ici. Mais l’écriture de tests unitaire ou fonctionnel est une composante primordiale du code en production. Pour démarrer, rajoutez un simple
assertau fil du code pour valider par exemple que les variables ont la bonne valeur, que le fichier existe ou que les data sont valides.
En fait, l’idée principale derrière tous ces beaux principes, est que vous ne codez plus pour vous, mais bien pour celle ou celui qui viendra après vous et qui devra comprendre ce que vous faites. Non seulement ce que le code fait, mais aussi sa logique, ses patterns, etc. Facilitez la vie de votre alter ego en écrivant un code simple et propre.
Vous allez m’objecter que vous serez le seul à travailler sur le projet MLOps-DPE en question. Certes ! Mais comme l’a écrit DHH, créateur de Ruby on Rails, (je paraphrase) : as soon as it is written your code becomes legacy code. Votre code devient hérité dès qu’il est écrit même lorsque vous en êtes l’héritier. Celui ou celle qui devra se plonger dans vos écritures dans quelques mois, c’est vous. Alors autant faciliter le travail à votre futur self et tout bien organiser dès maintenant.

Pour conclure ce paragraphe, il me semble que la difficulté d’écrire du bon code est cette recherche constante d’un juste équilibre entre concision et clarté. D’une part, la lisibilité du code prône sur sa densité ; une ligne ou une fonction par opération. D’autre part, moins il y a de code moins il y a de bug ; pas besoin d’une soupe de classes pour ouvrir un fichier.
A vous : Avant de regarder le code du chapitre (branche chapitre 3 du github), prenez votre notebook et transformez-le en code structuré avec un fichier contenant une classe pour la transformation des données et un autre pour entraîner le modèle.
Quelle structure pour le projet ?
Commençons donc par la structure du projet. Comment organiser les fichiers ?
Il n’y a pas de recette surprise ni de standard universel. L’important est de pouvoir séparer les éléments logiquement de façon à pouvoir vous y retrouver rapidement et à pouvoir facilement importer les classes entre les fichiers.
Un autre principe est de séparer les rôles de chaque fichier. Quelqu’un doit pouvoir voir l’arborescence de votre projet et comprendre d’un coup d’œil ou sont les choses.
Importer les classes de fichiers en fichier n’est pas toujours si facile en python surtout si les fichiers sont dans des répertoires différents. Cela peut rapidement devenir un casse-tête. Voir ce fil sur Stackoverflow : Importing files from differemt folder.
Voici donc un exemple d’architecture de code avec 2 répertoires:
- /src : pour les scripts python
- features.py : charger, nettoyer, simplifier et transformer les données
- train.py: entrainer une random forest sur ces données
- /data : pour les données
et il en viendra d’autres au fil du projet : test, shell, sql etc
On exécutera les scripts en ligne de commande avec
> python src/features.py
> python src/train.py
Chaque script contient une classe et une fonction main() pour exécuter le processus voulu une fois la classe instanciée.
Il n’y a rien de spécial dans ces classes qui ne soit pas évident en regardant le code disponible dans la repo github. L’important est que nous ayons bien séparé les rôles de chaque classe et chaque script. Un pour les données et un pour le modèle.
Il faut aussi pouvoir lire les données brutes, les écrire une fois numérisées et charger cette dernière version pour entraîner le modèle. On touche là du doigt le besoin d’attribuer une version à chaque version du dataset. Celui initial et brute et des versions en fonction des expériences, des essais que l’on fait. De même les paramètres du modèle voir le choix modèle lui-même vont varier au fur et à mesure des expériences.
Pour éviter le syndrome du fichier nommé final prématurément, il faudra donner une version spécifique à ces éléments au fil des expériences et modifications.
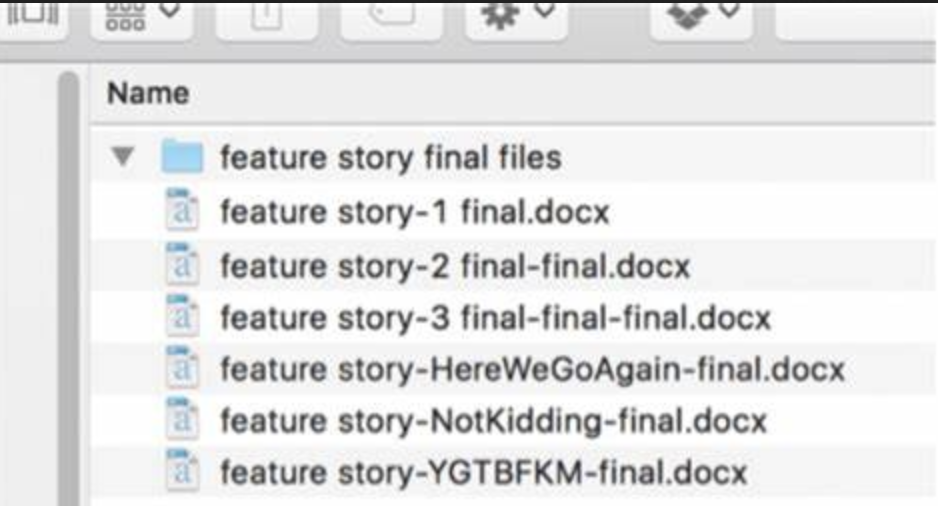
Un exemple du code complet et structuré se trouve sur la branche chapitre 3 du github.
Git, Gitlab ou Github ?
Le protocole GIT transforme un programme en outil de travail collaboratif. C’est le logiciel de version le plus utilisé depuis 2010. Il a été développé en quelques semaines en 2005 par Linus Torvald lui-même.
Git permet à des développeurs de copier la version officielle du code, puis de travailler en parallèle sur leurs évolutions respectives et enfin de fusionner leurs modifications dans cette même version centralisée de départ. On parle de branches pour chaque version du code et de merge pour la fusion de deux branches.
Quand on travaille à plusieurs sur une même base de code (codebase) avec git, le principe est de créer une branche par fonctionnalité et de régulièrement mettre à jour cette branche de façon à intégrer les modifications des autres développeurs. On parle de rebase pour mettre à jour sa branche par rapport à la branche principale.
Github ou GitLab ? J’ai demandé à notre ami chatGPT ce qu’il en pensait. Résume en quelques lignes les avantages respectifs de gitlab et de github. En résumé, GitLab est plus orienté opensource et offre un niveau de contrôle d’accès plus granulaire, tandis que github est plus répandu et facile d’utilisation. Dans le cadre du projet MLOps-DPE cela ne changera rien, vous pouvez utiliser l’un ou l’autre.
Comment évolue le code ?
Au point de vue projet, on considère 3 stades dans la composition du code en fonction de sa maturité :
-
développement ou dev : la branche principale qui concentre les évolutions du code de base. C’est vis-à-vis de cette branche que les développeurs fusionnent / mergent leurs modifications (features)
-
staging : une fois les modifications mergées dans la branche de développement, le code est intégré dans un environnement dit de staging qui reflète le plus possible l’environnement de production. Des tests permettent de vérifier de la non-régression du code. Cette étape permet aussi aux product people de vérifier l’adéquation entre les fonctionnalités attendues et celles réellement implementées.
-
production: une fois l’étape de staging satisfaite, le code est déployé en production. La branche de production est appelée main ou master.
Le code vit donc sur 2 ou 3 branches : dev, staging et production.
Il est bien plus facile de fusionner un petit bout de code qu’une modification importante qui impacte plusieurs fichiers. Et fusionner régulièrement sans attendre que la branche principale ait beaucoup évolué évite de toujours devoir rattraper le code des autres.
En règle générale, faire des commits petit, concis, cohérent et explicite, facilite la vie.
Ouvrir un compte github
A vous : Pour mettre votre code sur github, il vous faut ouvrir un compte github (ou gitlab, aucune importance à ce stade) qui est gratuit
- - Allez sur github.com/new
- Renseignez le nom de votre repo et une description
- Sélectionnez le mode "Private"
- Ne rajoutez pas les autres fichiers (readme, .gitignore), nous nous en chargerons
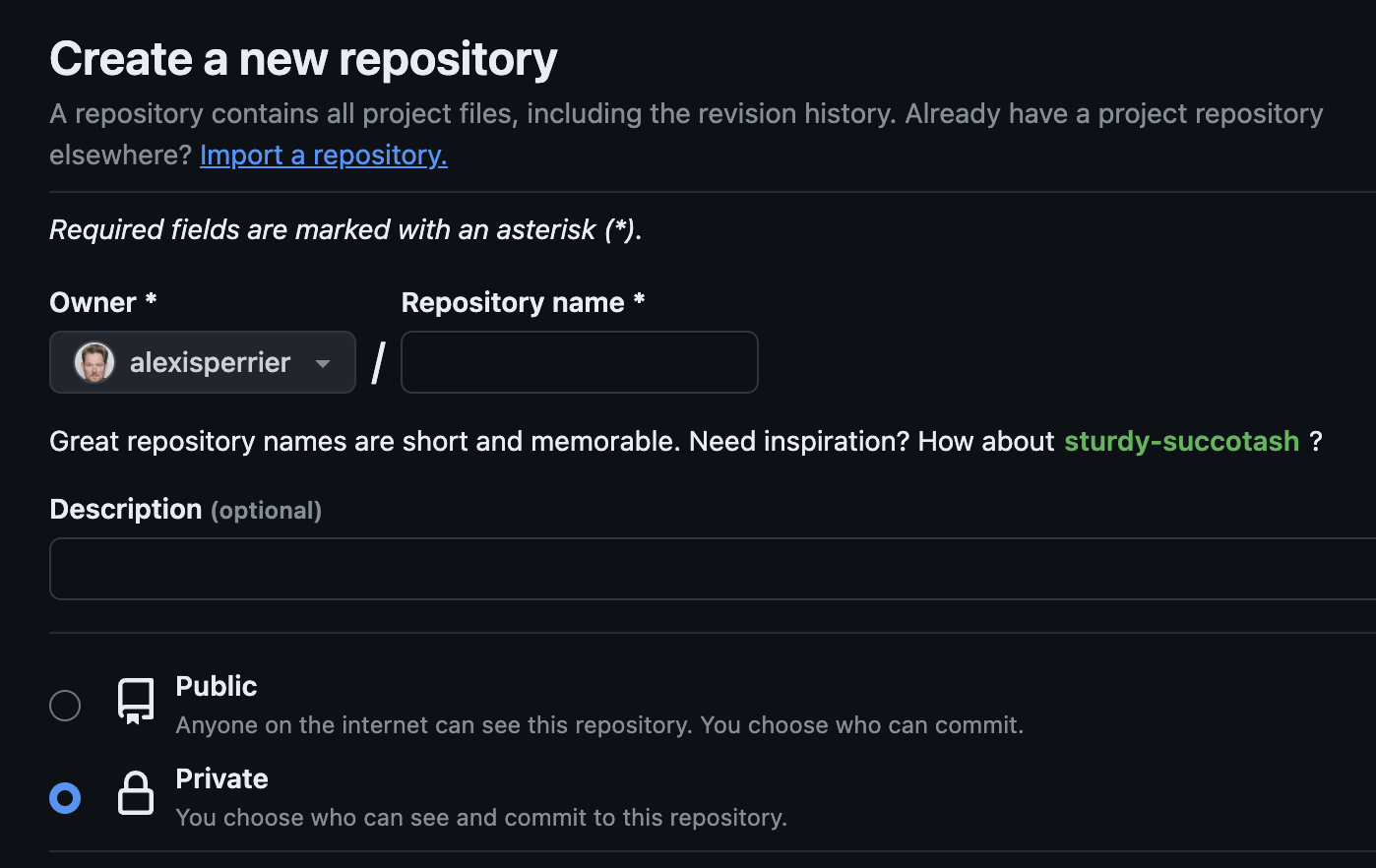
Github montre 2 façon d’initialiser votre nouvelle repo avec du code, la longue et la courte .
Voici un exemple d’instructions pour une repo localement vide
echo "# le nom de la repo" >> README.md
# initialiser git dans le repertoire du projet
git init
# ajouter le fichier
git add README.md
# premier commit
git commit -m "first commit"
# renommer la branche master en main
git branch -M main
# lier le git local avec le git sur github
git remote add origin [email protected]:{repository_id}
# pousser le premier commit
git push -u origin main
et voici la version pour un code qui existe déjà en local :
git init
# ajouter les fichiers existant
git add .
# premier commit
git commit -m "first commit"
# lier le git local avec le git sur github
git remote add origin [email protected]:{repository_id}
# renommer la branche master en main
git branch -M main
# pousser le premier commit
git push -u origin main
où repository_id est le nom de votre compte github et de la repository. Pour le github du projet MLOps-DPE, le repository_id est : SkatAI/MLOps-DPE.git
Comme vous avez déjà du code en local, la version courte suffit.
Voici les commandes à effectuer en ligne de commande
git remote add origin [email protected]:<nom_de_votre_compte_github>/<nom_de_votre_repo>.gitremplacez par votre nom de compte github et votre repogit branch -M main(optionnel, pour renommer la branche principale de master à main)git push -u origin main
main ou master ? main semble être devenue le nouveau nom par défaut de la branche principale d’une repo git. Franchement cela ne change rien, ce n’est qu’une convention et vous pourriez nommer votre branche principale, maître ou gargamel, si vous préférez. Mais pour simplifier les choses on utilisera le nom main dans la suite du projet.
Mais avant de sauter sur ces lignes, il vous faut montrer patte blanche (vous authentifier) à github en créant une clé SSH.
Récapitulatif SSH
Selon wikipédia : Avec SSH, l’authentification peut se faire sans l’utilisation de mot de passe ou de phrase secrète en utilisant la cryptographie asymétrique. La clé publique est distribuée sur les systèmes auxquels on souhaite se connecter. La clé privée, qu’on prendra le soin de protéger par un mot de passe, reste uniquement sur le poste à partir duquel on se connecte.
Une clé SSH est donc composée de 2 parties : une publique et une privée. Vous gardez la partie privée sur votre ordinateur et surtout vous ne la divulguez jamais.
La partie publique permet aux services externes de matcher avec votre clé privée. C’est cette partie publique que vous mettrez sur github. Mais il ne faut pas non plus la divulguer sinon quelqu’un d’autre peut se faire passer pour vous.
Pour créer une clef SSH sur mac, dans un terminal
ssh-keygen -t ed25519 -C "votre adresse email"
Il n’y a pas besoin de saisir de mot de passe. Si c’est votre première clé, acceptez les noms de fichiers par défaut. Le processus de création va créer 2 fichiers dans le répertoire ~/.ssh : id_rsa (la clé privée) et id_rsa.pub la clé publique.
Il vous faut ensuite activer la clé avec
eval "$(ssh-agent -s)"
Vous allez maintenant copier votre clé publique sur github
cd ~/.ssh
Copiez la clé manuellement avec vim id_rsa.pub ou directement dans le terminal avec pbcopy id_rsa.pub
Sur github allez en haut à droite dans votre photo / avatar et tout en bas du menu déroulant cliquez sur settings :
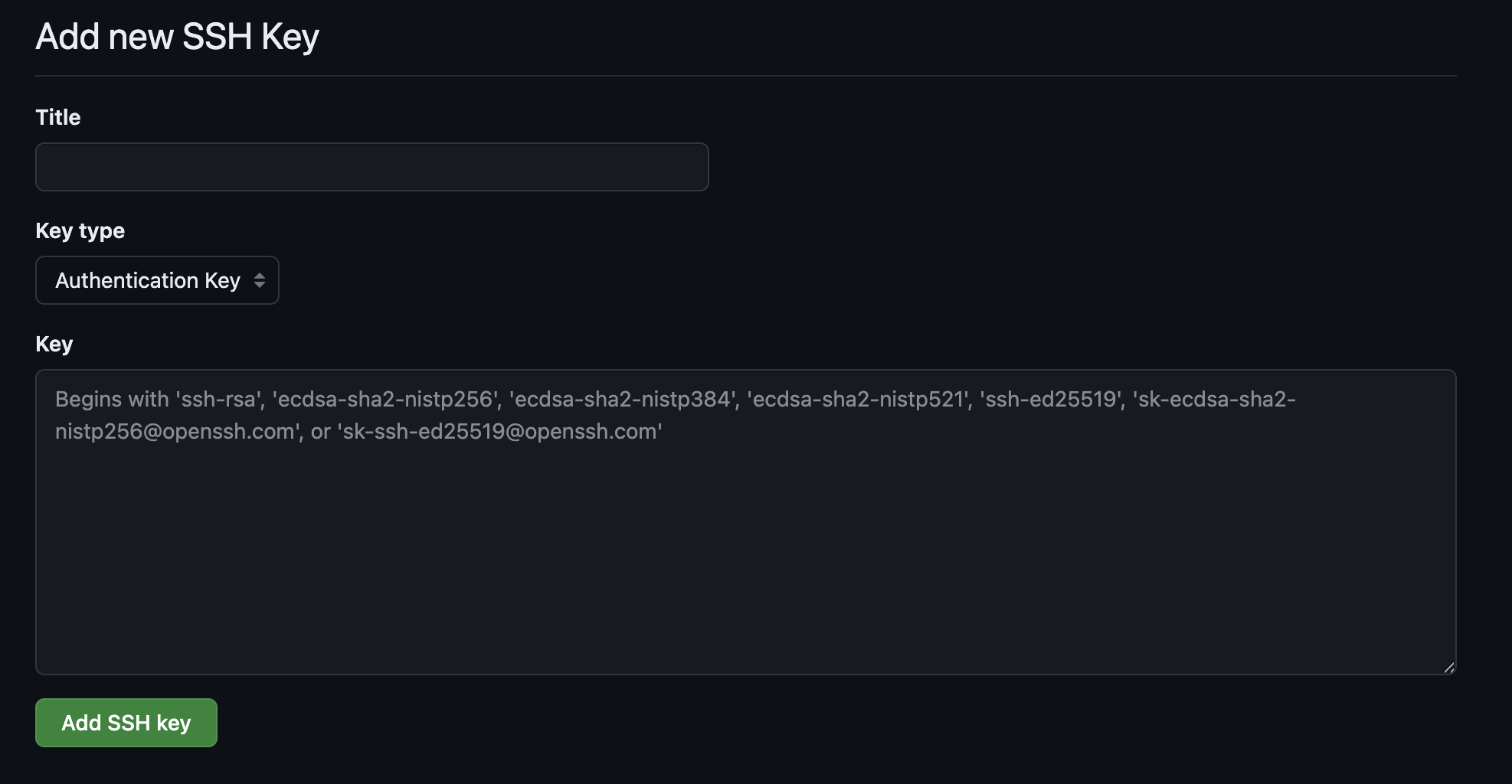
à gauche maintenant de l’écran, cliquez sur SSH and GPG keys :

Puis cliquez sur new ssh key (pas new gpg key)
Donnez un nom à cette clé et dans la case principale Key copiez votre clé publique
Maintenant pour tester que votre clé a bien été prise en compte, retournez sur votre répertoire local et exécutez
git push -u origin main
Bravo !
Quelques commandes git
Dans le projet MLOps-DPE, vous travaillez a priori seul. Vous n’aurez donc pas besoin de fusionner votre code avec celui d’autres devs. Si vous travaillez sur la branche main, les seules commandes sont les mêmes à chaque fois que vous modifiez votre code:
git add .pour ajouter tous les fichiers que vous venez de modifier. (attention, il y a un point aprèsadd)git commit -m "un message de description du commit"pour commiter les fichiers en question en décrivant la nature de vos changements.git push origin mainpour envoyer le code sur github
Github dans le cas d’un travail en solitaire sert plutôt de simple sauvegarde et ne remplit pas son potentiel de plateforme de travail collaboratif.
3 points :
- mon message de commit le plus courant est “wip” pour work in progress (travaux en cours) surtout lorsque l’on travaille en solitaire. A éviter en collaboratif.
- vous pouvez ajouter non pas tous les fichiers modifiés, mais les fichiers un à un en spécifiant le nom du fichier dans la commande de façon à bien séparer vos modifications :
git add <nom du fichier> - pour tirer (cad mettre à jour votre copie locale du code ) le code qui est sur github, la commande est :
git pull origin main
Votre code est donc maintenant sur github. Prenez quelques moments pour vous familiariser avec ces commandes.
Vous trouverez un excellent résumé des principales commandes git sur cette page github-git-cheat-sheet.
Le Readme
Lorsque vous allez sur une librairie ou un programme public sur github, la première chose que vous voyez est le fichier README qui constitue la première page de la repo. Littéralement, readme veut dire lis moi. direct!
Le readme est le premier fichier que vos utilisateurs et vos développeurs contributeurs voient quand ils découvrent votre projet. C’est un guide, une description de votre travail qui indique quoi attendre du projet et comment le faire fonctionner.
Un bon readme contient au minimum les éléments suivants
- le titre de votre projet
- la description du projet, ce que le code fait, le stack technique utilisé
- Comment installer et executer votre projet
Et aussi, si votre projet est conséquent et mure
- comment exécuter les tests
- comment contribuer au projet
- la liste des contributeurs
- les badges de qualité comme pylint ou ded _test coverage)_
En résumé, le readme explique comment prendre en main le projet.
Le readme est au format markdown. Il est écrit dans un fichier nommé readme.md situé à la racine du projet.
A vous, lisez les readme de certaines repo comme category encoders, scikit-learn, ou celui plus long de la librairie transformers de huggingface. Le contenu varie, mais le but est toujours de présenter et d’aider à la prise en main du module.
Le fichier .gitignore
Comme son nom l’indique, le fichier .gitignore liste les fichiers qui ne doivent pas se retrouver sur github.
Il y en a de 3 types
-
De loin les plus importants, les fichiers secrets qui contiennent des clés API ou des mots de passe. Même si votre github est privé, il y a un risque que vos secrets soient dérobés. Avec comme possible scénario catastrophe que quelqu’un se connecte à votre compte AWS, Azure ou GCP et se lance dans le bitcoin mining avec vos économies ou celle de votre entreprise.
-
Les fichiers trop volumineux. Tout ce qui est fichier data, logs et les modèles qui dépassent souvent les 10aine de méga. Github a une limite à 100 Mb par fichier (50 Mb génère un avertissement), mais c’est une limite maximum. Et devoir enlever un fichier trop volumineux déjà comité est une sombre galère.
-
Les fichiers de bruits comme les fichiers cachés .DS_store sur mac ou les répertoires pychache qui sont créés à chaque importation des modules python. Aucune raison de les retrouver sur votre github.
Vous êtes libres d’ajouter les fichiers que vous souhaitez.
Voici un exemple de .gitignore :
# Ignored Directories
data/
.ipynb_checkpoints/
# Ignored File Types
*.pdf
*.csv
*.xlsx
*.pkl
*.json
*.log
*.zip
*.tar.gz
# Ignored Python Files
__pycache__/
*.pyc
*.pyo
*.pyd
# Ignored Configuration Files
.env
.vscode/
# Ignored Miscellaneous Files
.DS_Store
Thumbs.db
Conclusion
Nous sommes passés d’un notebook Jupyter à un début d’organisation non seulement du code et des données, mais surtout de la structure de votre code qui permet à vous et à d’autres de travailler, utiliser voir contribuer à ce projet. Le point important à retenir au-delà des aspects techniques et que vous écrivez votre code pour quelqu’un d’autre (ou pour vous-mêmes dans quelques mois ce qui revient au même).
Organiser votre code va de pair avec organiser et à versionner les données et les modèles.
Dans le prochain chapitre nous allons plus loin dans cette organisation et stabilisation de votre code en travaillant sur le format, la qualité du code et l’environnement d’exécution.